 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多


新发布的 RedisGraph 2.0 模块带来了一系列改进,包括增强的 Cypher 支持、全文搜索,并且支持图形可视化。但同样重要的是,最新版本的 RedisGraph 提供了显著的性能改进:延迟最多提高 6 倍,吞吐量最多提高 5 倍。 让我们来看看这些性能提升以及用于演示它们的基准测试。
早在 2018 年 11 月我们发布 RedisGraph 1.0 时,我们就分享了基于k-hop 邻域计数查询的基准测试结果。 新的 RedisGraph 2.0 包含新的特性和功能,这些特性和功能支持更全面的测试套件,例如链接数据基准委员会 (LDBC) 提供的那些——更多内容见下文。 但我们仍然依赖 k-hop 基准测试来比较 RedisGraph 2.0 与 v1.2。
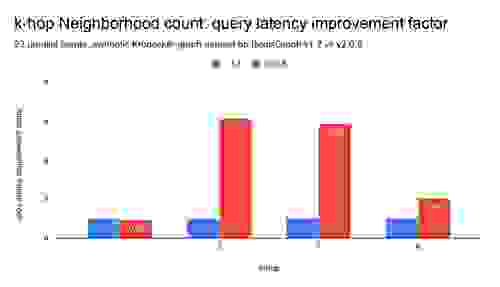
K-hop 邻域计数查询是一个图形局部查询,它计算单个起始节点(种子)在特定深度连接到的节点数,并且仅计算k-hop 距离的节点, 如下图所示:

K-hop 邻域查询对于大型图上的分析任务非常有用,例如查找社交网络中的关系,或根据共同属性推荐朋友或广告链接。
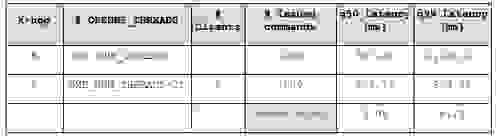
我们保留了之前的基准测试 Graph 500 数据集,比例为 22,具有以下图形特征

为了更深入地了解和覆盖数据库性能,我们将基准测试的种子覆盖范围从 300 个扩展到 100,000 个随机确定性种子。为了方便任何人复制我们的结果,这里提供了一个公共链接,指向 RDB 格式的比例为 22 的持久存储图形 500 数据集。
对于每个测试版本,我们执行了
所有查询都在 22 个客户端的并发并行负载下进行。 我们报告了中位数 (q50) 和可实现的吞吐量。
为了获得稳态结果,我们放弃了之前的 Python 基准测试客户端,转而使用memtier_benchmark,它提供低开销和完整的延迟范围指标。
所有基准测试变体都在 Amazon Web Services 实例上运行,这些实例通过我们的基准测试基础设施进行配置。 基准测试客户端和数据库服务器都在单独的 c5.12xlarge 实例上运行。 测试在单分片设置上执行,使用的 RedisGraph 版本为 1.2 和 2.0.5。
除了上述主要的基准测试/性能分析场景之外,我们还可以在网络、内存、CPU 和 I/O 上运行基线基准测试,以便了解底层网络和虚拟机特性。我们将我们的基准测试基础设施表示为代码,以便它稳定且易于重现。
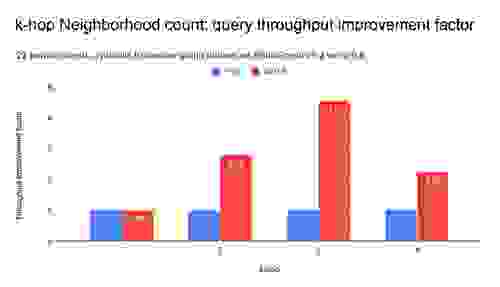
RedisGraph 1.2 与 2.0 的基准测试值表明并行工作负载(多个客户端)的性能得到了显著提高。我们测量到图遍历的延迟最多提高 6 倍,吞吐量最多提高 5 倍。并行性和计算密集型工作负载越高,与之前的版本相比,RedisGraph 2.0 的性能就越好。
RedisGraph 2.0 包含了最新版本 3.2.0 的 SuiteSparse:GraphBLAS —SuiteSparse的 GraphBLAS 实现 — RedisGraph 使用它来进行稀疏矩阵运算。 通过此版本,现在可以通过重复使用 OpenMP 来利用共享内存并行性,从而获得显著的性能优势。
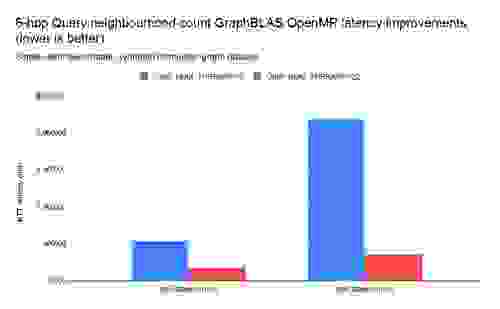
对 CPU 密集型查询的内部测试表明,RedisGraph 将其总 CPU 时间的 75% 左右花费在 SuiteSparse:GraphBLAS 上。 为了演示 SuiteSparse:GraphBLAS 基于 OpenMP 的并行实现在 RedisGraph 中的性能提升,我们测试了 6-hop 查询邻域计数,因为它在计算上非常密集。
如下所示,使用单线程 SuiteSparse:GraphBLAS 会转化为 537 毫秒的 q50 延迟,而使用 22 个 OpenMP 线程则为 175 毫秒,延迟最多减少 6 倍,并且 RedisGraph 没有额外成本。 在更高延迟范围(如 q99 之类的高分位数)中,改进更加明显
由于 RedisGraph 2.0 支持更多的 Cypher 功能,我们决定开始拥抱链接数据基准委员会 (LDBC) 基准测试。 LDBC 聚集了强大的行业参与者,以实现其标准化图数据管理系统评估的任务。在本节中,我们想介绍一下我们取得的进展。
LDBC 中的 LDBC 社交网络基准 (SNB) 是 RedisGraph 的一个逻辑选择,因为它支持复杂的读取查询,这些查询会接触大量数据,具有复杂的图依赖关系,并且要求图数据库支持复杂和创新的查询模式和算法。
在 LDBC SNB 基准测试中,节点和边的分布由类似于Facebook中发现的度分布函数指导。 此基准测试说明了模拟社交网络的一个重要方面,即具有相似兴趣和行为的人倾向于连接(称为同质性原则)。
与 SNB 的读取查询同时进行的是写入工作负载,它重现了真实的社交网络场景,例如在人之间添加友谊或点赞和评论帖子。
目前,从 LDBC SNB 基准测试查询中,我们支持 100% 的写入查询和 52% 的读取查询,如下表所示

即将支持的 Cypher 功能:OPTIONAL MATCH(相当于 SQL 中的外连接)、shortestPath(著名的最短路径问题的一种实现)以及列表和模式推导将使我们能够支持 100% 的 SNB 复杂读取查询。
与 1.2 版本相比,RedisGraph 2.0 带来了显著的性能提升,这可能会使查询速度提高 6 倍。 不仅顺序性能有所提高,而且 RedisGraph 还能够通过包含最新版本的 SuiteSparse:GraphBLAS 来利用共享内存并行性,从而带来更大的性能提升。
除了性能改进之外,我们为增强 Cypher 支持所做的工作使我们能够更接近于支持更丰富的社区驱动的 LDBC 基准测试,我们很高兴能够成为其中的一员,并使用它来改进和加强我们的解决方案。

