 Redis 8 已正式发布——并且是开源的
Redis 8 已正式发布——并且是开源的

视频

云迁移策略误区
了解更多



继最近推出 Redis 7.2 之后,这彰显了我们对先进开发者工具和 AI 创新的承诺,Redis 很高兴地宣布将 Redis Cloud 与 Amazon Bedrock 集成,作为构建 RAG 应用的知识库。
AWS 在设计Amazon Bedrock 时充分考虑了客户需求:在无需复杂基础设施管理的情况下无缝访问强大的基础模型 (FM),并能够安全地自定义这些 FM。今天的公告确保了开发者可以使用统一的 API 访问来自 Cohere、AI21 Labs、Anthropic、Stability AI 和 Amazon 的 FM,并由高性能数据层提供支持(请在此阅读 AWS 博客上的公告)。
考虑到公司在企业级能力(如高可用性、持久性、可扩展性和地理复制以实现业务连续性)方面的投入,Redis Cloud 作为高性能、稳定的向量数据库所获得的关注度并不令人惊讶。
过去,将私有、领域特定数据与大型语言模型 (LLM) 的功能相结合对于 Redis 开发者来说是一项劳动密集型任务。流程复杂:提取源文档,将其转换为嵌入,将其馈送到 Redis,然后按需执行复杂的向量搜索查询。
Redis 与 Amazon Bedrock 之间新建立的集成标志着简化生成式 AI 开发过程的关键一步。通过将 Redis 作为外部知识库无缝连接到Agents for Amazon Bedrock,它弥合了您的领域特定数据与 LLM 的强大功能之间的差距。这种协同作用自动化了从 Amazon S3(PDF、doc、txt 等)向 Redis Cloud 导入业务文档的过程,使开发者摆脱了数据准备和集成的复杂任务。有了这个基础,使用 Amazon Bedrock 构建的智能代理可以通过检索增强生成 (RAG) 从 Redis 中提取相关上下文,从而丰富模型提示。
LLM 自身可能很聪明,甚至令人惊叹,但它们绝非万无一失。如果没有领域特定数据,LLM 的相关性和实用性就会降低。简单来说,虽然 LLM 拥有丰富的通用知识,但当它们适应您的特定数据时,神奇的事情才会发生。
然而,在自定义数据上训练和微调 LLM 以满足您的需求可能需要大量的计算能力,这会带来新的成本。RAG 旨在解决这个问题:弥合 LLM 的通用知识与您自己的宝贵数据之间的差距。
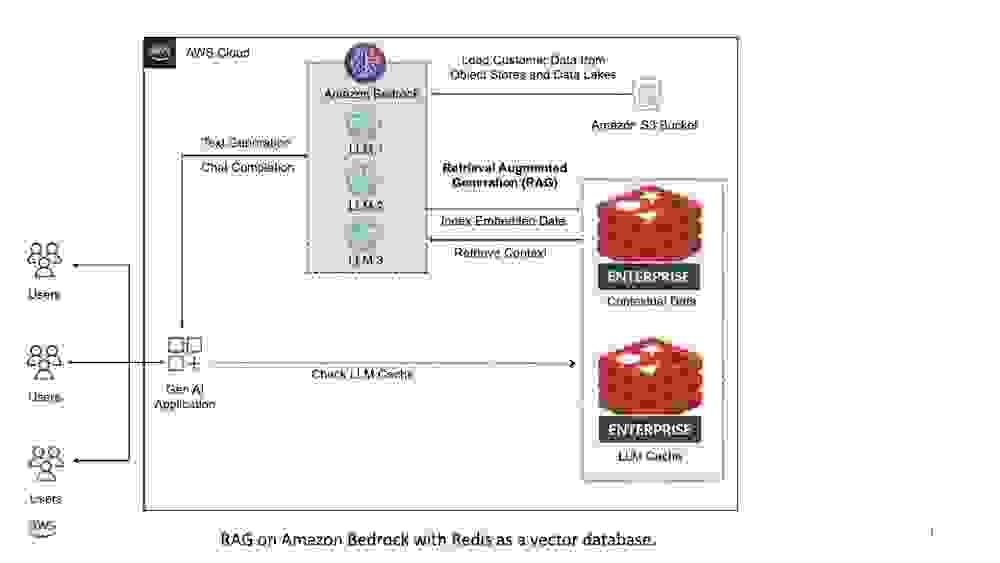
此参考架构重点说明
上下文相关性:Redis Enterprise 将领域特定数据存储和索引为向量嵌入。在运行时,它会根据用户的查询使用向量相似性搜索获取最相关的上下文数据块。通过将检索到的上下文合并到 LLM 提示(输入)中,它可以确保输出针对您的领域进行定制。
可扩展性:随着知识库的扩展,Redis Enterprise 通过在分布式集群中对数据和搜索索引进行分片来实现水平扩展。
安全性:您不希望敏感数据或知识意外泄露。通过将其外部存储在向量数据库(例如 Redis)中,保护关键数据不被合并到中央 LLM 中。这确保遵守最高安全标准,包括静态和传输中加密,以及强大的基于角色的访问控制。
成本效益:该集成减少了持续 LLM 训练或微调的需求。结果如何?您既节省了计算需求(更快的聊天机器人性能),又节省了成本。
Redis Cloud 与Agents for Amazon Bedrock 的结合重新定义了生成式应用在技术方面的潜力,并缩短了上市时间,这令业务方感到满意。
我们来看一些实际示例。
随着业务规模的扩大,及时有效地处理客户问询变得越来越具有挑战性。传统聊天机器人可能无法提供准确或有上下文意识的回复。
通过将公司的庞大知识库或常见问题数据库与向量数据库连接起来,RAG 系统可以使聊天机器人能够拉取实时、特定于上下文的信息。例如,用户可能会询问特定的产品功能或故障排除步骤;支持 RAG 的机器人随后将从数据库中检索最相关的详细信息,并生成连贯、有用的回复,从而提高客户满意度并减少人工干预。
内容营销人员经常需要撰写与特定受众群体产生共鸣的文章、博客文章或宣传材料,但查找相关的旧内容作为参考或灵感可能会非常耗时。
通过将先前的营销材料、产品文档、客户反馈和市场研究转换为向量嵌入,RAG 系统可以帮助内容创作者生成新内容。例如,在撰写一篇关于产品功能的新文章时,系统可以提取相关的客户评价、过去的营销角度和当前市场趋势,从而使作者能够创作出更具说服力和信息量的内容。
要开始使用 Amazon Bedrock 进行生成式 AI 并将 Redis Cloud 作为您的向量数据库,您需要通过 AWS Marketplace 创建数据库,使用 Amazon Secrets Manager 设置 AWS Secret,然后在 Redis Cloud 中为向量相似性搜索创建索引。
无论您是从 Amazon Bedrock 知识库配置屏幕链接,还是使用此定制的 AWS Marketplace 产品链接,您都将为启用 TLS 的 Redis Cloud 创建一个灵活的即用即付订阅。如果您是 Redis 的新用户,我们提供 14 天价值 500 美元的免费试用,助您入门。
请按照此详细指南创建您的 Redis Cloud 数据库。
创建数据库时,您最终会进入一个需要输入“内存限制 (GB)”的步骤。

Amazon Bedrock 从 Amazon S3 获取原始文档,创建更小的文本块,生成嵌入和元数据,并将其作为哈希 upsert 到 Redis 中。为了使 RAG 正常工作,文本块应该从源文档中捕获足够的独立语义上下文以供使用。因此,Bedrock 创建的文本块平均长度约为 200 个单词。
我们来看一个示例,您的 Amazon S3 数据集大小为 10,000KB。(了解如何确定存储桶大小的更多信息。)
综合以上各项,我们可以估算最终的 Redis 数据库大小为原始文本内容、向量嵌入和向量索引的总和,乘以预期的总块数
(1KB + 12.5KB) * 10,000 个预期块 = 135,000KB
我们创建了下表,以帮助您选择一个合理的起点。虽然它是可选的,但对于任何生产部署,我们强烈建议启用带复制的高可用性 (HA) 以确保峰值性能。您可以根据需要在 Redis Cloud 控制台中随时监控和调整此大小。
| S3 中文档总大小 | 不带复制的数据库大小(无 HA) | 带复制的数据库大小(带 HA) |
| 10,000KB | 135MB | 270MB |
| 100,000KB | 1.35GB | 2.7GB |
| 1,000,000KB | 13.5GB | 27GB |
| 10,000,000KB | 135GB | 270GB |
创建数据库后,使用Amazon Secrets Manager 创建 Secret,其中包含以下字段
存储此 Secret 后,您可以在 Secret 详情页面查看和复制您的 Secret 的亚马逊资源名称 (ARN)。如果您需要更多帮助,请按照此分步指南创建所需的连接 Secret。
在 Redis Cloud 中设置好数据库后,您需要创建一个带有向量字段的索引,作为 Amazon Bedrock 的知识库。
使用 Redis,您可以在哈希或 JSON 字段上构建二级索引,包括文本、标签、地理位置、数值和向量。对于向量相似性搜索,您必须在 FLAT(暴力)或 HNSW(近似,更快)向量索引类型,以及支持的三种距离指标(内积、余弦距离、L2 欧几里得距离)中进行选择。选择正确的索引类型应基于您的文档数据集的大小以及所需的搜索准确性和吞吐量水平。
对于刚开始使用 Amazon Bedrock,我们推荐使用以下简单索引配置设置
假设您的文档数据集不是很大,并且您需要 RAG 的最高检索准确性,那么此索引配置是一个可靠的起点。
Redis 开箱即用,提供了几种选项来使用 RedisInsight、 RedisVL 或 Redis 命令行界面 (CLI) 创建索引。
RedisInsight 是桌面图形用户界面 (GUI),用于可视化浏览 Redis 中的数据并与之交互。请按照我们的专用指南中的步骤使用 RedisInsight 创建您的向量索引。
RedisVL 是一个新的、专用的 Python 客户端库,可帮助 AI 和 ML 从业者利用 Redis 作为向量数据库。
首先,使用 pip 在您的 Python (>=3.8) 环境中安装 RedisVL
pip install redisvl==0.0.4
复制此包含适用于 Amazon Bedrock 的基本 Redis 向量索引规范的 YAML 文件,并将其粘贴到名为 bedrock-idx.yaml 的本地文件中
index:
name: bedrock-idx
fields:
vector:
- name: text_vector
dims: 1536
algorithm: flat
distance_metric: cosine
您现在可以在终端中使用 rvl 命令连接到数据库并从 YAML 模式定义创建新索引。
设置 REDIS_URL 环境变量,其中包含用户名、密码、主机、端口以及所有三个必需的 TLS 证书文件的完整路径
export REDIS_URL="rediss://<USER>:<PASSWORD>@<HOST>:<PORT>?ssl_ca_certs=<redis_ca.pem>&ssl_certfile=<redis_user.crt>&ssl_keyfile=<redis_user_private.key>&ssl_cert_reqs=required"
现在,运行命令创建索引。注意成功消息
rvl index create -s bedrock-idx.yaml
使用 listall 或 info 命令验证索引是否已成功创建
rvl index info -s bedrock-idx.yaml
要使用 Redis CLI,请在您的本地机器上下载 Redis。使用 CLI 连接到您的数据库,包括 TLS 证书
redis-cli -h <endpoint> -p <port> -a <password> \
--tls --cacert <redis_ca.pem> \
--cert <redis_user.crt> \
--key <redis_user_private.key>
执行以下代码片段创建一个名为 bedrock-idx 的索引
FT.CREATE "bedrock-idx" // Index name
ON HASH // Indicates the type of data to index
SCHEMA
"text_vector" VECTOR FLAT // Vector field name and index type i.e. FLAT
6 // 6 index parameters follow
"TYPE" "FLOAT32" // only FLOAT32 is currently supported by Bedrock
"DIM" 1536 // Each vector will have 1536 dimensions
"DISTANCE_METRIC" "COSINE" // Other values could be "IP" "L2"
至此,一切准备就绪。现在是时候将您的 Redis 部署与 Amazon Bedrock 集成,作为 RAG 的知识库了。
✅ Redis 数据库已部署
✅ AWS Secret 已创建
✅ 向量索引已创建
在 Amazon Bedrock 知识库配置屏幕上,选择您的源 Amazon S3 存储桶。确保已选择 Redis Cloud 作为您的向量数据库。填写您的数据库 端点 URL、凭证 Secret ARN 和 向量索引名称。
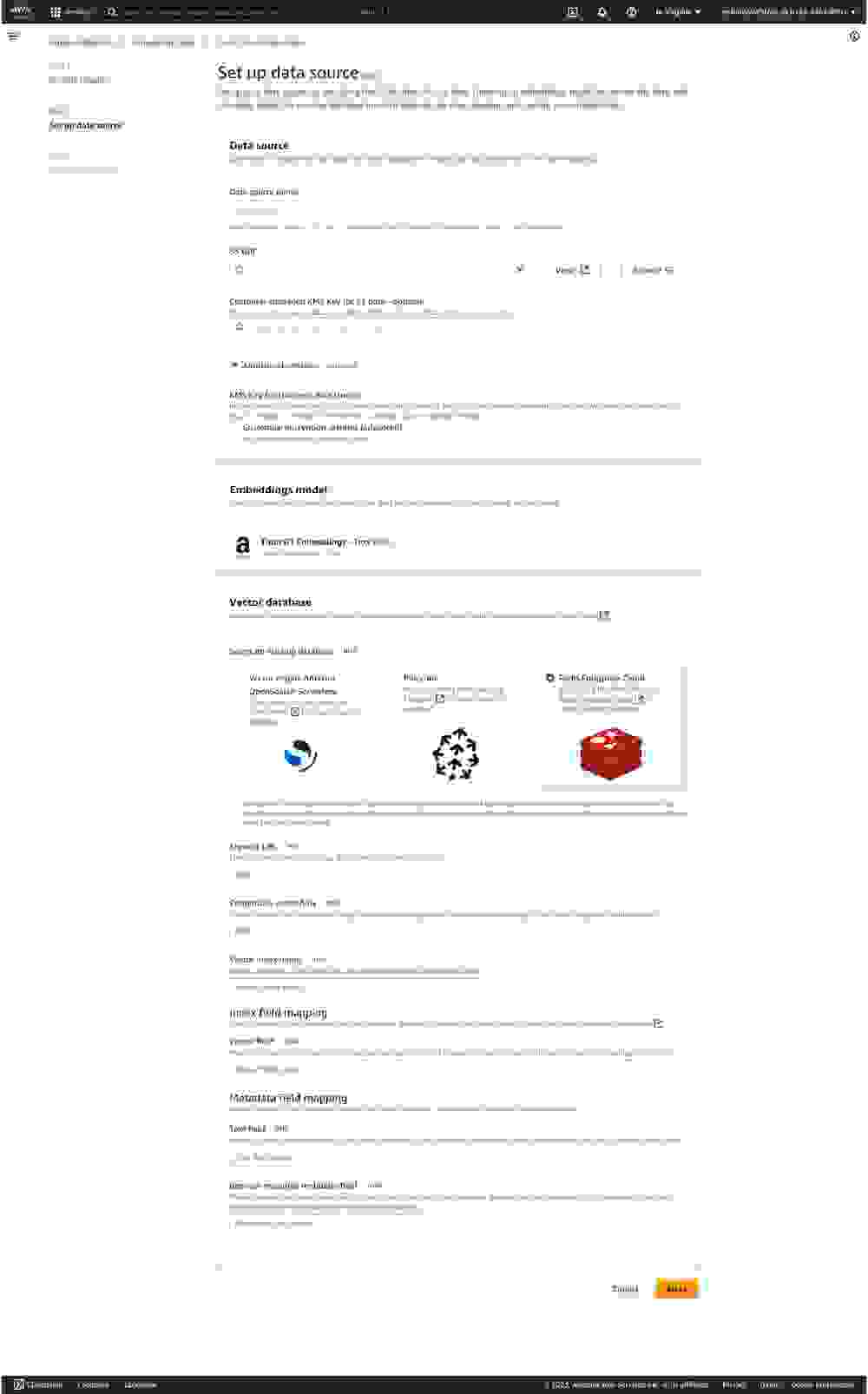
最后,填写您为 索引字段映射 定义的名称和 Amazon Bedrock 创建的 元数据字段映射。这些是在 Amazon Bedrock 处理来自 Amazon S3 的源数据时自动创建的。
准备好使用 Redis Cloud 和 Amazon Bedrock 开启您的生成式 AI 之旅了吗?首先访问 AWS 控制台中的 Amazon Bedrock 页面,并在此阅读 AWS 的公告。
您是否有想要重点介绍的使用案例或示例?不妨一试,并在我们的 GitHub 仓库中提交包含社区示例的 PR。
试用此集成后想深入了解或需要额外帮助?我们随时为您提供帮助。立即联系 Redis 专家。
免费试用 Redis Enterprise 的全部强大功能,无需预付费用或承诺。我们全新的 14 天免费试用包括 Redis Enterprise 的所有功能,并在 AWS Marketplace 中提供。立即免费开始!

