 Redis 8 已发布——而且它是开源的
Redis 8 已发布——而且它是开源的
了解更多
让我们从数据科学基础开始,了解数据的概念、数据类型、主要特征以及数据对我们生活方式的影响。
数据是任何组织最有价值的资产。除了收集数据的显而易见的原因——客户记录、会计信息、项目信息以及知识型组织借以盈利的其他要素——数据还提供对客户行为、市场趋势和产品性能的洞察,有助于为资源分配决策提供信息。因此,公司经常投资收集或购买第三方数据,以获得相对于竞争对手的竞争优势。
数据是您收集的任何经过组织和结构化以便进行分析的信息。每次您购物、浏览网站、旅行、打电话或在社交媒体网站上发帖时,都会收集数据。数据可以来自许多来源,包括传感器、调查、实验、观察或现有记录(历史数据),例如金融交易。以前从未有过关于如此多不同事物的海量数据在每一天的每一秒被收集和存储。
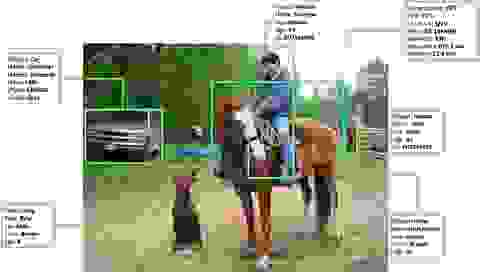
信息论将数据的概念向前推进了一大步。信息论是一个旨在理解信息本质和起源的研究领域。根据这项研究,万事万物都可以被视为数据。这包括物理对象以及思想或情感等抽象概念。此外,数据被定义为任何一组符号,当由接收者解释时能够传达意义。因此,任何具有某种符号表示形式(例如 DNA 序列、单词或数字)的事物在此语境下都可以被归类为数据。
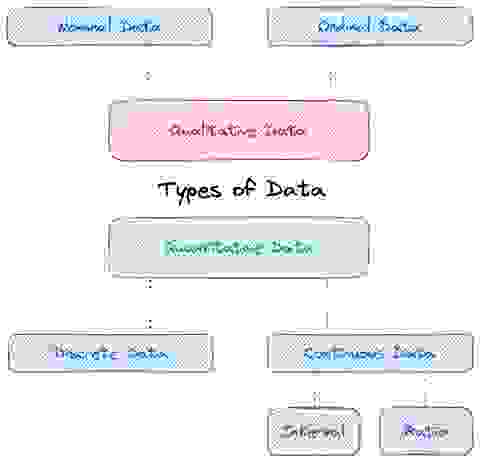
数据可以根据特定视角进行分类,例如根据价值、速度、结构、敏感性或任何其他特征进行分类。
从纯粹的统计学角度来看,数据根据其价值可以分为两大类。
定量(数值)数据是可以使用数值(例如整数或实数)表达、测量和比较的任何信息。
定量数据的例子包括身高、体重、长度、温度读数、人口规模或教室里的学生人数等可计数项目。这类数据可以进一步分为离散值(整数)或连续值(小数)。
定性(分类)数据是非数值信息,例如观点、感受、认知和态度。这类数据可以回答诸如“它是如何发生的?”或“为什么会发生?”等问题。定性数据的例子包括性别、排名和枚举。
这类数据可以分为名义数据或顺序数据。
从统计学上讲,定性变量在进行任何分析之前必须转换为虚拟变量。例如,我们可以人为地为类别分配数字。例如,如果您的类别是颜色,我们可以将数字 1 分配给红色,将 2 分配给蓝色,但这些数字在数学上没有任何意义。我们不会得出结论说蓝色是红色的两倍!
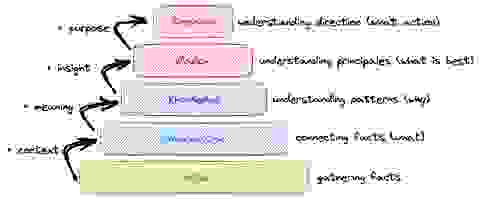
数据……信息……知识。有什么区别?DIKW 模型描述了数据、信息、知识和智慧之间的关系,它回答了这个问题以及潜在的问题:数据的最终目的是什么?
在 DIKW 模型中,数据被视为明智决策的原材料,因为它提供了得出结论的客观基础。通过各种方式分析大量数据,例如通过统计分析或机器学习算法,我们可以发现数据中以前可能不明显的模式。这些信息随后被处理成有意义的洞察,构成决策过程的基础。最后,当这些洞察与经验和判断相结合应用时,智慧就显现出来,这样人们就可以就下一步应采取的行动做出明智的选择,从而影响未来的策略。
因此,数据通过提供可用于做出明智决策的洞察和信息来增加价值。数据帮助组织识别趋势、衡量绩效、优化流程、改善客户体验和推动创新。它还通过基于数据分析的更好决策能力,使企业在市场中获得竞争优势。
我深深地欣赏数据所具有的力量和影响。在可比的标题下,以具体的数据证据来讨论问题,确实让任何团队都能基于信号、衡量指标和事实,全面而自信地预测业务发展。
在本世纪初,数据只从三个特征进行研究,称为数据的三个 V:体量(Volume)、速度(Velocity)和多样性(Variety)。随着时间的推移,又增加了两个 V——价值(Value)和真实性(Veracity),以帮助数据科学家和管理者更有效地阐述和沟通他们所处理数据的基本特征。
数据的五个主要和固有特征是
营销组织增加了另外两个数据特征,它们可以显著影响数据产生的洞察。这两个特征是
在一个组织中,数据的意义会不断变化,显著影响数据的同质化。这个概念不同于多样性。一家咖啡店可以提供六种不同混合的咖啡——这代表了多样性(Variety)——但你每天都喝同一种混合咖啡。但是可变性(Variability)捕捉的是即使在同一种混合咖啡中也可能出现的口味变化以及导致这些变化的因素,例如供应链状况、店内温度、水质和冲泡设备。

最终,今天的数据科学家关注数据的7 个 V——随着本系列文章的继续,您也会如此。
想将数据建模概念应用于您当前的项目吗?我们撰写了一本综合性的电子书 Redis 中的数据建模模式,其中详细介绍了八种场景,并展示了如何在 Redis 中对它们进行建模,附带代码片段。


