 Redis 8 发布了——它是开源的
Redis 8 发布了——它是开源的
了解更多

您可能知道,在 AWS 上使用持久化存储运行 Redis 对用户来说一直是一个挑战。本地存储缺乏数据持久性,而标准的 EBS 被认为速度慢且不可预测。最近在 Redis 社区中的一次讨论建议用户将默认的 Redis 配置更改为 AOF 并设置“fsync every second”,以获得比当前默认快照策略更好的数据持久性。由于许多 Redis 用户在 AWS 上运行,反对更改配置的一个论点是 EBS 被认为速度慢,并且 AOF 在存储访问方面比快照要求高得多。作为 Redis Cloud 的提供商,我们决定找出 EBS 在各种 AWS 平台下使用时是否真的会降低 Redis 的速度。 Redis 数据持久性: Redis 的 AOF 和快照持久化存储机制非常高效,因为它们只使用顺序写入,没有寻道时间。因此,即使在非 SSD 硬件上,Redis 也可以很好地运行数据持久化。话虽如此,慢速存储设备仍然可能给 Redis 带来很大的痛苦。当 AOF 的“fsync every second”策略因慢速磁盘 I/O 阻塞整个 Redis 操作时,我们看到了这一点。此外,用于时间点快照或 AOF 重写的后台保存需要更长时间,这会导致用于写时复制(copy-on-write)的内存更多,从而留给应用程序的内存更少。 测试启用和禁用持久化存储的 Redis: 我们进行了最新的基准测试,以了解 AWS 上每种典型 Redis 配置在启用和禁用持久化存储下的性能表现。我们测试了 AOF 的“fsync every second”策略,因为我们认为这是最常见的数据持久化配置,能够很好地平衡性能和数据持久性。事实上,我们超过 90% 启用数据持久化的 Redis 用户都使用 AOF 和“fsync every second”。虽然这是一种常见的 Redis 配置,但我们没有测试主节点从 RAM 提供所有数据,而将数据持久化交给从节点的设置。这种配置可能导致主从节点之间复制瓶颈等问题,这些问题与我们要测试的存储瓶颈没有直接关系。此外,Redis fork、AOF 重写和快照操作的影响将留待我们后续文章讨论,敬请期待! 基准测试结果 以下是我们在比较每个平台启用和禁用数据持久化(w/o DP)时的发现。 吞吐量 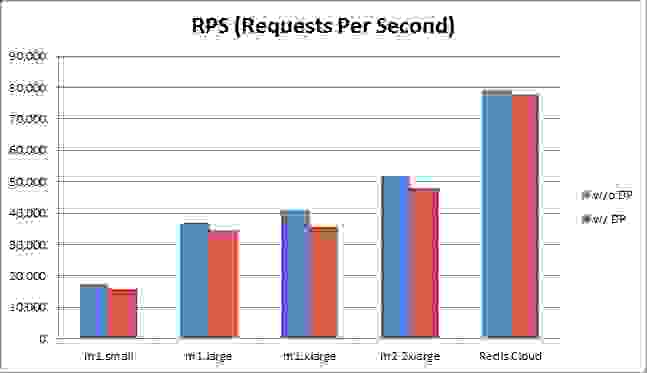
所有平台在不启用数据持久化 (w/o DP) 的情况下运行得更快一些,但差异非常小:使用 m1.xlarge 实例时快了 15%,其他实例快了等于或小于 8%,Redis Cloud 平台快了大约 1%。注意:默认情况下,Redis Cloud 为其每个集群节点使用一个 RAID 配置的 EBS(更多设置详情请参阅本文末尾),但在本次基准测试中,我们对所有其他平台使用了非 RAID 配置。因此,可以安全地假设更优化的 EBS 配置可以减少性能下降。延迟 
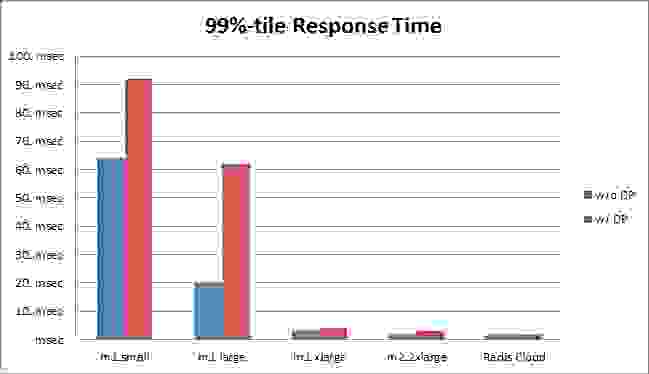
使用 m1.xlarge 实例并启用数据持久化时,平均响应时间高了 13%,所有其他实例高了小于 8%。同样,由于 Redis Cloud 的 EBS 配置最优,启用数据持久化时的平均响应时间仅高了 2%。在 99% 分位响应时间方面,m1.small 和 m1.large 实例出现了显著的延迟差距,这主要是因为这些实例比 m2.2xlarge 和 m2.4.xlarge 等大型实例更有可能在物理服务器上共享,正如 Adrian Cockcroft 在此处出色解释的那样。另一方面,m1.xlarge 和 m2.2xlarge 实例的延迟略高,而 Redis Cloud 的响应时间相同。注意:我们的响应时间测量考虑了网络往返时间、Redis/Memcached 处理时间以及我们的 memtier_benchmark 工具解析结果所需的时间。AOF 应该成为 Redis 的默认配置吗? 我们认为是这样。本次基准测试清楚地表明,在各种 AWS 平台上使用 AOF 和标准的非 RAID EBS 配置运行 Redis 在正常条件下不会显著影响 Redis 的性能。如果我们考虑到 Redis 专业人士通常会在使用任何数据持久化方法之前仔细调整其 redis.conf 文件,并且新手通常不会产生像我们在本次基准测试中使用的那么大的负载,那么可以安全地假设这种性能差异在实际场景中几乎可以忽略不计。为什么 Redis Cloud 的性能好得多?
启用数据持久化后,m1.xlarge 实例的平均响应时间增加了 13%,其他所有实例的平均响应时间增加了不到 8%。同样,由于 Redis Cloud 的优化 EBS 配置,启用数据持久化后的平均响应时间仅增加了 2%。m1.small 和 m1.large 实例在 99%-tile 响应时间上出现了显著的延迟差异,这主要是因为这些实例比 m2.2xlarge 和 m2.4xlarge 等大型实例更有可能在物理服务器上共享,正如 Adrian Cockcroft 在此处精彩解释的那样。另一方面,m1.xlarge 和 m2.2xlarge 实例的延迟增加非常小,而 Redis Cloud 的响应时间则持平。 注意:我们的响应时间测量考虑了网络往返时间、Redis/Memcached 处理时间,以及我们的 memtier_benchmark 工具解析结果所需的时间。 AOF 应该成为默认的 Redis 配置吗? 我们认为是的。此基准测试清楚地表明,在各种 AWS 平台上使用 AOF 和标准的非 RAID EBS 配置运行 Redis 在正常情况下不会显著影响 Redis 的性能。如果我们考虑到专业的 Redis 用户在使用任何数据持久化方法之前通常会仔细调整他们的 redis.conf 文件,并且新手通常不会产生像我们在此基准测试中使用的那样大的负载,那么可以肯定地说,在实际场景中,这种性能差异几乎可以忽略不计。 为什么 Redis Cloud 的性能要好得多?
在后台,我们监控每一个 Redis 命令,并不断将其响应时间与最优值进行比较。这种架构让我们的客户无论数据集大小(包括中小型)如何,都能在最强大的实例上运行并享受最高的性能。通过 Garantia Data,他们可以在每小时仅按实际使用的 GB 付费的情况下做到这一点——从而获得两全其美的优势。 基准测试设置 对于想了解更多基准测试详情的人,以下是我们使用的资源
自建 (DIY) Redis
这是我们用于生成负载的设置
 对于每个测试的平台,我们运行了 2 个测试
对于每个测试的平台,我们运行了 2 个测试
