 Redis 8 发布了!它是开源的
Redis 8 发布了!它是开源的
了解更多

R于 2018 年 10 月发布的 Redis Enterprise Kubernetes Operator 只有大约一年的历史,但已有多个客户正在使用它在生产环境中运行 Redis Enterprise 集群。 现在,在我们庆祝 Kubernetes Operator 的第一个生日之际,我们正在向其工具集添加另一个强大的 Day-2 运维支持功能:自动化集群恢复。
Kubernetes Operator 首次可以像管理无状态服务一样管理有状态服务,从而改变了系统运维人员和开发人员在各种环境中测试、部署和管理 Redis 的方式。
作为一些背景信息,Redis Enterprise 集群是一个用于在多隔离租户架构中管理各种配置的多个数据库的平台。 我们喜欢将其视为 Redis 数据库实例(也称为分片)的编排平台。
这些数据库中的每一个都可以通过以下方式之一进行设置
在典型的部署方案中,集群可以管理数百个分片,扩展到数十 TB 的数据,并每秒运行数千万次操作。
Redis Enterprise 集群采用多种机制来保证集群的可用性,即使在多个分片故障或节点故障事件的情况下,只要大多数集群节点保持活动状态。
在不太可能发生的称为仲裁丢失的情况下,当超过一半的集群节点宕机时,会发生许多不好的事情。 缓存不再存储复杂的操作或返回缓存的结果,从而延长了应用程序响应时间。 Web 会话丢失,电子商务购物车被清空。
任何此类事件都可能对组织产生深远的负面业务后果,从糟糕的客户体验到多次交易的损失,并且这些影响在繁忙时段、旺季或其他特殊事件(如产品发布)期间会被放大。
在所有这些情况下,将集群及其数据恢复到原始、完全运行状态对于关键业务的 Redis 用例至关重要,即使一秒钟的停机时间也可能转化为数千甚至数百万次操作的损失。
除了从不常见的灾难和错误中恢复之外,还有其他操作场景也需要自动化集群恢复。 Redis 运维人员经常将集群重新定位或复制到新环境,以便在新区域提供服务或服务于不断增长的人群。 他们还希望回收集群的底层基础设施以进行维护、修补和扩展,从而最大限度地减少对生产服务的影响。 为了提高弹性,他们需要精确、可重复且快速的恢复模型来促进生产环境中的混沌工程。
Kubernetes 原生编排无状态服务的生命周期,而对于像我们的集群这样的有状态服务,该责任将由系统运维人员承担。 这就是 Redis Enterprise Kubernetes Operator 发挥作用的地方。
我们的新集群恢复机制让用户可以通过在短短几分钟内从整个集群故障事件中恢复来解决所有这些场景及更多场景。 Kubernetes Operator 集群恢复执行一个完全自动化、可预测且一致的过程来恢复 Redis Enterprise 集群。 这些操作以前可能需要数小时才能完成,并且更容易受到人为错误的影响,现在它们快速、可靠且完全自动化。
凭借我们在所有主要公共云和数百个本地环境中管理超过一百万个生产中的 Redis 实例的多年运营知识,我们引入了一个专门的流程来编排集群引导。 在正常运行条件下,引导程序会在部署实例化时创建一个新集群。 当需要集群恢复时,系统运维人员可以轻松更新集群的声明式规范以启动恢复过程。
对于自动恢复,引导程序会重新创建集群并自动挂载先前集群的持久卷声明,其中包含持久性数据。 然后,它会恢复原始集群配置,加入剩余节点,并在新的已恢复集群上重新创建原始集群上预置的所有数据库。 接下来,恢复会加载数据集,在集群节点之间平衡数据,并将先前使用的端点与每个数据库相关联。
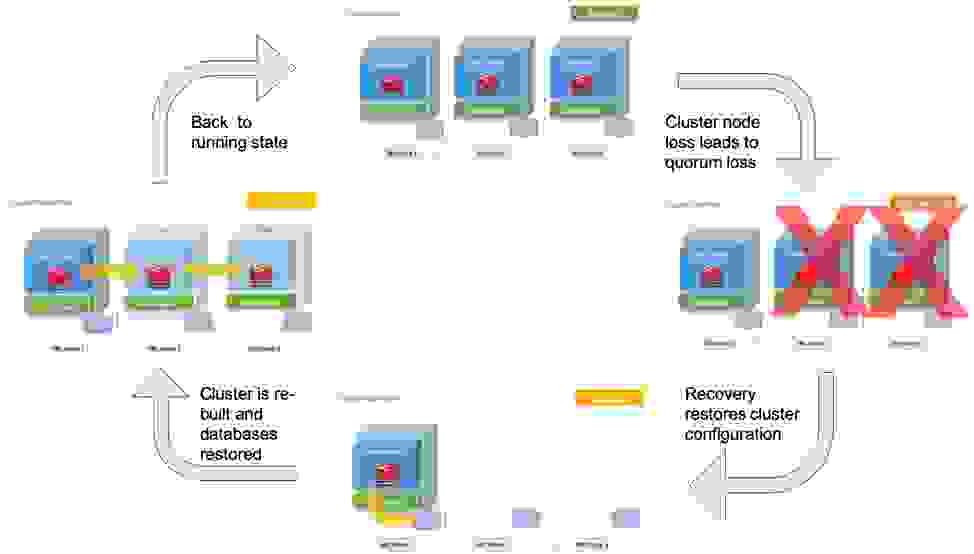
在大多数情况下,集群会在几分钟内恢复,无需人工干预。
新的 Kubernetes Operator 驱动的恢复体验现已推出,并包含在我们最新版本的 Kubernetes 部署和 Redis Enterprise 集群中。
如果您想体验 Redis Operator 如何执行自动化集群恢复,您可以通过按照我们的Kubernetes 文档或GitHub上的说明,在多个 Kubernetes 发行版中的任何一个发行版上,在本地或云端设置 Redis Enterprise 集群。然后,访问 Redis Enterprise Cluster Recovery for Kubernetes page 以获得演练。

