 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多

当我们需要将实时全文搜索添加到 Redis 文档站点时,我们选择了 RediSearch。RediSearch 模块中强大的搜索功能帮助我们将一个平淡无奇的表单变成了一个很棒的搜索体验。为了展示 RediSearch 的一些可能性并帮助您快速启动搜索项目,我想谈谈我们项目的架构并分享我们的代码。我们构建的 Python 应用程序称为 redis-sitesearch。如果您想查看代码或为您自己的站点运行它,它是开源的,您可以在 Redis Cloud Essentials 上免费试用 RediSearch。继续阅读以了解详细信息!

我们构建了一个新的搜索体验,因为我们的文档站点已经超出了我们之前的搜索引擎 Lunr.js 的能力。具体来说,我们希望从新的搜索体验中获得以下几点
我们知道 RediSearch 可以满足我们列表中的所有要求。(如果您不熟悉 RediSearch,它是一个出色的 Redis 查询和索引系统,并且包含强大的全文搜索功能。)因此,我们开始工作了。几周之内,我们就拥有了一个全新的搜索 API,为我们文档站点上的搜索提供支持。让我们从较高的层次了解一下项目的各个部分,然后再深入了解。
我们的文档搜索有两个主要部分:一个 JavaScript 前端,由 HTML 输入和搜索结果列表组成,以及一个 REST API 后端,用于查询 RediSearch。
在您键入时,前端会向后端 API 发出搜索请求并呈现结果。由于 Redis 是一个内存数据库,并且部署在多个区域,因此获得这些结果的速度非常快——在俄勒冈州的测试中,平均约为 40 到 50 毫秒。

我们知道人类认为低于 100 毫秒的响应时间是即时的,因此我们很高兴达到 40 毫秒 – 60 毫秒的范围。
然而,搜索应用程序内部究竟发生了什么才能实现这一点呢?以下是涉及的部分
这是一个关于这些部分如何组合在一起的图表
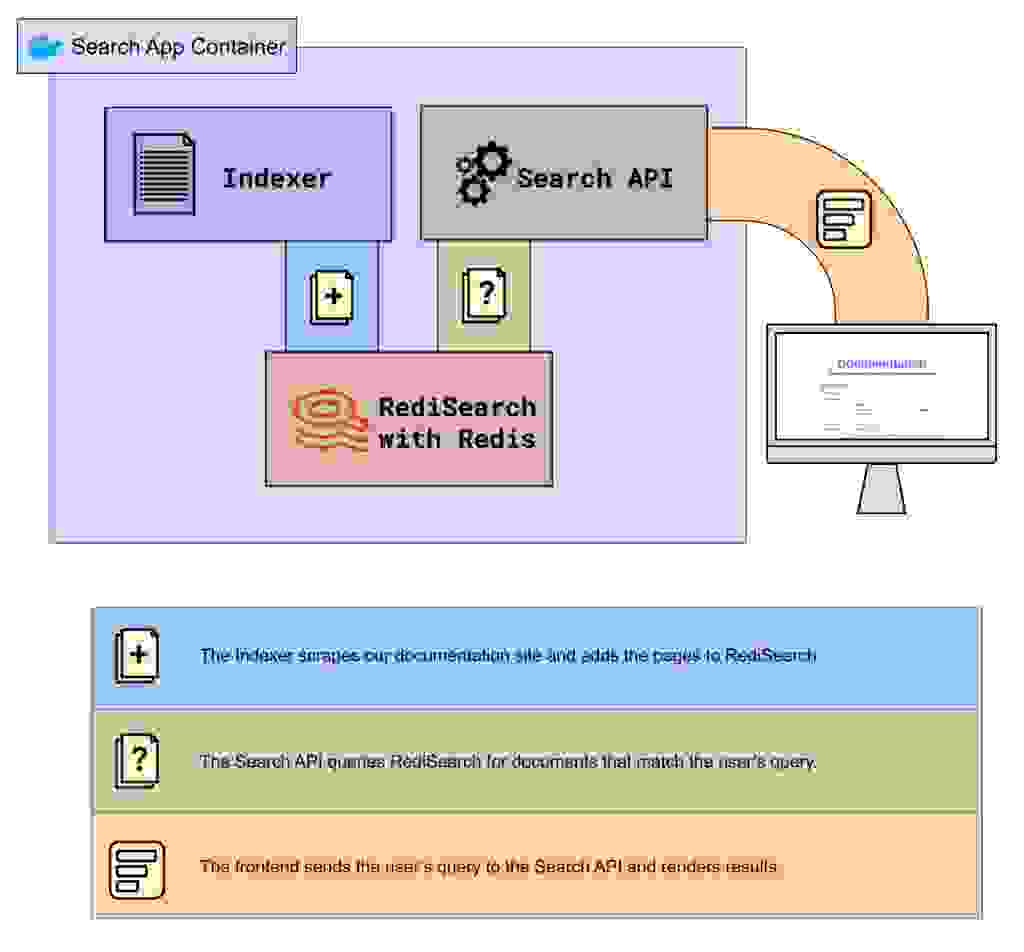
我们在 Google Cloud 上的容器内运行这些部分,并使用全球负载均衡器后面的多区域部署在全球范围内分发容器实例。
现在让我们详细了解后端应用程序中涉及的四个步骤
在我们可以处理任何搜索查询之前,我们需要索引我们的文档站点。为此,我们使用包含我们将用于搜索的所有字段的 RediSearch 索引定义。我们的 Python 应用程序中的一个后台作业会定期抓取文档站点,并将其内容添加到 RediSearch 索引中。让我们看看这两个部分是如何工作的。
索引定义
使用 RediSearch,您需要在进行任何查询之前创建一个索引定义。
RediSearch 索引与您的 Redis 数据库中的哈希保持同步。在 redis-sitesearch 应用程序中,我们为每个要添加到搜索索引的文档创建一个哈希。
然后,我们为要索引的站点创建一个 RediSearch 索引。每个索引都与键中与前缀 sitesearch:{environment}:{url}:doc: 匹配的哈希同步。目前,我们只索引我们的文档站点,但该设计允许我们使用相同的应用程序实例索引多个站点。索引定义采用一个 SCHEMA 参数,该参数定义了哪些哈希字段应该添加到索引中。redis-sitesearch 索引以下字段
使用 redisearch-python 客户端,模式如下所示
TextField("title", weight=10),
TextField("section_title"),
TextField("body", weight=1.5),
TextField("url"),
您可以看到我们已将“权重”添加到标题和正文字段。这意味着搜索查询将认为在这些字段中的命中比其他字段更相关。
索引作业
有了索引定义,我们需要一个后台作业来抓取我们的文档站点并创建 RediSearch 要索引的哈希。
为此,我们使用 Redis Queue 构建一个每 30 分钟运行一次的索引作业。此作业使用 Scrapy 库,我们已经使用自定义逻辑对其进行了扩展,以将抓取的页面内容解析为结构化数据。
使用 Scrapy 解析结构化页面数据
我们新的搜索体验的目标之一是显示我们在其中找到搜索结果的页面部分。例如,如果查询“gcp”在“帐户和团队设置”页面的“团队管理”部分中找到命中,我们希望在搜索结果中显示页面和部分。此搜索结果的屏幕截图显示了一个示例

在此屏幕截图中,“GCP”是命中,因此该术语以粗体呈现,这是 RediSearch 的 highlights 功能的一个示例。“帐户和团队设置”是我们找到命中的页面的标题,“团队管理”是包含命中的部分的名称。
我们通过将我们抓取的每个页面分解为 SearchDocument 对象来实现这一点。SearchDocument 是我们的应用程序用于表示我们想要使其可搜索的网页部分的域模型。
在 Scrapy 完成对站点的抓取后,我们将 SearchDocument 对象转换为 Redis 哈希。然后,RediSearch 在后台索引哈希。
对文档评分
当您创建一个密钥已配置为 RediSearch 索引的哈希时,您可以选择提供一个“__score”字段。如果您这样做,RediSearch 会将该文档在搜索查询中的最终相关性值乘以 __score。这意味着您可以在索引时对有关数据的某些相关性相关的事实进行建模。让我们回顾一下 redis-sitesearch 中的几个示例。
我们创建了 评分函数,以根据以下规则调整文档的分数
这种细粒度的控制是我们切换到 RediSearch 的主要原因。
验证文档
基于规则以不同的方式对文档进行加权有助于我们提高搜索命中的相关性,但我们希望避免完全索引某些类型的文档。我们的 验证器是简单的函数,用于根据任意逻辑决定是否索引 SearchDocument。我们使用这些来跳过发行说明和任何看起来像 404 页面的文档。
使用后台作业定期在 RediSearch 中索引我们的文档站点,我们终于可以构建我们的搜索 API 了!我们使用 Falcon Web 框架来构建 API,因为它的性能很快。
一个有效的搜索 API 将前端用户查询转换为 RediSearch 查询。RediSearch 支持数值范围、标签、地理过滤器和许多其他类型的查询。对于这个应用程序,最合适的选择是前缀匹配。通过前缀匹配,RediSearch 将索引中的所有术语与给定的前缀进行比较。如果用户在搜索表单中键入“red”,则 API 将发出前缀查询“red*”。
使用前缀匹配,“red*”将找到许多命中,包括
搜索表单将在用户键入时开始显示跨所有这些术语的命中的结果。当用户完成他们键入的短语时,结果将开始集中。如果最终搜索是“redisearch”,则应用程序将向 Redis 发出最后一个查询“redisearch*”,结果将特定于 RediSearch。

Google Cloud 使部署 redis-sitesearch 变得容易。我们将后端应用程序构建为 Google Cloud 的 单个容器 计算引擎,运行以下流程
我们将此容器部署到 Google Cloud 上美国西部、美国东部、苏黎世和孟买区域中的实例组。
注意:计算引擎每个节点只能运行一个容器,这就是为什么我们将 Python 应用程序与 Redis 一起运行。但是,这具有降低延迟的优势!
全球负载均衡器根据请求的地理来源和实例组中的当前负载将流量路由到这些实例。
我们希望为我们的用户提供最佳的文档搜索体验。而实现这一点的 RediSearch,就在我们眼前。
如果您正在构建全文站点搜索功能,请考虑 RediSearch。它将您的整个搜索索引保存在内存中,因此查询运行速度非常快。RediSearch 还可以按数值范围、地理半径等进行过滤。您甚至可以使用我们的开源 redis-sitesearch 代码库来快速启动您的项目。如果您想尝试 RediSearch 而无需自己托管,可以在 Redis Cloud Essentials 上免费使用。
想了解更多关于 RediSearch 的信息吗?观看我们最新的 YouTube 视频:在 Redis 中进行查询、索引和全文搜索。


