 Redis 8 已发布——它是开源的
Redis 8 已发布——它是开源的
了解更多

正在构建使用向量嵌入的应用?你可能已经经历了几个阶段:获取原始数据、尝试分块、将原始数据向量化,然后将向量上传到所选的向量数据库。
这个过程涉及许多步骤,这就是 VectorFlow 这样的工具派上用场的地方。
VectorFlow 是一个向量嵌入管道,有助于预处理你的数据并将其注入到向量数据库中。它减轻了手动执行数据分块和向量化所需的压力和时间。
在本文中,我们将结合 VectorFlow 和 Redis 来构建一个向量嵌入管道。Redis 将作为我们的向量数据库,而 VectorFlow 将处理其余任务。
在深入构建我们的管道之前,让我们先了解一下 VectorFlow。VectorFlow 是一个开源的向量嵌入管道,其代码库托管在 Github 上:https://github.com/dgarnitz/vectorflow。目前,它支持各种文件格式的图像和文本。VectorFlow 兼容多种嵌入模型,包括 OpenAI 嵌入等第三方嵌入模型。它还可以即时执行任何 Hugging Face Sentence Transformer 模型,而无需任何 API 密钥。
你可以在本地运行 VectorFlow,或使用其免费云服务。在本文中,我将在本地使用 VectorFlow。让我指导你完成设置。首先,我们将克隆其仓库
git clone https://github.com/dgarnitz/vectorflow.git
克隆仓库后,下一步是导航到其根文件夹并执行 setup.sh 命令。
cd vectorflow
./setup.sh
通过这个过程,你就可以在本地设置好 VectorFlow 了。
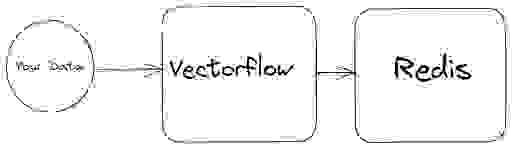
我们的非结构化文本数据将被输入到 VectorFlow 中。VectorFlow 将把文本数据分块。然后,它将使用选定的向量化模型将这些分块的部分转换为向量嵌入。为了演示,我将使用 OpenAI 的嵌入,这通常需要 API 密钥,但你可以选择任何 Hugging Face Sentence Transformer 模型。一旦生成嵌入,它们将存储在 Redis 向量数据库中。本例中,我们使用的是 Paul Graham 题为“What I Worked On”的文章,但你可以使用任何你喜欢的文本或图像数据。
你之前可能将 Redis 用作内存键值存储,甚至作为 NoSQL 数据库。然而,你可能不知道的是,Redis 也可以用作向量数据库。最快开始使用 Redis 的方法是使用 Redis Cloud。创建一个 Redis 账户并利用其免费计划。或者,你可以使用Redis Stack 在 Docker 上本地运行它。设置账户后,安装 Redis 客户端。你可以选择任何你喜欢的 Redis 客户端。在本文中,我将重点介绍使用 Redis Python 客户端。
!pip install redis
我们只需要三个参数即可连接到我们的 Redis 数据库。这些参数是
以下是将参数放入变量中
hostname = "redis-hostname"
port = 12345
password = "****"
让我们连接到我们的 Redis 数据库
r = redis.from_url(url = f'redis://{hostname}:{port}', password=password, decode_responses=True)
现在让我们测试一下连接。
r.ping()
如果你设置得当,这应该返回 True。
为了准备我们的 Redis 实例来处理向量嵌入,我们需要建立一个索引名称并为其分配一个前缀。前缀至关重要,因为它使我们能够在 Redis 中找到它。
INDEX_NAME = "vectorflow_idx"
DOC_PREFIX = "vec:"
接下来,我们需要为索引建立一个 schema。VectorFlow 强制使用标准 schema,包括以下内容
此 schema 将使用 Redis hash 数据结构存储在 Redis 中。id 将作为我们的哈希集合的键,而 source_data 和 source_document 将是 TextField。同时,embeddings 将被归类为 VectorField。
from redis.commands.search.field import VectorField, TextField
schema = (
TextField("source_data"),
TextField("source_document"),
VectorField("embeddings",
"HNSW", {
"TYPE": "FLOAT32",
"DIM": 1536,
"DISTANCE_METRIC": "COSINE",
}
),
)
根据我们的 schema 定义,让我们重点关注 VectorField 的定义。它首先接受字段名称,在本例中是“embeddings”。然后,它调用我们正在使用的算法,例如 HNSW(Hierarchical Navigable Small World)。第三个参数表示我们嵌入的配置。TYPE 参数定义向量字段的数据类型,DIM 参数确定嵌入字段的维度。这个值由你选择的向量化模型决定。我使用了 1536,因为我使用的是 OpenAI 嵌入。DISTANCE_METRIC 设置为 cosine。这些值都取决于你的具体配置。
# index Definition
definition = IndexDefinition(prefix=[DOC_PREFIX],
index_type=IndexType.HASH)
接下来,我们创建索引定义。在此定义中,我们指定索引是一个哈希集合。此外,我们指定了之前定义的索引前缀。
# create Index
r.ft(INDEX_NAME).create_index(fields=schema,
definition=definition)
然后,我们通过指定名称、其 schema 和先前建立的定义来创建索引。完成这些步骤后,我们的 Redis 数据库就准备好与 VectorFlow 协作了。
现在我们已经设置好 Redis 向量数据库,接下来使用 VectorFlow 进行数据注入,这通过 HTTP 端点完成。用于数据注入的端点是 embed/,这是一个 POST 端点。
让我们配置环境变量。我们需要三个不应暴露的秘密环境变量。
三个秘密环境变量是
%env VECTORFLOW_API_KEY=your-vectorflow-api-key
%env EmbeddingAPI_Key=your-openai-key
%env VectorDB_Key=your-redis-instance-password
然后,我们定义 VectorFlow URL。我使用的是 VectorFlow 的本地版本,但你的部署可能位于任何地方。
import os
url = "https:///embed"
headers = {
"Content-Type": "multipart/form-data",
headers: {
"Authorization": os.getenv('VECTORFLOW_API_KEY'),
"X-EmbeddingAPI-Key": os.getenv('EmbeddingAPI_Key')
"X-VectorDB-Key": os.getenv('VectorDB_Key'),
},
}
让我们定义元数据。在元数据中,我们指定嵌入元数据和向量数据库元数据。
data = {
'EmbeddingsMetadata':
'{"embeddings_type": "OPEN_AI", "chunk_size": 256, "chunk_overlap": 128}',
'VectorDBMetadata':
'{"vector_db_type": "REDIS", "index_name": "vectorflow_idx", "environment": "redis://redis-13952.c14.us-east-1-3.ec2.cloud.redislabs.com:13952", "collection": "vect"}'
}
在嵌入元数据中,我将块大小指定为 256,重叠大小为 128。由于我使用的是 OpenAI 嵌入,我已将嵌入类型指定为“OPEN_AI”。VectorDBMetadata 包含我们所有的向量数据库信息:向量数据库类型、我们的索引名称、集合(我们的索引前缀)以及来自我们环境的 Redis URL。
此设置对于为数据注入过程提供处理分块和嵌入的具体说明至关重要。
接下来,我们将下载数据。让我们编写一个函数来执行该任务。
def download_file(url, save_path):
response = requests.get(url)
if response.status_code == 200:
with open(save_path, 'wb') as file:
file.write(response.content)
print("File downloaded successfully")
else:
print(f"Failed to download the file. Status code: {response.status_code}")
然后,我们设置文件的 URL 目的地。
data_url = 'https://raw.githubusercontent.com/EteimZ/LLM_Stack/main/llama_index/pg-what-i-worked-on/data/paul_graham_essay.txt'
通过这个过程,我们应该已经获取了数据。接下来,我们需要将文件添加到一个包含 SourceData 键的字典中。
file = {"SourceData": open("paul_graham_essay.txt", "rb")}
现在我们已经收集了所有必要的组件,我们将使用之前指定的 url 向 embed 端点发出 POST 请求。我们将在该请求中传递我们的 headers、data 和文件。
response = requests.post(url, headers=headers, data=data, files=file)
然后我们检查响应文本
print(response.text)
我们应该会收到类似于这样的响应
{"JobID": 1, "message": "Sucessfully added 2 batches to the queue"}
当数据上传到 VectorFlow 时,它会被发送到一个后台工作进程,该进程管理所有的向量化过程。
要检查任务状态,请向端点 /jobs/<int:job_id>/status 发出 GET 请求。job_id 代表先前请求返回的 ID。
在我的例子中,我的请求将如下所示
!curl localhost/jobs/1/status
如果请求仍在进行中,你将收到如下响应
{"JobStatus": "IN_PROGRESS"}
如果进程完成,响应将如下所示
{"JobStatus": "COMPLETED"}
通过这个过程,你已成功将嵌入注入到 Redis 中。现在你可以将嵌入用于你选择的任何任务。
让我们总结一下我们已经完成的所有步骤。
import os
url = "https:///embed"
headers = {
"Content-Type": "multipart/form-data",
headers: {
"Authorization": os.getenv('VECTORFLOW_API_KEY'),
"X-EmbeddingAPI-Key": os.getenv('EmbeddingAPI_Key')
"X-VectorDB-Key": os.getenv('VectorDB_Key'),
},
}
data = {
'EmbeddingsMetadata':
'{"embeddings_type": "OPEN_AI", "chunk_size": 256, "chunk_overlap": 128}',
'VectorDBMetadata':
'{"vector_db_type": "REDIS", "index_name": "vectorflow_idx", "environment": "redis://redis-13952.c14.us-east-1-3.ec2.cloud.redislabs.com:13952", "collection": "vect"}'
}
file = {"SourceData": open("test_text.txt", "rb")}
response = requests.post(url, headers=headers, data=data, files=file)
print(response.text)
在进行任何项目时,选择合适的工具对其成功至关重要。VectorFlow 是一个相对较新的项目,并且它是开源的。因此,前往其 GitHub 仓库,给它一个 star,并查看其 issues。也许有一些问题你可以解决或贡献。




