 Redis 8 已发布——它是开源的
Redis 8 已发布——它是开源的
了解更多




在 Redis,我们速度很快。为了展示我们的速度,我们使用新的 Redis 查询引擎(现已在 Redis Software 中正式发布)对市场上的顶级向量数据库提供商进行了基准测试。此功能增强了我们的引擎,使其能够并发访问索引,从而提高了 Redis 查询、搜索和向量数据库工作负载的吞吐量。这篇博客文章展示了我们的基准测试结果,解释了提高查询吞吐量面临的挑战,以及我们如何通过新的 Redis 查询引擎克服这些挑战。这篇博客包含三个主要部分
让我们从最重要的部分开始:Redis 的速度有多快。
除了摄取和索引创建时间外,我们还对 7 家向量数据库提供商的两项关键指标进行了基准测试:吞吐量和延迟(有关指标和原则的详细信息请参见下文)。吞吐量表示系统在短时间内处理大量查询或大型数据集的能力,而延迟则衡量单个相似性搜索返回结果的速度。
为了确保涵盖这两方面,我们进行了两次基准测试,一次是侧重于吞吐量的多客户端基准测试,另一次是侧重于延迟的单客户端和负载下(多客户端)基准测试。所有结果都可以在下面的图表中进行过滤,测试的详细过程可以在博客中找到。对于 Redis 而言,优先考虑吞吐量和延迟与我们提供卓越速度和可靠性的核心理念一致。
我们的测试表明,在召回率 ≥ 0.98 时,Redis 在向量数据库工作负载方面的速度比我们测试过的任何其他向量数据库都快。对于低维数据集 (deep-image-96-angular),Redis 的吞吐量比排名第二的数据库高出 62%;对于高维数据集 (dbpedia-openai-1M-angular),吞吐量高出 21%。
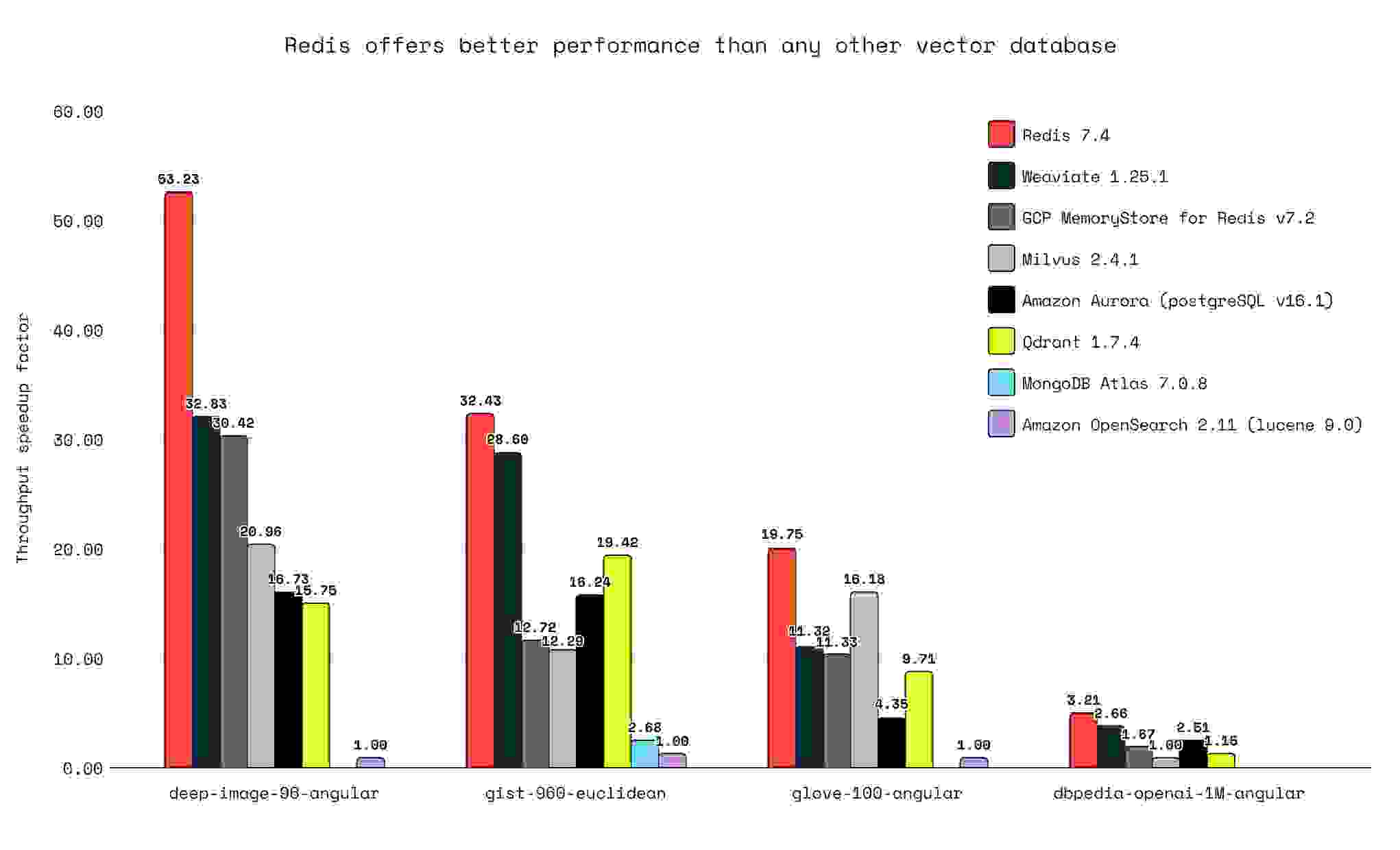
注意:MongoDB 测试仅在使用 gist-960-euclidean 数据集进行较低召回率测试时提供了结果。此数据集的结果考虑的是召回率在 0.82 到 0.98 之间的结果中位数。对于所有其他数据集,我们考虑的是召回率 ≥ 0.98。
Redis 在查询吞吐量和延迟方面优于其他纯粹的向量数据库提供商。
查询:在相同召回率下,Redis 实现了比 Qdrant 高出 3.4 倍的每秒查询数 (QPS),比 Milvus 高出 3.3 倍的 QPS,比 Weaviate 高出 1.7 倍的 QPS。在延迟方面(此处指多客户端测试的平均响应),在相同召回率下,Redis 的延迟比 Qdrant 低 4 倍,比 Milvus 低 4.67 倍,比 Weaviate 快 1.71 倍。在负载下(多客户端)的延迟方面(此处指平均响应),Redis 的延迟比 Qdrant 低 4 倍,比 Milvus 低 4.67 倍,比 Weaviate 快 1.71 倍。
摄取和索引:Qdrant 由于其多段索引设计而速度最快,但 Redis 在快速查询方面表现出色。Redis 的索引时间比 Milvus 低 2.8 倍,比 Weaviate 低 3.2 倍。
本节详细比较了 Redis 7.4 与其他仅提供向量功能的行业提供商,如 Milvus 2.4.1、Qdrant 1.7.4 和 Weaviate 1.25.1。
在下面的图表中,您可以分析所有结果,包括 RPS(每秒请求数)、延迟(单客户端和多客户端,负载下)、P95 延迟和索引时间。所有指标均根据不同的选定数据集进行测量。
在单客户端基准测试中,有些情况下 Redis 和竞争对手的表现处于同一水平。Weaviate 和 Milvus 在云环境设置中出现了操作问题;详细发现请参见附录。
在支持向量相似性搜索的通用数据库的查询性能基准测试中,Redis 显著优于竞争对手。
查询:在相同召回率下,Redis 实现了比使用 pgvector 0.5.1 的 Amazon Aurora PostgreSQL v16.1 高出 9.5 倍的每秒查询数 (QPS) 和低 9.7 倍的延迟。与使用 Atlas Search 的 MongoDB Atlas v7.0.8 相比,Redis 展现了高出 11 倍的 QPS 和低 14.2 倍的延迟。与 Amazon OpenSearch 相比,Redis 展现了高出 53 倍的 QPS 和低 53 倍的延迟。
摄取和索引:Redis 相对于使用 pgvector 0.5.1 的 Amazon Aurora PostgreSQL v16.1 展现了显著优势,索引时间低 5.5 至 19 倍。
本节详细比较了 Redis 7.4 与使用 pgvector 0.5.1 的 Amazon Aurora PostgreSQL v16.1、使用 Atlas Search 的 MongoDB Atlas v7.0.8 以及 Amazon OpenSearch 2.11,为通用数据库云环境中的向量相似性搜索性能提供了有价值的见解。
在下面的图表中,您可以分析所有结果,包括 RPS(每秒请求数)、延迟(单客户端和多客户端,负载下)和 P95 延迟,以及索引时间。所有指标均根据不同的选定数据集进行测量。
除了上面展示的性能优势外,一些通用数据库在向量搜索方面存在局限性,例如精度不足和索引配置的可能性问题,这些在附录中有详细描述。
与其他 Redis 模仿者(如 Amazon MemoryDB 和 Google Cloud MemoryStore for Redis)相比,Redis 展现了显著的性能优势。这表明 Redis 及其企业级实现针对性能进行了优化,超越了其他模仿 Redis 的提供商。
查询:在相同召回率下,与 Amazon MemoryDB 相比,Redis 实现了高出 3.9 倍的每秒查询数 (QPS) 和低 4.1 倍的延迟。与 GCP MemoryStore for Redis v7.2 相比,Redis 展现了高出 2.5 倍的 QPS 和低 4.8 倍的延迟。
摄取和索引:Redis 相对于 Amazon MemoryDB 具有优势,索引时间低 1.39 至 3.89 倍。与 GCP MemoryStore for Redis v7.2 相比,Redis 展现了更大的索引优势,索引时间低 4.9 至 10.34 倍。
在下面的图表中,您可以分析所有结果,包括:RPS(每秒请求数)、延迟(单客户端和负载下的多客户端)、P95 延迟和索引时间。所有指标均根据不同的选定数据集进行测量。
为了实现上述结果,我们引入了一项新的增强功能,使查询能够并发访问索引。本节详细阐述了这些增强功能以及我们的工程团队如何克服这些挑战。
Redis 拥有 经过验证的单线程 架构,我们不断寻求改进以进一步提升 Redis。为此,我们需要克服现有设计的一些限制。首先,Redis 的读写命令(Redis 操作)扩展方式基于一个假设,即大多数命令都是短时命令,通常每个命令的时间复杂度为 O(1),并且相互独立。因此,使用 Redis Cluster 将数据分片到独立的 Redis 分片(即向外扩展)会导致将多个请求扇出到多个分片,从而实现即时负载均衡并均匀分配命令。但这对于所有高表达性(多个查询项和条件)或涉及任何数据操作(排序、分组、转换)的 Redis 查询来说并非如此。其次,单线程上的长时间运行查询会导致拥塞,增加整体命令延迟,并降低 Redis 服务器的整体吞吐量。例如,利用倒排索引进行数据搜索就是这样一种长时间运行的查询。
搜索不是一个 O(1) 时间复杂度的命令。搜索通常结合对多个索引的扫描以满足多个查询谓词。这些扫描通常以对数时间复杂度 O(log(n)) 完成,其中 n 是索引映射的数据点数量。 进行多次这样的扫描,并结合和聚合它们的结果,与典型的 Redis 操作(如 GET、SET、HSET 等)相比,计算量要重得多。这与我们关于命令简单且运行时间短的假设相悖。
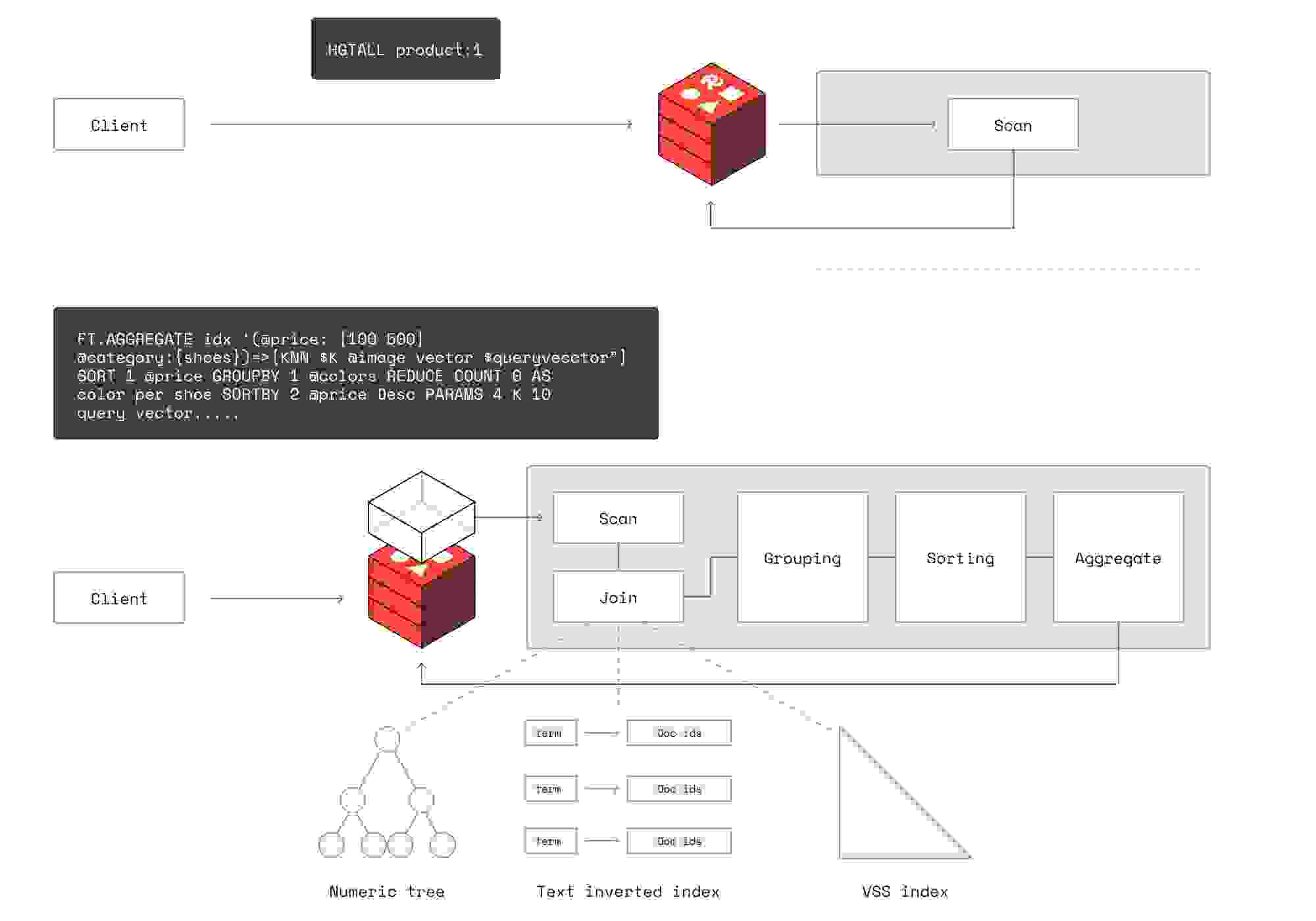
具有亚线性时间复杂度的向外扩展无助于降低单客户端延迟,而降低单客户端延迟是在单线程架构中提高吞吐量所必需的。尽管分片可以将数据分布到多个 Redis 进程(和节点)上,但随着分片的增加,总查询时间并没有显著减少,因此 Redis 进程的数量也没有显著减少。我们有两个原因:
例如,如今搜索相似向量,即使使用最先进的算法,计算量仍然很大,因为它会将查询向量与索引提供的每个候选向量进行比较。这种比较不是 O(1) 比较,而是 O(d),其中 d 是向量维度。简单来说,每次计算都是比较整个两个向量。这需要大量的计算。当在主线程上运行时,这会使 Redis 的主线程阻塞时间比常规 Redis 工作负载甚至其他搜索用例更长。
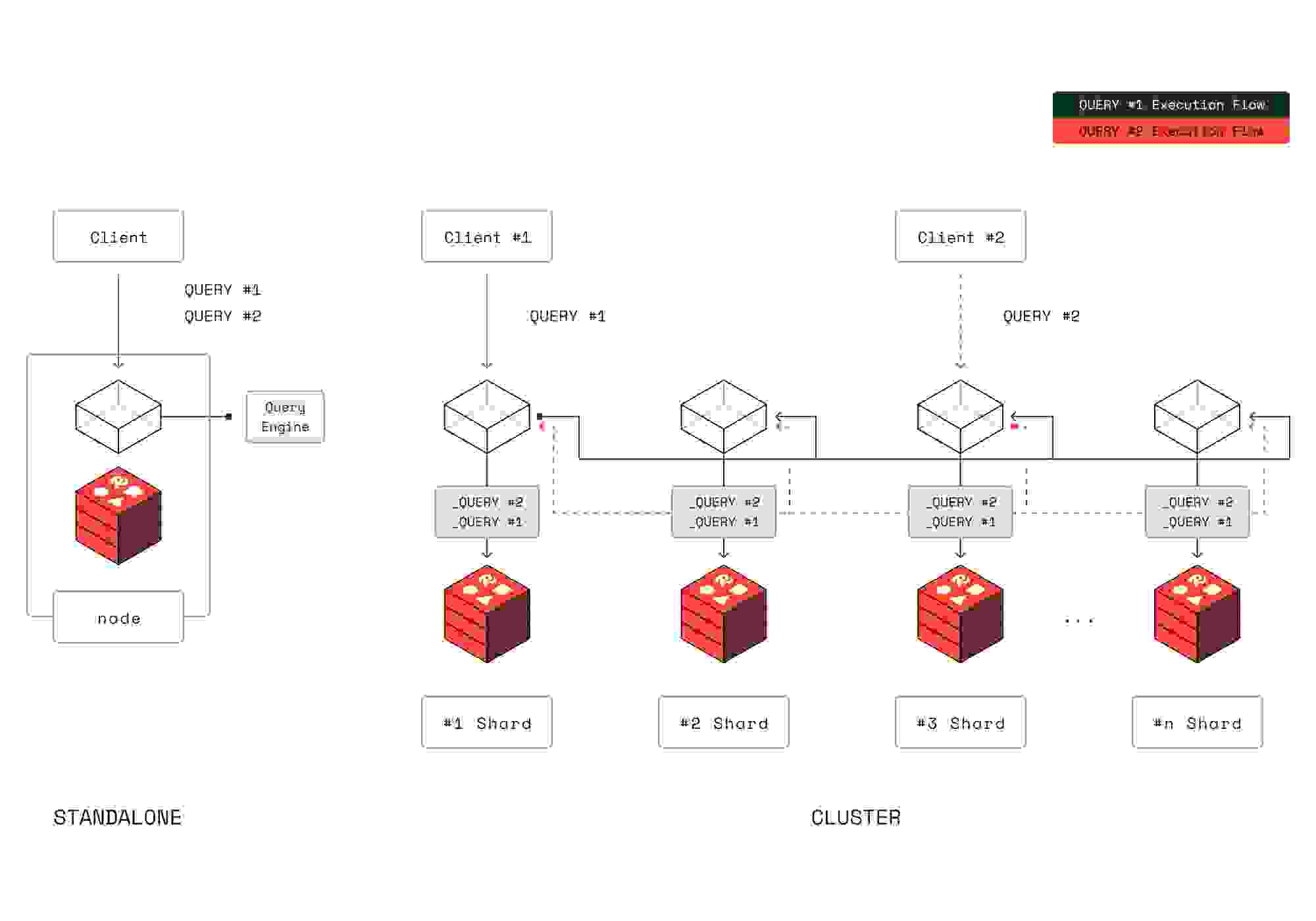
有效扩展搜索需要结合数据的水平分布(向外扩展)和垂直多线程处理,从而实现对索引的并发访问(向上扩展)。下图展示了单个分片的架构。
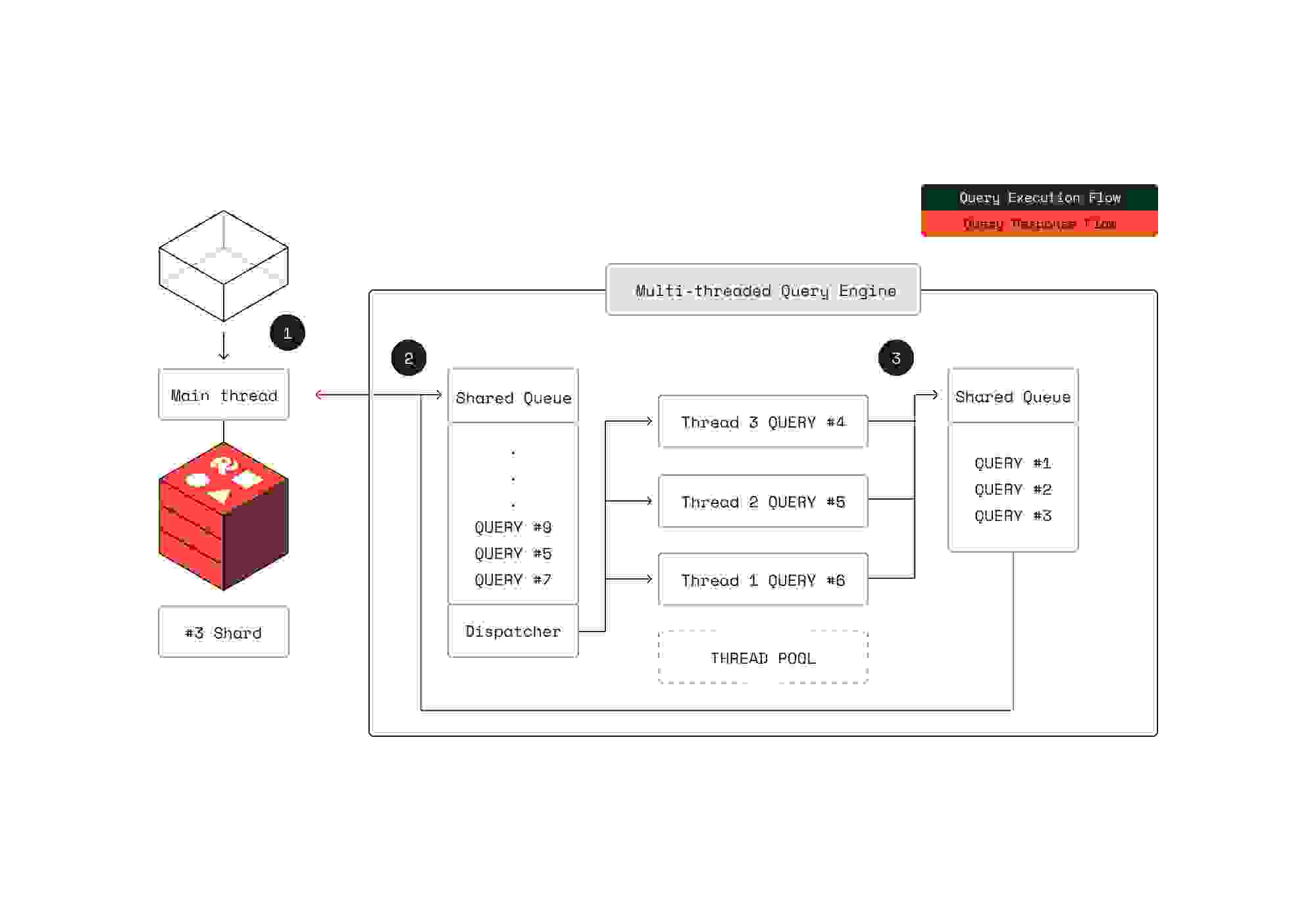
正在执行多个查询,每个查询都在一个单独的线程上。我们采用了简单但著名的生产者-消费者模式。1. 查询上下文(规划)在主线程上准备好,并排入共享队列。2. 然后,线程从队列中取出任务,并与其他线程并发执行查询管道。这使我们能够执行多个并发查询,同时保持主线程活跃,以处理更多传入请求,例如其他 Redis 命令,或准备和排队更多查询。3. 完成后,查询结果会发送回主线程。
为了对我们的 Redis 查询引擎进行基准测试,我们使用全文搜索和向量搜索查询对 Redis 进行了测试。特别是对于向量搜索,我们选择了 gist-960 数据集,其中包含 1M 个向量,每个向量有 960 维,并比较了单分片旧设置与使用 6、12 和 24 线程配置的新设置,同时改变了 HNSW 索引的 M(每个节点的最大连接数)和 EF(搜索期间动态候选列表的大小)配置。
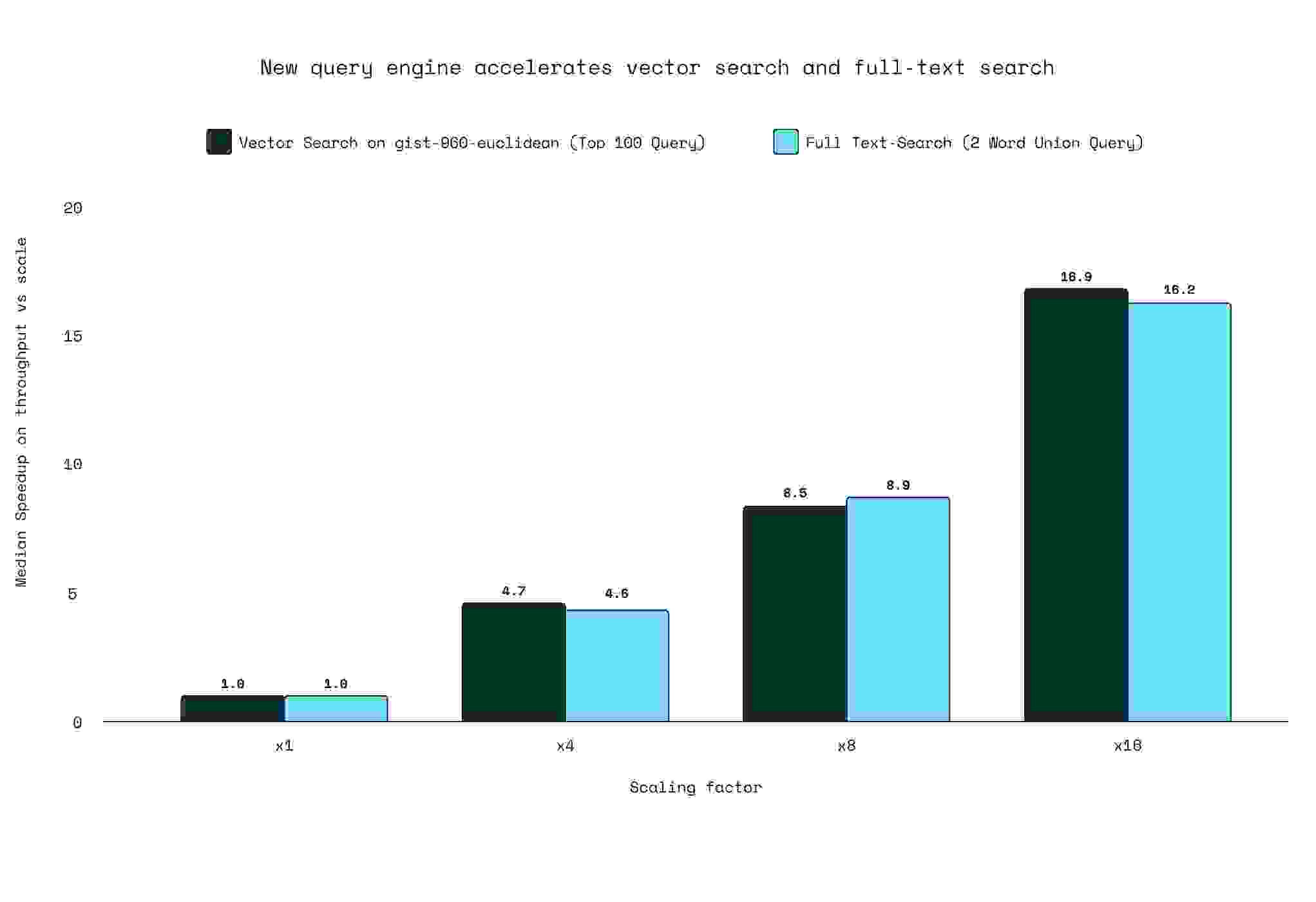
性能提升是持续的,表明查询吞吐量每增加 2 倍,就需要增加 3 倍的线程数,这表明在所有配置下资源利用都非常高效。我们测试了FLAT(暴力)算法和HNSW 扩展,我们的测试证实,每个扩展因子应用于两种算法的垂直扩展加速比(新增资源提高可实现吞吐量的效率)都是一致的。下图说明了向量工作负载的可扩展因子。

基于这些发现,我们引入了“扩展因子”概念,这是一个通过激活额外线程和 vCPU 来显著提升查询吞吐量,从而增强性能的比例。将这些结果也扩展到全文搜索用例,我们可以确认理论扩展因子与经验结果非常吻合。
我们将继续改进 Redis 查询引擎。有时,最好不要等待后台线程接手任务,而是直接在主线程上执行查询。对于简短简单的查询来说,似乎就是这种情况。访问键空间仍然是一个瓶颈,因为它需要锁定主线程,而索引在键空间外部拥有自己的优化数据结构。有时,当查询明确请求从键空间加载数据或投影数据(`RETURN` 或 `LOAD`)时,我们需要遵守 Redis 规则并锁定键空间(Redis 锁定机制)。这一点也可以改进。
本节包含有关设置、测试方式以及数据集和工具选择原因的所有详细信息。让我们从我们的基准测试原则开始。
为了确保基准测试有意义且可操作,我们认为良好的基准测试应遵循以下原则
通过遵守这些原则,我们努力确保我们的基准测试在与其他解决方案比较时提供有价值的见解,推动我们的查询引擎持续改进,并坚持 Redis 提供卓越性能的承诺。
我们将 Redis 与三类提供商进行了比较:纯向量数据库提供商、具备向量功能的通用数据库以及云服务提供商上的 Redis 模仿者。
我们将 Redis 与三类向量数据提供商进行了比较:纯向量数据库提供商、具备向量功能的通用数据库以及其他 Redis 模仿云服务提供商。我们发现这三类提供商在速度、可扩展性和企业级功能方面差异很大。纯向量数据库在性能方面更好,但在扩展方面较差。通用数据库在性能方面差得多,但在其他集成方面更好。而 Redis 模仿者在没有最新速度改进的情况下要慢得多。许多用户认为 Redis 模仿者一样快,但我们希望通过将它们与 Redis 进行比较来打破这种幻想,从而为您节省时间和金钱。
主要发现总结如下
| 纯粹提供商 | 通用数据库 | Redis 模仿者提供商 | |
| 提供商 | Qdrant, Weaviate, Milvus | Amazon Aurora ( PostgreSQL w/ pgvector), MongoDB, Amazon OpenSearch | Amazon MemoryDB, Google Cloud MemoryStore for Redis |
| 未包含的提供商 | Pinecone* | Couchbase*, ElasticSearch* | |
| 发现总结 | 纯粹提供商声称他们是专为向量设计的,但通常缺乏企业级功能和稳定性 | 成熟的通用数据库确实具备这些企业级功能,但性能较差 | 如果您认为 Redis 是您的解决方案,请注意其模仿者的性能不如 Redis |
我们根据客户的反馈选择了这些提供商,他们希望了解我们与这些提供商的竞争力以及他们在DB Engine 上的受欢迎程度。
* 我们也想分析 ElasticSearch、Pinecone 和 Couchbase,然而,这些数据库提供商的服务条款中包含DeWitt 条款,该条款在法律上限制任何形式的基准测试。具体来说,该条款不仅禁止发布基准测试结果,还禁止对其产品进行任何性能评估。因此,ElasticSearch、Pinecone 和Couchbase 的客户无法独立验证其潜在性能或有效性,对此没有任何了解。
我们在云服务解决方案中使用了相同的硬件对竞争对手进行了测试,包括客户端和服务器端。配置参数旨在公平分配相同数量的 vCPU 和内存。附录中的表格总结了测试的每种解决方案的资源类型。
重要的是要强调,我们付出了额外的努力,以确保所有竞争对手都有稳定且与其他基准数据来源一致的结果。例如,我们将 Qdrant 在云环境中的基准测试结果与Qdrant 发布的结果进行了比较,发现我们的测试结果要么与他们发布的结果相同,甚至有时更好。这使我们对现在分享的数据更有信心。下图显示了我们对 Qdrant 的测试结果与他们自行报告的结果的比较。

我们简化了提供商的配置设置,以确保公平比较。因此,我们比较了单节点和纯 k 近邻 (k-NN) 查询的基准测试。基准测试评估了不同引擎在相同资源限制下的性能,并展示了相对性能指标。
指标包括摄取和索引时间,以及单节点上的查询性能(吞吐量和延迟),使用不同向量维度和距离函数的各种数据集。特别是在查询性能方面,我们分析了以下两点:
我们的测试深入研究了各种性能指标,提供了 Redis 在向量数据库领域地位的整体视图。这些测试使用了两个主要操作:
对于所有参与基准测试的解决方案,我们在构建和运行时都将 M 的值设置为 16、32 和 64,将 EF 的值设置为 64、128、256 和 512。 为了确保结果的可重现性,每个配置都运行了 3 次,并选取了最佳结果。阅读更多关于 HNSW 配置参数和查询的信息。
通过将返回结果与之前为每个查询计算并作为每个数据集一部分提供的真实结果进行比较,来测量精度。
我们专注于分别测量摄取和查询性能。这种方法可以获得清晰、精确的见解,并使得将我们的结果与竞争对手的其他基准测试更容易进行比较,因为他们通常也独立测试插入和查询。我们计划在后续文章中讨论包含更新、删除和常规搜索的混合工作负载,以提供全面的视角。
考虑到不同基准测试解决方案过滤支持水平各不相同,我们目前不深入探讨过滤搜索基准测试的复杂性。过滤增加了显著的复杂性层,并且每个解决方案的处理方式都不同。我们在此不会深入讨论。
此外,我们正在积极扩展[在此处查看 PR] 基准测试工具,以涵盖每种解决方案的内存使用细分(对于任何 Redis 兼容的解决方案已有一个可用的示例),并允许进行数十亿向量的基准测试。
我们选择了以下数据集,以涵盖广泛的维度和距离函数。这种方法确保我们可以为各种用例提供有价值的见解,从简单的图像检索到大规模 AI 应用中复杂的文本嵌入。
| 数据集 | 向量数量 | 向量维度 | 距离函数 | 描述 |
| gist-960-euclidean | 1,000,000 | 960 | 欧几里得 | 图像特征向量是使用 Texmex 数据集和胃肠道间质瘤 (GIST) 算法生成的。 |
| glove-100-angular | 1,183,514 | 100 | 余弦 | 词向量是通过将 GloVe 算法应用于互联网上的文本数据生成的。 |
| deep-image-96-angular | 9,990,000 | 96 | 余弦 | 从 GoogLeNet 神经网络的输出层和 ImageNet 训练数据集提取的向量。 |
| dbpedia-openai-1M-angular | 1,000,000 | 1536 | 余弦 | OpenAI 使用 text-embedding-ada-002 模型生成的 DBpedia 实体文本嵌入数据集。 |
我们的基准测试是使用部署在我们基准测试基础设施中的 Amazon Web Services 实例上的客户端进行的。每个设置都包含向量数据库部署和客户端虚拟机。基准测试客户端虚拟机是一个 c6i.8xlarge 实例,配备 32 个 VCPU 和 10Gbps 网络带宽,以避免任何客户端瓶颈。基准测试客户端和数据库解决方案被放置在最佳网络条件下(同一区域),实现了稳态分析所需的低延迟和稳定的网络性能。
我们还对网络、内存、CPU 和 I/O 进行了基线基准测试,以便在适用时了解底层网络和虚拟机特性。在整个基准测试过程中,网络性能保持在测量限值以下,包括带宽和 PPS,以产生稳定、超低延迟的网络传输(每包 P99 < 100 微秒)。
本博客展示的基准测试结果,我们使用了Qdrant 的 vector-db-benchmark 工具,主要原因是该工具维护良好,并接受来自多个供应商(包括 Redis、Qdrant、Weaviate 等)的贡献,从而促进结果的可复现性。
此外,它允许进行多客户端基准测试,并且可以轻松扩展以包含更多供应商和数据集。
每种设置的详细配置可在我们的用于评估的基准测试仓库中找到。您可以按照这些步骤重现这些基准测试。
您可以亲身体验使用新的 Redis 查询引擎带来的更快搜索和向量数据库。该引擎现已在 Redis Software 中正式可用,并将在今年晚些时候登陆 Redis Cloud。如需立即为您的应用程序获得更快的搜索速度,请下载 Redis Software 并联系您的销售代表,以获得 16 倍以上的性能。
| 解决方案 | 设置类型 (软件或云) | 版本 | 设置 | 特别调优 |
| Redis | Redis Cloud | 7.4 | 底层使用 AWS m6i.2xlarge(8 核和 32GB 内存)的 Redis Cloud | 扩展因子设置为 4 (6x vCPU) |
| Qdrant | Qdrant Cloud | 1.7.4 | Qdrant Cloud (8 核和 32GB 内存) | 段数量可变,以实现更高 QPS 或更低延迟 |
| Weaviate | 软件 | 1.25.1 | ** 其云环境存在操作问题。使用软件版本 m6i.2xlarge(8 核和 32GB 内存) | |
| Milvus | 软件 | 2.4.1 | ** 其云环境存在操作问题。使用软件版本 m6i.2xlarge(8 核和 32GB 内存) | |
| Amazon Aurora | AWS 云 | PostgreSQL v16.1 和 pgvector 0.5.1 | db.r7g.2xlarge(8 核和 64GB 内存) | 我们测试了“Aurora 内存优化”和“Aurora 读取优化”两种实例 |
| MongoDB | MongoDB Atlas Search | MongoDB v7.0.8 | M50 通用部署(8 核和 32GB 内存) | 我们使用了写关注 (write concern) 为 1,读偏好 (read preference) 在主节点上的配置。 |
| Amazon OpenSearch | AWS 云 | OpenSearch 2.11 (lucene 9.7.0) | r6g.2xlarge.search(8 核和 64GB 内存) | 我们测试了 OpenSearch 默认的 5 个主分片设置和单分片设置。5 个分片设置被证明是 OpenSearch 获得最佳结果的配置。 |
| Amazon MemoryDB | AWS 云 | 7.1 | db.r7g.2xlarge(8 核和 53GB 内存) | |
| GCP MemoryStore for Redis | Google Cloud | 7.2.4 | 标准层级 36 GB |
Weaviate 和 Milvus 在针对给定数据集进行规模配置的云环境中表现出操作问题。具体而言:
鉴于上述问题,我们决定部署基于软件的 Milvus 和 Weaviate 解决方案,并分配与其他提供商相同的 CPU 和内存资源,即 8 个 VCPU 和 32GB 内存。
根据 Qdrant 索引结果,我们决定了解多个段对索引和查询性能的影响,并确认这是一个权衡。减少 Qdrant 上的段计数会导致更高的搜索 qps,但会降低精度并延长索引时间。如上所述,这是一个权衡。我们将 Qdrant 上的段计数调整到最低(2),注意到召回率确实降低了,但查询时的 qps 改进不足以赶上 Redis——Redis 在 KNN 搜索方面仍保持着巨大的优势。
具体针对我们运行的基准测试,Read Optimized 实例并未胜过 Memory Optimized 实例。这是因为在 PostgreSQL 中整个数据集都适合内存,这也得到了Amazon 公告的支持:
本地 NVMe 将仅缓存未修改的被逐出页面,因此如果您的矢量数据更新频繁,您可能看不到相同的加速效果。此外,如果您的矢量工作负载完全适合内存,您可能不需要 Optimized Reads 实例——但运行它可以帮助您的工作负载在相同实例大小上继续扩展。
目前,MongoDB Atlas Vector Search 不提供在索引创建期间配置 EF_CONSTRUCT 和 M 的方式,唯一可以提高精度的可配置选项是通过运行时 via the numCandidates config (i.e. EF_RUNTIME) 公开的。这种设计选择简化了用户体验,但限制了需要更高精度的用例的自定义和回复质量。即使遵循 Mongo 的官方文档
我们建议您指定一个高于要返回的文档数量(limit)的数字以提高准确性,尽管这可能会影响延迟。例如,对于仅返回一份文档的 limit,我们建议使用十到二十个最近邻居的比率。
并使用达到预期回复限制 20 倍的 numCandidates 配置(这意味着我们的最大 EF_RUNTIME 是 2000),MongoDB 解决方案的精度远非最佳,未超过 0.82。
关于垂直和水平扩展方法的说明:本文档展示了多个受益于垂直扩展的用例。然而,重要的是要注意,某些用例可能无法有效地扩展。为了确保更顺畅的扩展过程,我们将把垂直扩展反模式作为 Redis 文档的一部分进行记录,并且 Redis 专家将帮助客户了解垂直扩展是否会提升其用例性能,并指导他们是使用垂直扩展还是水平扩展。

