 Redis 8 来了,而且它是开源的
Redis 8 来了,而且它是开源的
了解更多

当用户坐在电脑前观看 Netflix 上的电影时,他们面临着数不清的 Netflix 用户曾面临过的问题:接下来看什么?幸运的是,如此多用户面临这个问题却又观看下一部电影的事实提供了一个解决方案:协同过滤。
通过协同过滤,推荐系统——通常由机器学习、深度学习和人工智能驱动——可以利用不同用户的互动,例如评分,来为其他用户提供推荐。
在理想世界中,这看起来像魔术。用户打开 Netflix,在不经意间,一个相似的用户之前选择了一部电影,而这个决定帮助推荐算法推断出原始用户可能喜欢什么。
但在内部,协同过滤绝非魔术。
协同过滤是构建推荐系统最早采用的方法之一。协同过滤的核心是依赖用户互动,例如用户评分、用户喜欢、用户不喜欢以及购买行为,来提供推荐。
协同过滤之所以得名,是因为这种方法允许用户通过隐式反馈相互“协作”。一个用户无需认识另一个用户,就可以通过对电影进行高评分来帮助他们,以便系统可以将其推荐给下一个用户。
很容易将推荐系统——那些似乎神奇地知道用户想购买、观看或接下来看什么的幕后工具——视为完全现代的系统。但推荐系统早在人工智能、机器学习和算法竞赛出现之前就已问世。
第一个推荐系统在万维网最初发明后不久就出现了。虽然其他更显眼的系统和概念曾席卷整个行业,然后又被更新的系统和概念所取代,但推荐系统却一直存在。多年来,相关技术的复杂性发生了巨大变化,但向活跃用户推荐新事物的挑战始终存在。
协同过滤分为两种方法:用户-用户和物品-物品。
在用户-用户(或基于用户)方法中,推荐系统通过寻找具有相似兴趣或品味的其他用户来预测用户的偏好,然后在此基础上推荐相似的物品。在物品-物品(或基于物品)方法中,推荐系统使用矩阵分解来根据新物品与用户已经表现出兴趣的旧物品的相似程度,向用户推荐新物品。
协同过滤并非构建推荐系统的唯一方法。
基于内容的过滤,与侧重于用户的协同过滤不同,它侧重于被推荐物品的内容。在基于内容的过滤中,机器学习算法根据物品的内容向用户推荐相似的物品。这些推荐系统随着时间的推移建立用户画像,并将新物品与这些画像匹配,希望能让用户也喜欢它们。
相比之下,协同过滤侧重于用户而非物品,并使用用户的显式反馈,而不是关于物品的隐式元数据。
每种方法都有其优缺点,但许多推荐系统会同时使用两者并将它们视为互补(例如在构建混合推荐系统时)。无论是侧重于其中一种还是将它们结合起来,了解每种方法的权衡对于构建现代推荐系统至关重要。
多年来,协同过滤凭借其众多优点,一直是推荐系统的重要组成部分:
尽管有这些引人注目的优点,协同过滤也并非没有缺点。
协同过滤存在一些主要的权衡,投入使用的公司需要加以考虑,特别是拥有较新网络的初创公司。
上述优缺点在实施后会更加凸显,您可以通过用例和示例来了解。
协同过滤的用例广泛而多样。与基于内容的过滤一样,协同过滤(以及所有其他推荐系统技术)都面临着同样的持续性问题:在线世界中总是有太多的选择,过多的选择会导致用户陷入分析瘫痪。
凡是可能出现这种动态的地方,您都可能找到推荐系统,而且通常特别是协同过滤。
协同过滤是一个古老的想法(至少在技术层面是如此),而且行业构建和迭代它的方法多年来一直在变化。学习自己构建协同过滤系统是构建或至少更好地理解现代推荐系统工作原理的绝佳第一步。
借助 Redis,您可以利用其实时、低延迟的能力构建可扩展的、由 AI 驱动的推荐系统。在需要实时数据处理才能做出最佳推荐的环境中,Redis 的亚毫秒级响应时间和矢量数据库能力可以帮助您提供无缝的用户体验。
在这里,我们将介绍如何使用 RedisVL 和 IMDB 电影数据集,构建一个由协同过滤支持的电影推荐系统。
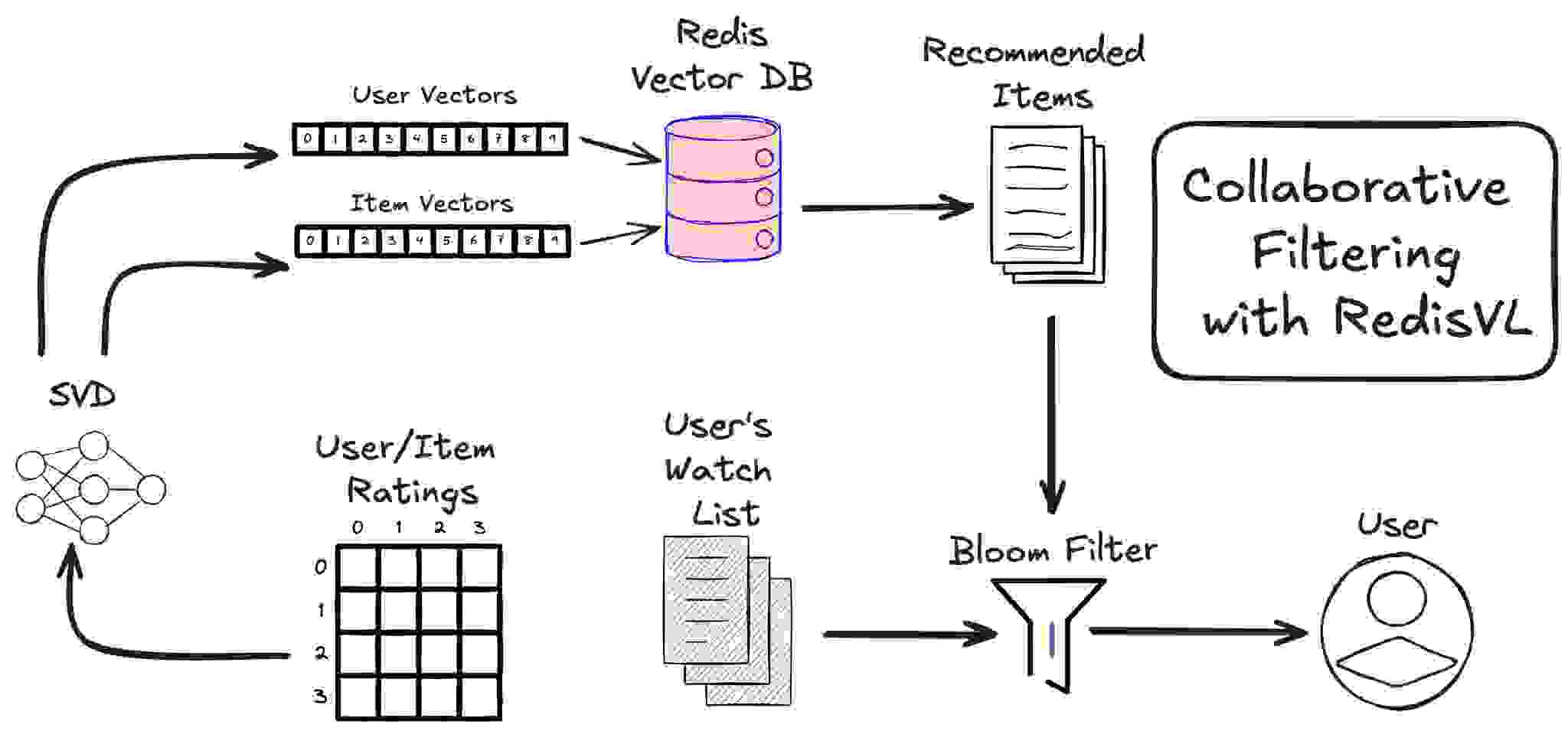
我们将使用的算法是奇异值分解(Singular Value Decomposition),即 SVD 算法。它通过查看用户对他们已经观看过的电影给出的平均评分来工作。下面是这些数据可能看起来的样子示例。
| 用户 ID | 电影 ID | 评分 (0 到 5) |
| 1 | 31 | 2.5 |
| 1 | 1029 | 3.0 |
| 1 | 1061 | 3.0 |
| 1 | 1129 | 2.0 |
| 1 | 1172 | 4.0 |
| 2 | 10 | 4.0 |
| 2 | 17 | 5.0 |
| 3 | 60 | 3.0 |
| 3 | 110 | 4.0 |
| 3 | 247 | 3.5 |
| 3 | 267 | 3.0 |
| 3 | 296 | 4.5 |
| 3 | 318 | 5.0 |
| … | … | … |
与基于内容的过滤(基于推荐物品的特征)不同,协同过滤着眼于用户的评分,并且仅着眼于用户的评分。
值得更详细地探讨一下为什么我们选择了这个算法,以及它在我们调用的方法中计算了什么。
首先,让我们思考一下它接收的数据是什么——我们的评分数据。这些数据只包含用户 ID、电影 ID 以及用户对他们观看过的电影(评分范围 0 到 5)的评分。我们可以将这些数据放入一个矩阵中,其中行代表用户,列代表电影。
| 评分矩阵 | 电影 1 | 电影 2 | 电影 3 | 电影 4 | 电影 5 | 电影 6 | … |
| 用户 1 | 4 | 1 | 4 | 5 | |||
| 用户 2 | 5 | 5 | 2 | 1 | |||
| 用户 3 | 1 | ||||||
| 用户 4 | 4 | 1 | 4 | ? | |||
| 用户 5 | 4 | 5 | 2 | ||||
| … |
我们的空单元格表示缺少评分,而不是零——所以用户 1 从未评价过电影 3。他们可能喜欢,也可能讨厌。
与基于内容的过滤不同,在这里,我们只考虑用户给出的评分。我们不知道这些电影的情节、类型或上映年份。然而,我们仍然可以通过假设用户的品味相似来构建推荐系统。
举一个直观的例子,我们可以看到用户 1 和用户 4 在几部电影上的评分非常相似,所以我们可以假设用户 4 会像用户 1 那样对电影 6 给出高分。
既然我们只有这个矩阵可以处理,我们想做的是将其分解成两个组成矩阵。
让我们将我们的评分矩阵命名为 [R]。我们想要找到另外两个矩阵,一个用户矩阵 [U] 和一个电影矩阵 [M],以符合方程
[U] * [M] = [R]
[U] 将看起来像
| 用户 1 特征 1 | 用户 1 特征 2 | 用户 1 特征 3 | 用户 1 特征 4 | … | 用户 1 特征 k |
| 用户 2 特征 1 | 用户 2 特征 2 | 用户 2 特征 3 | 用户 2 特征 4 | … | 用户 2 特征 k |
| 用户 3 特征 1 | 用户 3 特征 2 | 用户 3 特征 3 | 用户 3 特征 4 | … | 用户 3 特征 k |
| … | … | … | … | … | … |
| 用户 N 特征 1 | 用户 N 特征 2 | 用户 N 特征 3 | 用户 N 特征 4 | … | 用户 N 特征 k |
[M] 将看起来像
| 电影 1 特征 1 | 电影 2 特征 1 | 电影 3 特征 1 | 电影 4 特征 1 | … | 电影 M 特征 1 |
| 电影 1 特征 2 | 电影 2 特征 2 | 电影 3 特征 2 | 电影 4 特征 2 | 电影 M 特征 2 | |
| 电影 1 特征 3 | 电影 2 特征 3 | 电影 3 特征 3 | 电影 4 特征 3 | 电影 M 特征 3 | |
| 电影 1 特征 4 | 电影 2 特征 4 | 电影 3 特征 4 | 电影 4 特征 4 | 电影 M 特征 4 | |
| … | … | … | … | ||
| 电影 1 特征 k | 电影 2 特征 k | 电影 3 特征 k | 电影 4 特征 4 | 电影 M 特征 k |
这些特征是潜在特征(或潜在因子),也是我们在调用 svd.fit(train_set) 方法时试图找到的值。从我们的评分矩阵计算这些特征的算法就是 SVD 算法。
我们的数据确定了用户和电影的数量。潜在特征向量 k 的大小是我们选择的一个参数。对于这个笔记本,我们将保持其默认值 100。
获取评分文件并使用 Pandas 加载。
import os
import requests
import pandas as pd
from surprise import SVD
from surprise import Dataset, Reader
# we'll be downloading a few files for this example so here's a helper function
def fetch_dataframe(file_name):
try:
df = pd.read_csv('datasets/collaborative_filtering/' + file_name)
except:
url = 'https://redis-ai-resources.s3.us-east-2.amazonaws.com/recommenders/datasets/collaborative-filtering/'
r = requests.get(url + file_name)
if not os.path.exists('datasets/collaborative_filtering'):
os.makedirs('datasets/collaborative_filtering')
with open('datasets/collaborative_filtering/' + file_name, 'wb') as f:
f.write(r.content)
df = pd.read_csv('datasets/collaborative_filtering/' + file_name)
return df
# for a larger dataset use 'ratings.csv'
ratings_df = fetch_dataframe('ratings_small.csv')
# only keep the columns we need: userId, movieId, rating
ratings_df = ratings_df[['userId', 'movieId', 'rating']]
reader = Reader(rating_scale=(0.0, 5.0))
ratings_data = Dataset.load_from_df(ratings_df, reader)
下面的代码单元格中将发生许多事情。我们将完整数据分割为训练集和测试集。我们定义要使用的协同过滤算法,在此例中是奇异值分解 (SVD) 算法。最后,我们将模型拟合到我们的数据。
# split the data into training and testing sets (80% train, 20% test)
train_set, test_set = train_test_split(ratings_data, test_size=0.2)
# use SVD (Singular Value Decomposition) for collaborative filtering
svd = SVD(n_factors=100, biased=False) # we'll set biased to False so that predictions are of the form "rating_prediction = user_vector * item_vector"
# train the algorithm on the train_set
svd.fit(train_set)
现在 SVD 算法已经计算出我们的 [U] 和 [M] 矩阵(两者都只是向量列表),我们可以将它们加载到我们的 Redis 实例中。Surprise SVD 模型将用户和电影向量存储在两个属性中
svd.pu: 用户特征矩阵——一个矩阵,其中每行对应一个用户的潜在特征)。
svd.qi: 物品特征矩阵——一个矩阵,其中每行对应一个物品/电影的潜在特征)。
值得注意的是,矩阵 svd.qi 是我们在上面定义的矩阵 [M] 的转置。这样,每行就对应一部电影。
user_vectors = svd.pu # user latent features (matrix)
movie_vectors = svd.qi # movie latent features (matrix)
print(f'we have {user_vectors.shape[0]} users with feature vectors of size {user_vectors.shape[1]}')
print(f'we have {movie_vectors.shape[0]} movies with feature vectors of size {movie_vectors.shape[1]}')
we have 671 users with feature vectors of size 100
we have 8397 movies with feature vectors of size 100
协同过滤的一大优点是,利用我们的用户和电影向量,我们可以预测任何用户对数据集中任何电影的评分。而且与基于内容的过滤不同,它不假设推荐给用户的所有电影都彼此相似。用户可以获得关于黑暗恐怖片和轻松动画片的推荐。
回顾我们的 SVD 算法,方程是
[用户特征] * [电影特征].转置 = [评分]
要预测用户将如何评价他们尚未观看过的电影,我们只需要计算该用户特征向量与电影特征向量的点积。
# surprise casts userId and movieId to inner ids, so we have to use their mapping to know which rows to use
inner_uid = train_set.to_inner_uid(347) # userId
inner_iid = train_set.to_inner_iid(5515) # movieId
# predict one user's rating of one film
predicted_rating = np.dot(user_vectors[inner_uid], movie_vectors[inner_iid])
print(f'the predicted rating of user {347} on movie {5515} is {predicted_rating}')
the predicted rating of user 347 on movie 5515 is 1.1069607933289707
虽然我们的协同过滤算法仅根据用户对电影的评分进行训练,不需要关于电影本身的任何数据(例如片名、类型或上映年份),但我们仍然希望将这些信息存储为元数据。
我们可以从 `movies_metadata.csv` 文件中获取这些数据,进行清理,并通过 `movieId` 列将其与我们的用户评分连接起来。
# fetch and clean the movies data
import datetime
movies_df = fetch_dataframe('movies_metadata.csv')
movies_df.drop(columns=['homepage', 'production_countries', 'production_companies', 'spoken_languages', 'video', 'original_title', 'video', 'poster_path', 'belongs_to_collection'], inplace=True)
# drop rows that have missing values
movies_df.dropna(subset=['imdb_id'], inplace=True)
movies_df['original_language'] = movies_df['original_language'].fillna('unknown')
movies_df['overview'] = movies_df['overview'].fillna('')
movies_df['popularity'] = movies_df['popularity'].fillna(0)
movies_df['release_date'] = movies_df['release_date'].fillna('1900-01-01').apply(lambda x: datetime.datetime.strptime(x, "%Y-%m-%d").timestamp())
movies_df['revenue'] = movies_df['revenue'].fillna(0)
movies_df['runtime'] = movies_df['runtime'].fillna(0)
movies_df['status'] = movies_df['status'].fillna('unknown')
movies_df['tagline'] = movies_df['tagline'].fillna('')
movies_df['title'] = movies_df['title'].fillna('')
movies_df['vote_average'] = movies_df['vote_average'].fillna(0)
movies_df['vote_count'] = movies_df['vote_count'].fillna(0)
movies_df['genres'] = movies_df['genres'].apply(lambda x: [g['name'] for g in eval(x)] if x != '' else []) # convert to a list of genre names
movies_df['imdb_id'] = movies_df['imdb_id'].apply(lambda x: x[2:] if str(x).startswith('tt') else x).astype(int) # remove leading 'tt' from imdb_id
我们还需要将这些电影与其评分映射起来,我们将使用 `links_small.csv` 文件来完成,该文件匹配 `movieId`、`imdbId` 和 `tmdbId`。
links_df = fetch_dataframe('links_small.csv') # for a larger example use 'links.csv' instead
movies_df = movies_df.merge(links_df, left_on='imdb_id', right_on='imdbId', how='inner')
我们需要将 SVD 用户向量和电影向量及其对应的 userId 和 movieId 移至两个数据框中,以便后续处理。
# place movie vectors and their movieIds in a dataframe
movie_vectors_and_ids = {train_set.to_raw_iid(inner_id): movie_vectors[inner_id].tolist() for inner_id in train_set.all_items()}
movie_vector_df = pd.Series(movie_vectors_and_ids).to_frame('movie_vector')
# merge the movie vector series with the movies dataframe using movieId and id fields
movies_df = movies_df.merge(movie_vector_df, left_on='movieId', right_index=True, how='inner')
movies_df['movieId'] = movies_df['movieId'].apply(lambda x: str(x)) # need to cast to a string as this is a tag field in our search schema
movies_df.head()
his is a tag field in our search schema
movies_df.head()
特别是对于像我们这里处理的 45,000 部电影目录这样的大型数据集,您会希望 Redis 来完成矢量搜索的繁重工作。您只需要定义搜索索引并加载我们已经清理并与我们的向量合并的数据。
from redis import Redis
from redisvl.schema import IndexSchema
from redisvl.index import SearchIndex
client = Redis.from_url(<REDIS_URL>) # ex: "redis://:6379"
schema = {
"index": {
"name": "movies",
"prefix": "movie",
"storage_type": "json"
},
"fields": [
{"name": "title",
"type": "text",
},
{"name": "genres",
"type": "tag"
},
{"name": "revenue",
"type": "numeric"
},
{"name": "release_date",
"type": "numeric"
},
{"name": "popularity",
"type": "numeric"
},
{"name": "vote_average",
"type": "numeric"
},
{"name": "movie_vector",
"type": "vector",
"attrs": {
"dims": 100,
"distance_metric": "ip",
"algorithm": "flat",
"datatype": "float32"
}
}
]
}
movie_schema = IndexSchema.from_dict(schema)
movie_index = SearchIndex(movie_schema, redis_client=client)
movie_index.create(overwrite=True, drop=True)
movie_keys = movie_index.load(movies_df.to_dict(orient='records'))
为了提供完整的解决方案,我们也会将用户向量和他们观看过的列表存储在 Redis 中。我们不会搜索这些用户向量,因此无需为它们定义索引。直接的 JSON 查找即可。
from redis.commands.json.path import Path
# collect the user vectors and their userIds
user_vectors_and_ids = {train_set.to_raw_uid(inner_id): user_vectors[inner_id].tolist() for inner_id in train_set.all_users()}
# use a Redis pipeline to store user data and verify it in a single transaction
with client.pipeline() as pipe:
for user_id, user_vector in user_vectors_and_ids.items():
user_key = f"user:{user_id}"
watched_list_ids = ratings_df[ratings_df['userId'] == user_id]['movieId'].tolist()
user_data = {
"user_vector": user_vector,
"watched_list_ids": watched_list_ids
}
pipe.json().set(user_key, Path.root_path(), user_data)
pipe.execute()
与基于内容的过滤(我们希望计算物品之间的向量相似度并使用物品向量之间的余弦相似度来实现)不同,在协同过滤中,我们通过计算用户向量和电影向量的内积来尝试计算用户对电影的预测评分。
这就是为什么在我们的模式定义中,我们使用“ip”(内积)作为距离度量。这也是为什么我们在执行查询时,会使用我们的用户向量作为查询向量。距离度量“ip”(内积)计算的是
向量距离 = 1 – u * v
它返回最小值,对应于 u * v 的最大值。这正是我们想要的。然后,在 0 到 5 的范围内预测评分是
预测评分 = -(向量距离 - 1) = –向量距离 + 1
让我们随机选择一个用户及其相应的用户向量,看看它是怎样的。
from redisvl.query import RangeQuery
user_vector = client.json().get(f"user:{352}")["user_vector"]
query = RangeQuery(vector=user_vector,
vector_field_name='movie_vector',
num_results=5,
return_score=True,
return_fields=['title', 'genres']
)
results = movie_index.query(query)
for r in results:
# compute our predicted rating on a scale of 0 to 5 from vector distance
r['predicted_rating'] = - float(r['vector_distance']) + 1.
print(f"vector distance: {float(r['vector_distance']):.08f},\t predicted rating: {r['predicted_rating']:.08f},\t title: {r['title']}, ")
vector distance: -3.63527393, predicted rating: 4.63527393, title: Fight Club,
vector distance: -3.60445881, predicted rating: 4.60445881, title: All About Eve,
vector distance: -3.60197020, predicted rating: 4.60197020, title: Lock, Stock and Two Smoking Barrels,
vector distance: -3.59518766, predicted rating: 4.59518766, title: Midnight in Paris,
vector distance: -3.58543396, predicted rating: 4.58543396, title: It Happened One Night,
向量搜索处理了我们协同过滤推荐系统的大部分工作,是生成针对每个用户独有的个性化推荐的好方法。
为了进一步提升我们的推荐系统能力,我们可以使用 RedisVL 的过滤逻辑来更好地控制向用户展示的内容。既然可以拥有多个推荐电影列表,每个列表都有自己的主题并针对每个用户进行个性化,为什么只拥有一个呢?
from redisvl.query.filter import Tag, Num, Text
def get_recommendations(user_id, filters=None, num_results=10):
user_vector = client.json().get(f"user:{user_id}")["user_vector"]
query = RangeQuery(vector=user_vector,
vector_field_name='movie_vector',
num_results=num_results,
filter_expression=filters,
return_fields=['title', 'overview', 'genres'])
results = movie_index.query(query)
return [(r['title'], r['overview'], r['genres'], r['vector_distance']) for r in results]
Top_picks_for_you = get_recommendations(user_id=42) # general SVD results, no filter
block_buster_filter = Num('revenue') > 30_000_000
block_buster_hits = get_recommendations(user_id=42, filters=block_buster_filter)
classics_filter = Num('release_date') < datetime.datetime(1990, 1, 1).timestamp()
classics = get_recommendations(user_id=42, filters=classics_filter)
popular_filter = (Num('popularity') > 50) & (Num('vote_average') > 7)
Whats_popular = get_recommendations(user_id=42, filters=popular_filter)
indie_filter = (Num('revenue') < 1_000_000) & (Num('popularity') > 10)
indie_hits = get_recommendations(user_id=42, filters=indie_filter)
fruity = Text('title') % 'apple|orange|peach|banana|grape|pineapple'
fruity_films = get_recommendations(user_id=42, filters=fruity)
# put all these titles into a single pandas dataframe, where each column is one category
all_recommendations = pd.DataFrame(columns=["top picks", "block busters", "classics", "what's popular", "indie hits", "fruity films"])
all_recommendations["top picks"] = [m[0] for m in Top_picks_for_you]
all_recommendations["block busters"] = [m[0] for m in block_buster_hits]
all_recommendations["classics"] = [m[0] for m in classics]
all_recommendations["what's popular"] = [m[0] for m in Whats_popular]
all_recommendations["indie hits"] = [m[0] for m in indie_hits]
all_recommendations["fruity films"] = [m[0] for m in fruity_films]
all_recommendations.head(10)
| 精选 推荐 | 大片 | 经典 | 热门 | 独立热门 | 水果片 |
| 肖申克的救赎 | 阿甘正传 | 天堂电影院 | 肖申克的救赎 | 天空之城 | 恋恋笔记本 |
| 阿甘正传 | 沉默的羔羊 | 非洲女王 | 低俗小说 | 我的邻居龙猫 | 发条橙 |
| 天堂电影院 | 低俗小说 | 夺宝奇兵 | 黑暗骑士 | 西线无战事 | 愤怒的葡萄 |
| 两杆大烟枪 | 夺宝奇兵 | 帝国反击战 | 搏击俱乐部 | 黑暗军团 | 菠萝快车 |
| 非洲女王 | 帝国反击战 | 印第安纳琼斯与最后的十字军 | 爆裂鼓手 | 彗星美人 | 詹姆斯与大仙桃 |
| 沉默的羔羊 | 印第安纳琼斯与最后的十字军 | 星球大战 | 银翼杀手 | 这个杀手不太冷 | 香蕉 |
| 低俗小说 | 辛德勒的名单 | 满洲候选人 | 复仇者联盟 | 闪亮的风采 | 橙县 |
| 夺宝奇兵 | 指环王:国王归来 | 教父 2 | 银河护卫队 | 用心棒 | 万能金龟车 |
| 帝国反击战 | 指环王:双塔奇兵 | 天空之城 | 消失的爱人 | 白日美人 | 苹果饺子帮 |
您可能已经注意到,这些列表中有几部电影重复出现。这并不奇怪,因为我们所有的结果都是个性化的,而且像流行度、评分和收入这样的因素很可能高度相关。而且,我们期望得到特定用户高评价的推荐电影中,至少有一部分是他们已经观看并给予高评价的电影。
我们需要一种方法来过滤掉用户已经看过的电影以及我们之前已经推荐给他们的电影。我们可以使用查询中的 Tag 过滤器按电影 ID 进行过滤,但这很快就会变得很麻烦。
幸运的是,Redis 提供了一个简单的方法来保持推荐的新颖性和趣味性:布隆过滤器。
# rewrite the get_recommendations() function to use a bloom filter and apply it before we return results
def get_unique_recommendations(user_id, filters=None, num_results=10):
user_data = client.json().get(f"user:{user_id}")
user_vector = user_data["user_vector"]
watched_movies = user_data["watched_list_ids"]
# filter out movies that the user has already watched
client.bf().insert('user_watched_list', [f"{user_id}:{movie_id}" for movie_id in watched_movies])
query = RangeQuery(vector=user_vector,
vector_field_name='movie_vector',
num_results=num_results * 5, # fetch more results to filter out watched movies
filter_expression=filters,
return_fields=['title', 'overview', 'genres', 'movieId'],
)
results = movie_index.query(query)
matches = client.bf().mexists("user_watched_list", *[f"{user_id}:{r['movieId']}" for r in results])
recommendations = [
(r['title'], r['overview'], r['genres'], r['vector_distance'], r['movieId'])
for i, r in enumerate(results) if matches[i] == 0
][:num_results]
# add these recommendations to the bloom filter so they don't appear again
client.bf().insert('user_watched_list', [f"{user_id}:{r[4]}" for r in recommendations])
return recommendations
# put all these titles into a single pandas dataframe , where each column is one category
all_recommendations = pd.DataFrame(columns=["top picks", "block busters", "classics", "what's popular", "indie hits"])
all_recommendations["top picks"] = [m[0] for m in top_picks_for_you]
all_recommendations["block busters"] = [m[0] for m in block_buster_hits]
all_recommendations["classics"] = [m[0] for m in classics]
all_recommendations["what's popular"] = [m[0] for m in whats_popular]
all_recommendations["indie hits"] = [m[0] for m in indie_hits]
| 精选推荐 | 大片 | 经典 | 热门 | 独立热门 |
| 天堂电影院 | 满洲候选人 | 天空之城 | 搏击俱乐部 | 西线无战事 |
| 两杆大烟枪 | 玩具总动员 | 十二怒汉 | 爆裂鼓手 | 黑暗军团 |
| 非洲女王 | 教父 2 | 我的邻居龙猫 | 银翼杀手 | 彗星美人 |
| 沉默的羔羊 | 回到未来 | 一夜风流 | 消失的爱人 | 这个杀手不太冷 |
| 饮食男女 | 教父 | 伴我同行 | 超能陆战队 | 闪亮的风采 |
现在您已经了解了协同过滤的基础知识、这种方法的优缺点、各种用例和示例,以及如何使用 RedisVL 构建协同过滤系统。
使用 Redis 和 RedisVL,只需几个步骤即可构建一个高度可扩展、个性化、可定制的协同过滤推荐系统。如果您对如何构建基于内容的过滤推荐系统感兴趣,请务必查看相关内容。
免费试用 Redis 或预约演示,亲眼见证协同过滤和推荐系统的实际应用。

