 Redis 8 已推出——并且它是开源的
Redis 8 已推出——并且它是开源的

视频

在 LLM Chain 中使用 Redis VSS 作为检索步骤
了解更多

Google 的 Vertex AI 平台最近集成了生成式 AI 能力,包括 PaLM 2 对话模型和控制台内的生成式 AI Studio。本文将介绍一种新颖的参考架构,以及如何利用现有的 Redis 投资最大化这些工具的效益。
生成式 AI 作为 AI 领域快速增长的一个子集,因其改变整个行业的潜力而受到广泛关注。Google 的 Google Cloud Platform (GCP) 一直在努力普及生成式 AI 的访问,使其更易于采用,并通过强大的安全性、数据治理和可扩展性为其提供支持。
最近,Google 宣布 Vertex AI 支持生成式 AI,并推出了四种新的基础模型
应用生成、理解和处理人类语言的能力正变得至关重要。这种功能的需求遍及众多领域,从客户服务聊天机器人、虚拟助手到内容生成。而这得益于基础模型,例如 Google 的 PaLM 2,它们经过精心训练,能够生成类似人类的文本。
在这种动态环境中,创建高效、可扩展的语言模型应用有两个基本组成部分始终至关重要:基础模型和高性能数据层。
基础模型(大型语言模型 LLM 是其子集)是生成式 AI 应用的基石。LLM 在海量文本集合上训练,使其能够为各种任务生成上下文相关的、类似人类的文本。这些模型的改进使其更加复杂,从而对用户输入产生更精细、更有效的响应。选择的语言模型显著影响应用的性能、成本和整体质量。
然而,尽管 PaLM 2 等模型能力强大,它们也存在局限性。当缺乏特定领域的数据时,模型的关联性可能会减弱,并且可能无法及时反映最新或正确的信息。
LLM 在提示中处理的上下文长度(即 token 数量)存在硬性限制。此外,LLM 的训练或微调需要大量的计算资源,这会增加相当大的成本。
平衡这些局限性与潜在效益需要谨慎的策略和强大的基础设施。
高效的 LLM 应用依赖于可扩展、高性能的数据层。该组件确保低延迟的高速事务,这对于保持流畅的用户交互至关重要。它在缓存预计算的响应或向量(embeddings)、存储过去交互历史(持久化)以及执行语义搜索以检索相关上下文或知识方面发挥着关键作用。
向量数据库已成为数据层的一种流行解决方案。Redis 在当前浪潮兴起之前很久就投资了向量搜索,该技术反映了我们的经验——尤其是在性能方面的考虑。这一经验体现在刚刚发布的Redis 7.2 版本中,该版本包含可扩展搜索功能的预览,与之前版本相比,每秒查询次数提高了 16 倍。
鉴于基础模型和向量数据库在塑造不同行业的 LLM 应用中的关键作用,它们在业界引发了极大的兴趣(和炒作)。例如,一些较新的独立向量数据库解决方案,如 Pinecone,宣布获得了高额融资,并投入大量精力吸引开发者的注意。然而,随着每周都有新工具涌现,很难知道该信任哪一个才能满足企业级需求。
GCP 的独特之处在于其统一的产品。它将强大的基础模型与可扩展的基础设施以及一套用于调整、部署和维护这些模型的工具相结合。Google Cloud 高度重视可靠性、责任和强大的数据治理,确保最高级别的数据安全和隐私。在公开声明的AI 原则的指导下,GCP 倡导有益使用、用户安全和道德数据管理,提供可靠且值得信赖的应用基础。
然而,要真正利用这些进步,互补的高性能、可扩展的数据层必不可少。
自然而然,这就是 Redis 发挥作用的地方。 在后续章节中,我们将剖析这些核心组件,并通过参考架构探讨它们之间的交互。
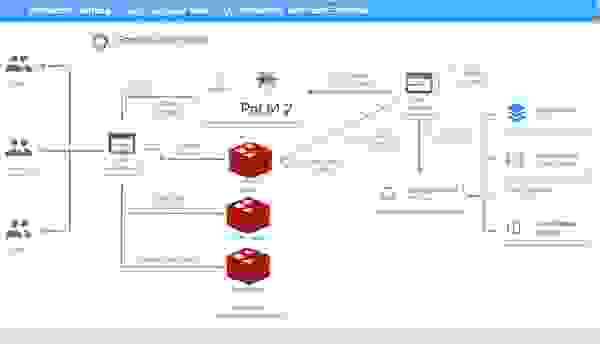
此处所示的参考架构适用于通用 LLM 用例。它结合使用了 Vertex AI (PaLM 2 基础模型)、BigQuery 和 Redis Enterprise。
GCP 和 Redis Enterprise 构建 LLM 应用的参考架构
您可以使用 开源 GitHub 仓库中的 Colab notebook,逐步按照本 LLM 架构的设置进行操作。
完成必要的设置步骤后,该架构即可为各种 LLM 应用提供支持,例如聊天机器人和虚拟购物助手。
即使是有经验的软件开发人员和应用架构师也可能在这个新的知识领域中感到迷失。这个简短的摘要应该能帮助您快速了解情况。
语义搜索从庞大的知识库中提取语义相似的内容。这取决于自然语言处理 (NLP)、PaLM 2 等基础模型以及向量数据库的能力。在此过程中,知识被转换为数值向量(embeddings),可以进行比较以找到与用户查询最相关的上下文信息。
Redis 作为高性能向量数据库,擅长索引非结构化数据,从而实现高效且可扩展的语义搜索。Redis 可以增强应用快速理解和响应用户查询的能力。其强大的搜索索引有助于实现准确、响应迅速的用户交互。
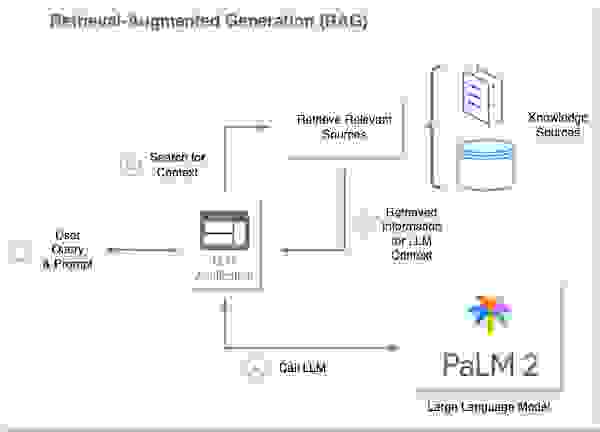
检索增强生成 (RAG) 方法使用语义搜索等技术,在将提示发送给 LLM 之前,动态地将事实知识注入其中。该技术最大限度地减少了对 LLM 进行私有或频繁变化数据微调的需求。相反,RAG 允许对 LLM 进行上下文增强,使其能够更好地处理手头的任务,无论是回答特定问题、总结检索到的内容还是生成新内容。RAG 通常在 agent 的范围内实现。
Agent 涉及 LLM 决定采取哪些行动,执行指定的行动,进行观察,并迭代直到完成。LangChain 为 agent 开发提供了通用接口。
Redis 作为向量数据库和全文搜索引擎,促进了 RAG 工作流程的顺利运行。由于其低延迟的数据检索能力,Redis 常常是首选工具。它确保语言模型快速准确地接收必要的上下文,从而提高 AI agent 任务执行的效率。
缓存是增强 LLM 响应能力和计算效率的有效技术。
标准缓存提供了一种机制,用于存储和快速检索重复查询的预生成响应,从而减少计算负载和响应时间。然而,在动态的人类语言对话环境中,完全匹配的查询很少见。这就是语义缓存发挥作用的地方。
语义缓存理解并利用查询的底层语义。语义缓存识别并检索与输入查询足够语义相似的缓存响应。这种能力极大地增加了缓存命中的可能性,从而进一步提高了响应时间和资源利用率。
例如,在客户服务场景中,多个用户可能会询问类似但措辞不同的常见问题。语义缓存允许 LLM 快速准确地响应此类查询,而无需进行冗余计算。
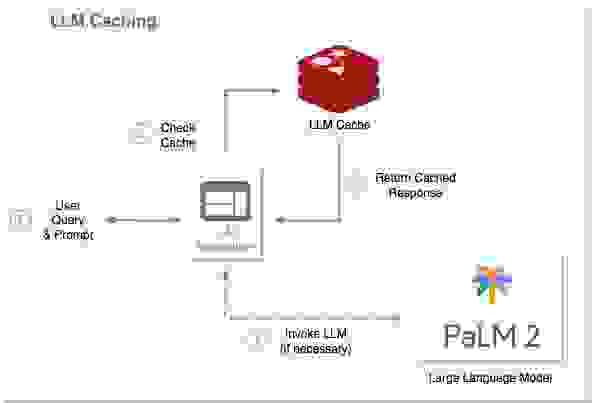
Redis 非常适合促进 LLM 的缓存。其强大的功能集包括支持 Time-To-Live (TTL) 和用于管理临时数据的逐出策略。结合其用于语义搜索的向量数据库功能,Redis 可以高效快速地检索缓存响应,即使在重负载下,也能显著提升 LLM 的响应速度和整体系统性能。
保留过去的交互和会话元数据对于确保上下文连贯和个性化的对话至关重要。然而,LLM 不具备自适应内存。这使得依赖可靠的系统来快速存储对话数据变得至关重要。
Redis 为管理 LLM 内存提供了强大的解决方案。即使在大量需求下,它也能高效地访问聊天历史记录和会话元数据。利用其数据结构存储,Redis 处理传统的内存管理,而其向量数据库功能则有助于提取语义相关的交互。
这有什么意义?谁需要这些功能?以下三个场景展示了这种 LLM 架构的实际应用。
有些企业需要处理海量文档,LLM 赋能的应用可以成为文档发现和检索的强大工具。语义搜索有助于从庞大的知识库中精确定位相关信息。
LLM 可以作为复杂的电子商务虚拟购物助手的骨干。通过上下文理解和语义搜索,它能够实时理解客户咨询,提供个性化产品推荐,甚至模拟对话交互。
将 LLM 部署为客户服务 agent 可以彻底改变客户互动。除了回答常见问题外,该系统还可以进行复杂的对话,提供定制化帮助,同时从过去的互动中学习。
一连串新产品和流行语很容易让人陷入“追逐新奇事物”综合症。在这片喧嚣中,GCP 和 Redis 的结合脱颖而出,不仅提供了创新的解决方案,还提供了可靠且经过时间考验的基础。
以事实为基础:GCP 和 Redis 使 LLM 应用不仅仅是高级文本生成器。通过在运行时从您自己的源快速注入特定领域的事实,它们确保您的应用提供符合事实、准确且有价值的交互,这些交互是专门针对您组织的知识库量身定制的。
架构简化:Redis 不仅仅是一个键值数据库;它是一个实时数据瑞士军刀。通过消除为不同用例管理多个服务的需要,它极大地简化了您的架构。作为许多组织已经信任用于缓存和其他需求的工具,Redis 在 LLM 应用中的集成感觉就像是无缝扩展,而不是新的采用。
性能优化:Redis 是低延迟和高吞吐量数据结构的代名词。当与 GCP 无与伦比的计算能力相结合时,您将拥有一个 LLM 应用,它不仅智能对话,而且响应迅速,即使在高需求场景下也是如此。
企业级就绪:Redis 不是新手。它是一个经过实战检验的开源数据库核心,在全球范围内为财富 100 强公司提供可靠服务。凭借其企业版产品可实现的五个九 (99.999%) 正常运行时间,并在 GCP 强大的基础设施支持下,您可以信任一个准备好满足企业需求的解决方案。
加速上市时间:通过 GCP Marketplace 轻松获取 Redis Enterprise,您可以将更多精力放在构建 LLM 应用上,而减少与设置相关的繁琐工作。这种易于集成的特性加速了上市时间,为您的组织带来竞争优势。
虽然新的向量数据库和生成式 AI 产品可能会在市场上制造很多噪音,但 GCP 和 Redis 的协同配合却奏响了不同的旋律——信任、可靠和稳定性能的旋律。这些久经考验的解决方案不会很快消失,它们已准备好为您的 LLM 应用提供支持,无论现在还是未来。
Redis 将于 8 月 29 日至 31 日在旧金山参加 Google Next ‘23 大会。我们诚邀您莅临 Redis 展位(#206),我们很乐意与您深入交流。
准备好现在就动手实践了吗?您可以通过 GCP Marketplace 设置 Redis Enterprise,并学习 入门教程。


