 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多


概要:我们利用强大的 Redis 模块 API,从头开始在 Redis 内部构建了一个超快速且功能丰富的搜索引擎,它拥有自己的自定义数据类型和算法。
今年早些时候,Redis 的作者 Salvatore Sanfilippo 开始开发一种允许开发人员使用新功能扩展 Redis 的方法:Redis 模块 API。此 API 允许用户编写代码,以将新的命令和数据类型添加到 Redis 中,使用原生 C 语言编写。在 Redis,我们迅速开始试验模块,以便将 Redis 带到以前从未去过的新领域。
我们探索的一个非常令人兴奋但不太容易的案例是构建搜索引擎。 许多用户已经通过客户端库将 Redis 用于搜索(我们甚至自己也发布了一个搜索客户端库)。 但是,我们知道 Redis 模块的强大功能将使这些库无法提供的搜索功能和性能成为可能。
因此,我们开始研究一种有趣的搜索引擎实现——完全用 C 语言构建,并使用 Redis 作为框架。 结果 RediSearch 现在作为一个开源项目提供。
其主要功能包括
让我们使用 redis-cli 工具查看 RediSearch 的一些关键概念
使用 RediSearch 的第一步是创建索引定义,该定义告诉 RediSearch 如何处理我们将添加的文档。
我们使用 FT.CREATE 命令,其语法为
FT.CREATE <index_name> <field> [<score>|NUMERIC] …
或者在我们的示例中
FT.CREATE products name 10.0 description 1.0 price NUMERIC
这意味着 name 和 description 被视为文本字段,其得分分别为 10 和 1,而 price 是用于过滤的数字字段。
现在我们可以使用 FT.ADD 命令将新产品添加到我们的索引中
FT.ADD <index_name> <doc_id> <score> FIELDS <field> <value> …
添加产品
FT.ADD products prod1 1.0 FIELDS
name “Acme 40-Inch 1080p LED TV”
description “Enjoy enhanced color and clarity with stunning Full HD 1080p”
price 277.99
该产品会立即添加到索引中,现在可以在将来的搜索中找到。
现在我们已经将产品添加到我们的索引中,搜索非常简单
FT.SEARCH products “full hd tv” LIMIT 0 10
或者价格过滤在 200 美元到 300 美元之间
FT.SEARCH products “full hd tv” FILTER price 200 300
结果在 redis-cli 中显示为
1) (integer) 1
2) “prod1”
3) 1) “name”
2) “Acme 40-Inch 1080p LED TV”
3) “description”
4) “Enjoy enhanced color and clarity with stunning Full HD 1080p at twice the resolution of standard HD TV”
5) “price”
6) “277.99”
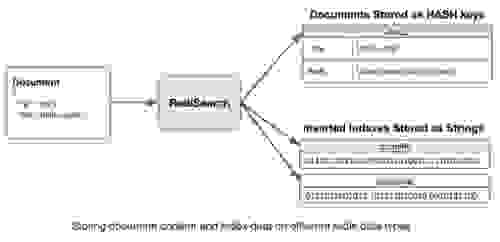
我们使用 RediSearch 的第一个设计选择是使用自定义数据结构对 倒排索引进行建模。 这样可以更有效地编码数据,并可能更快地遍历和相交索引。 我们选择仅使用 Redis 字符串键作为二进制编码的索引,并在搜索时直接从内存中读取它们,这种技术在模块 API 中称为字符串 DMA。 另一方面,我们使用普通的旧 redis 哈希对象来保存文档内容。
我们使用一种结合了 增量编码 和 Varint 编码 的技术将倒排索引保存在 Redis 中,以编码条目——最大限度地减少索引使用的空间,同时保持解压缩和遍历的效率。
RediSearch 的另一个重要功能是其自动完成或建议命令。 这样,您可以创建加权术语字典,然后查询它们以获得给定用户前缀的完成建议。 例如,如果用户开始将术语“lcd tv”放入字典中,则发送前缀“lc”会将完整术语作为结果返回。
RediSearch 还允许模糊建议,这意味着即使用户在其前缀中输入了错字,您也可以获得前缀的建议。 这是通过 Levenshtein 自动机 启用的,允许有效地搜索字典中与术语或前缀的最大 Levenshtein 距离 内的所有术语。
以下是在 RediSearch 中创建和搜索自动完成字典的示例
127.0.0.1:6379> FT.SUGADD completer “foo” 1
(integer) 1 127.0.0.1:6379> FT.SUGADD completer “football” 5
(integer) 2 127.0.0.1:6379> FT.SUGADD completer “fawlty towers” 7
(integer) 3 127.0.0.1:6379> FT.SUGADD completer “foo bar” 2
(integer) 4 127.0.0.1:6379> FT.SUGADD completer “fortune 500” 1
(integer) 5
127.0.0.1:6379> FT.SUGGET completer foo
1) “football”
2) “foo”
3) “foo bar”
127.0.0.1:6379> FT.SUGGET completer foo FUZZY
1) “football”
2) “foo”
3) “foo bar”
4) “fortune 500”
127.0.0.1:6379> FT.SUGGET completer faulty FUZZY
1) “fawlty towers”
为了评估 RediSearch 与其他开源搜索引擎相比的性能,我们创建了一组基准测试,用于测量延迟和吞吐量——同时对同一组数据进行索引和查询。
以下是一些结果,显示 RediSearch 的性能明显优于其他开源搜索引擎(当然,与往常一样,基准测试结果应谨慎对待。 请参阅链接的白皮书,了解有关基准测试的更多结果和信息)
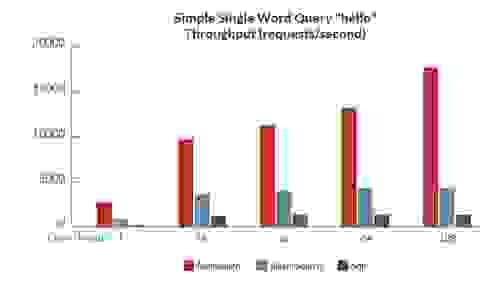
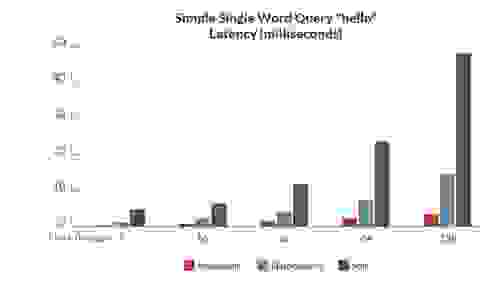
基准测试 1:简单的单字查询 – hello
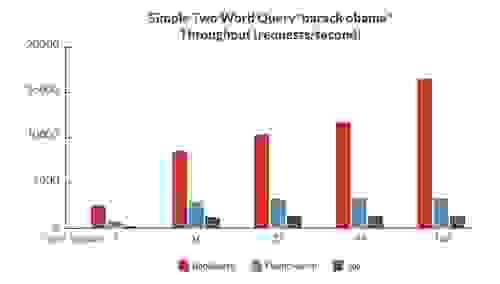
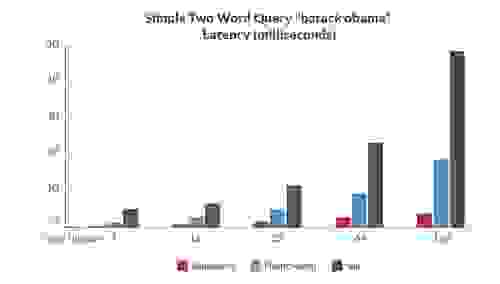
基准测试 2:双字查询 – barack obama
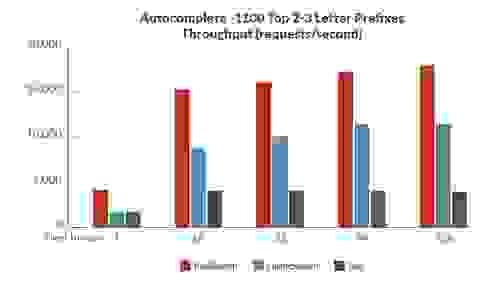
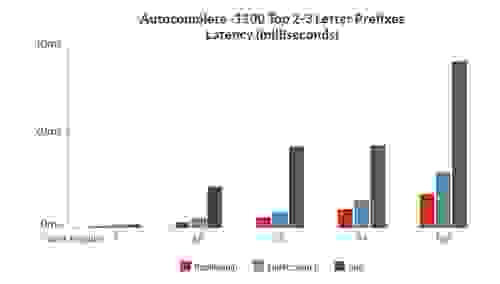
基准测试 3:自动完成 – 维基百科中 1100 个最常用的 2-3 个字母的前缀

