 Redis 8 来了——而且它是开源的
Redis 8 来了——而且它是开源的
了解更多

要构建像金融领域的 RAG 这样有效的问答系统,你需要一个理解该行业词汇的模型。通用嵌入模型通常缺乏准确检索信息所需的领域特定知识。
微调正是为此而来。使用金融数据集训练领域特定的嵌入模型,或使用为金融文本构建的预训练模型,有助于系统根据用户查询检索准确、相关的信息。
让嵌入模型真正理解医学、法律或金融等专业领域,仅靠现成解决方案是不足够的。本指南将逐步介绍如何使用领域特定数据集进行微调,以捕捉细微的语言模式和概念。其回报是在你的领域中实现更准确的检索和更强大的 NLP 性能。

嵌入是将文本、图像或音频映射到多维空间中以捕捉语义关系的数值表示。在这个空间中,相似的项目(例如,单词或短语)位置更接近,反映了它们的语义相似性,而不同的项目则相距更远。这种结构使得嵌入在自然语言处理、图像识别和推荐系统等任务中非常强大。
嵌入对于许多 NLP 任务至关重要,例如
由北京人工智能研究院 (BAAI) 开发的 BAAI/bge-base-en-v1.5 模型是一款通用文本嵌入模型,在 NLP 任务中表现出色。它在 MTEB 和 C-MTEB 等基准测试中表现良好,特别适用于计算资源有限的应用。
为特定领域微调嵌入模型可以通过将模型的相似性指标与领域特定上下文和语言对齐来增强检索增强生成 (RAG) 系统。这提高了相关文档的检索效率,从而产生更准确、更符合上下文的响应。
损失函数对于训练嵌入模型至关重要,因为它们衡量模型预测与实际标签之间的差异,指导权重调整。不同的损失函数适用于各种数据集格式
我们将使用 unstructured 库从 PDF 文件中提取文本和表格。
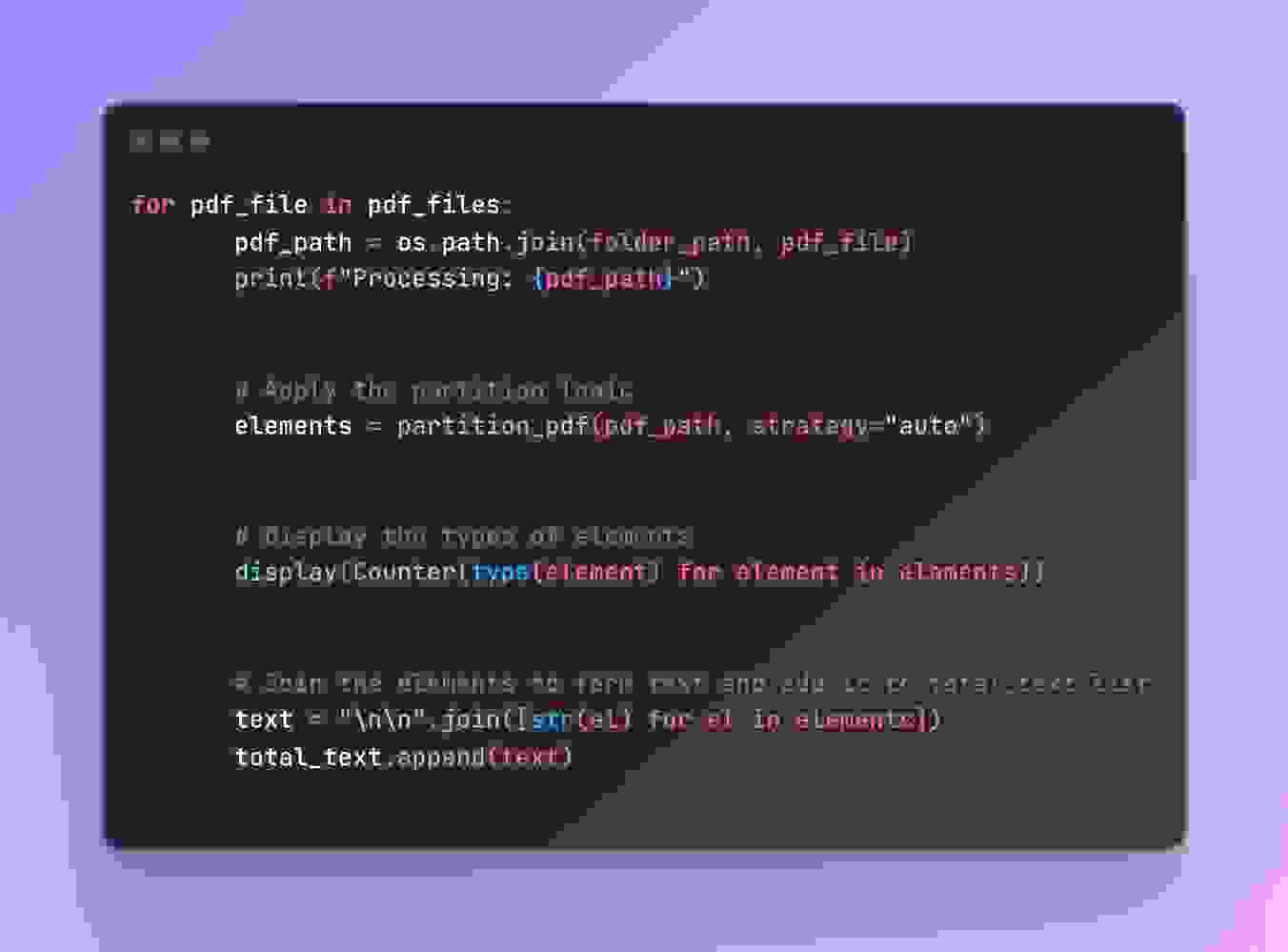
使用 LangChain 将提取的文本分解为可管理的小块。这对于使文本更适合 LLM 处理至关重要。

为 Hugging Face Llama 模型创建一个提示,要求根据给定的文本块生成一个问题-答案对。
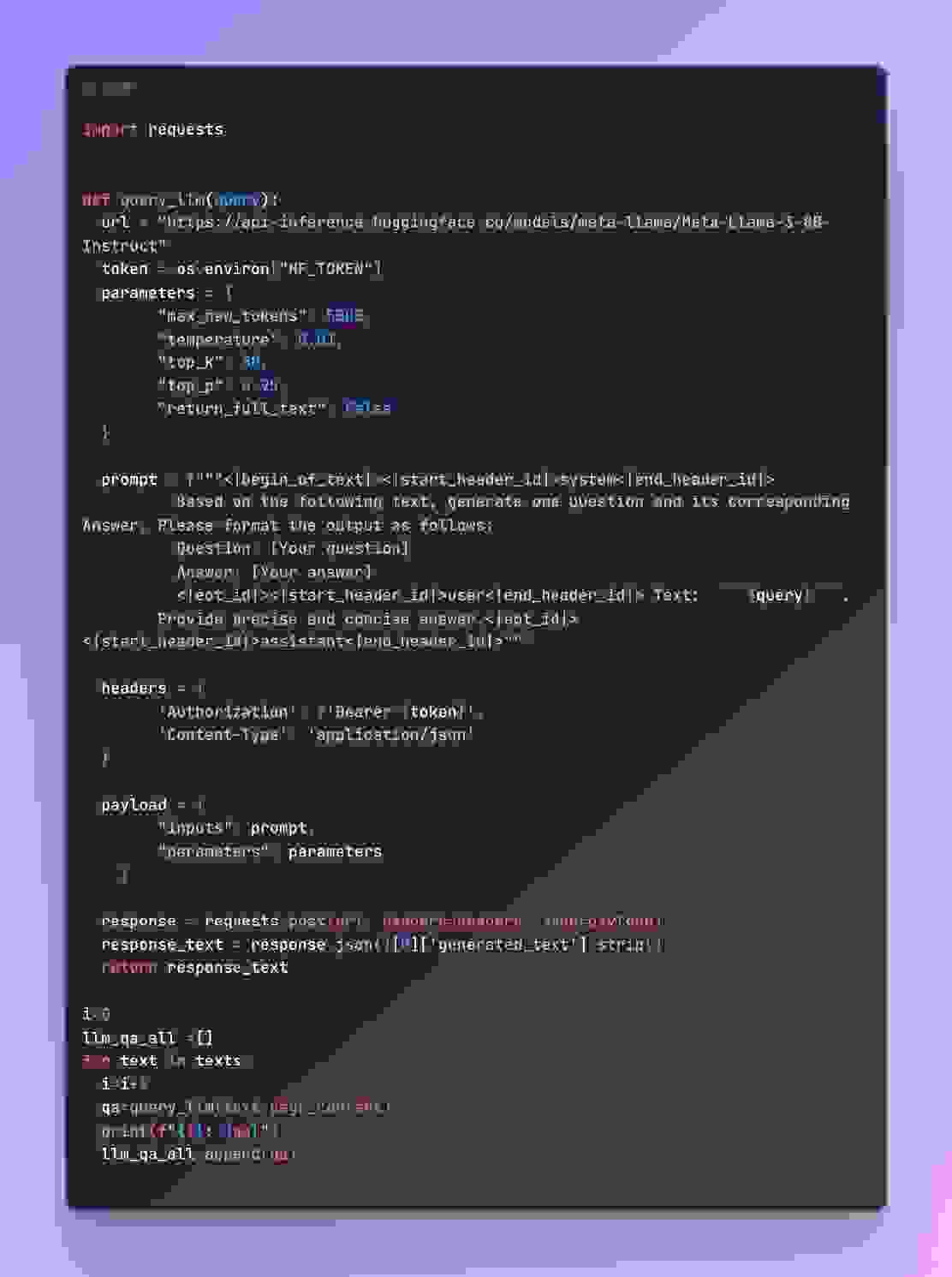
问题:2004 年 NVIDIA 公司 10-K 报告的提交日期是多久?
答案:2004 年 NVIDIA 公司 10-K 报告的提交日期是 5 月 20 日、3 月 29 日和 4 月 25 日。
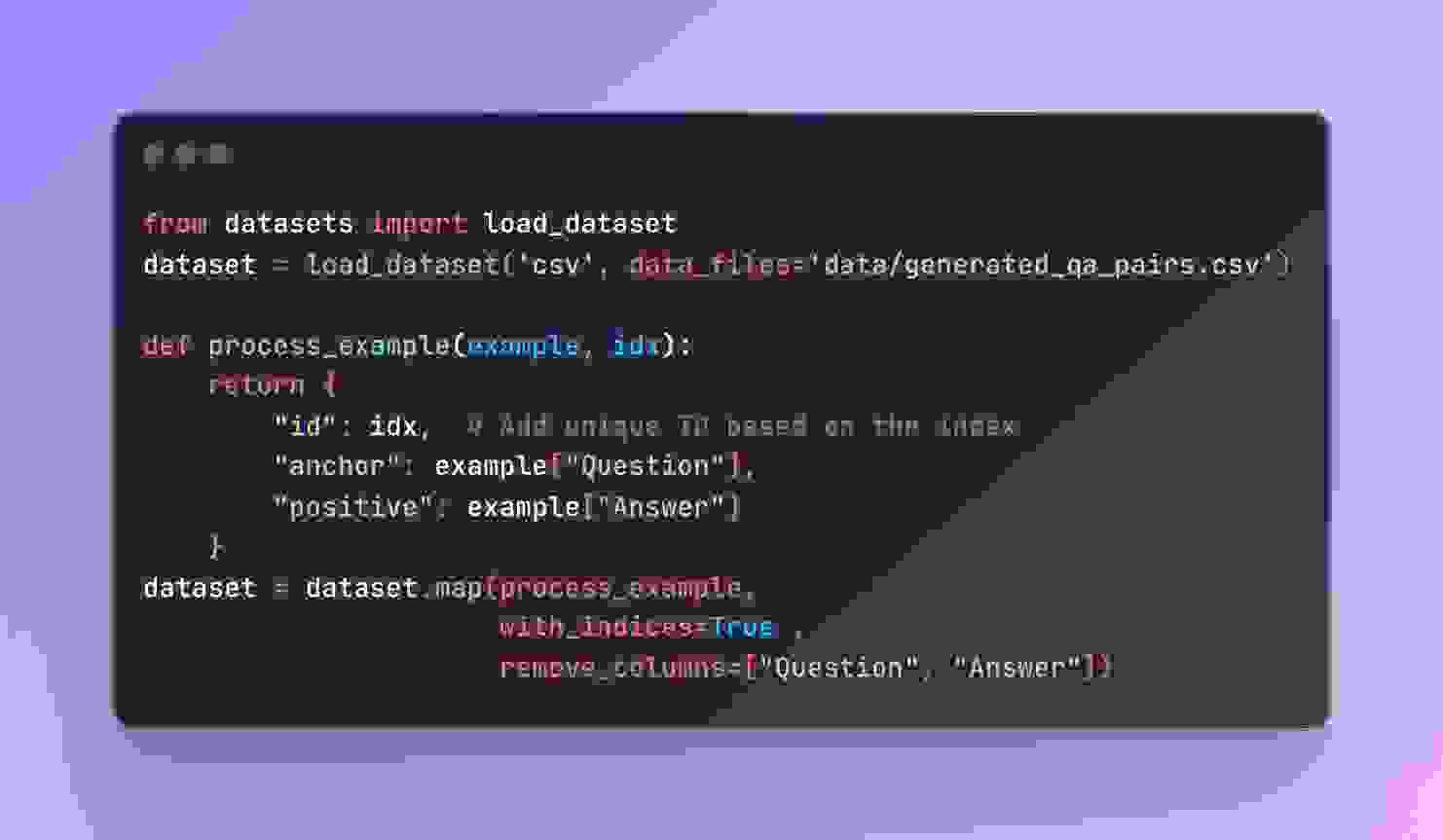
接下来,将从 CSV 文件生成的 QA 对加载到 HuggingFace 数据集中。我们确保数据格式正确,以便进行微调。
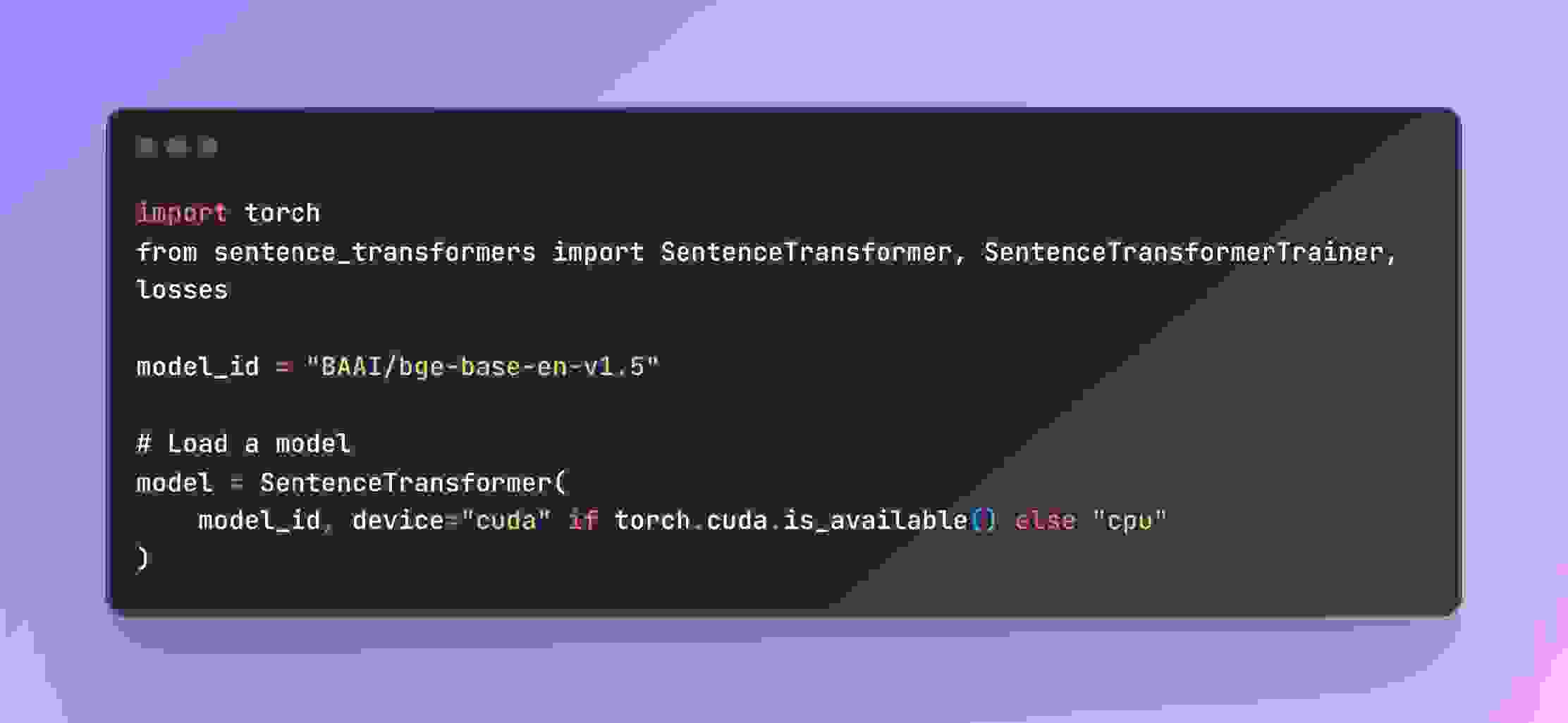
使用 sentence_transformers 从 Huggingface ( BGE: 用于搜索和 RAG 的一站式检索工具包 ) 加载 bge-base-en-v1.5。
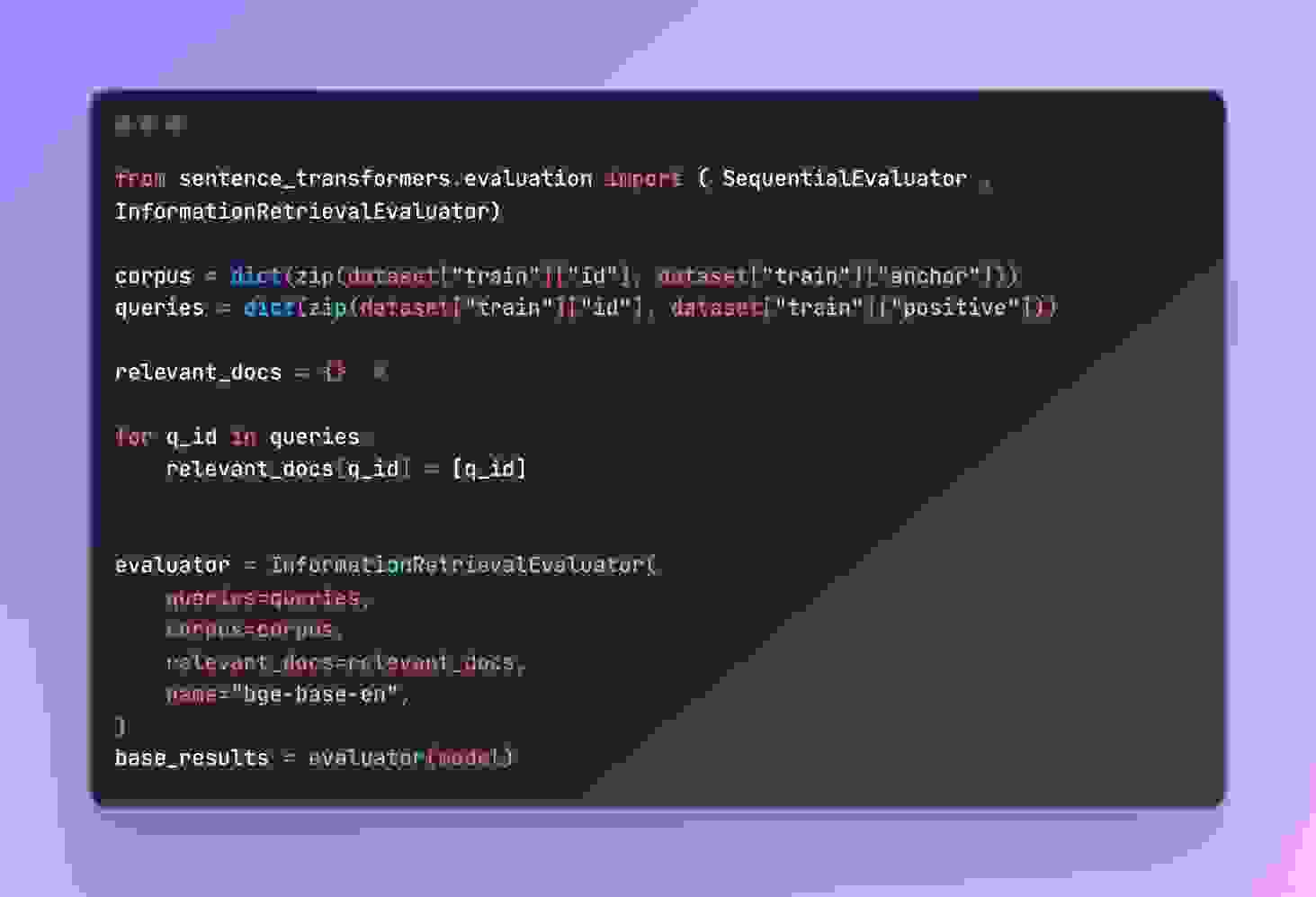
创建一个 InformationRetrievalEvaluator 评估器,用于衡量模型在训练期间的性能。评估器使用 InformationRetrievalEvaluator 评估模型的检索性能。
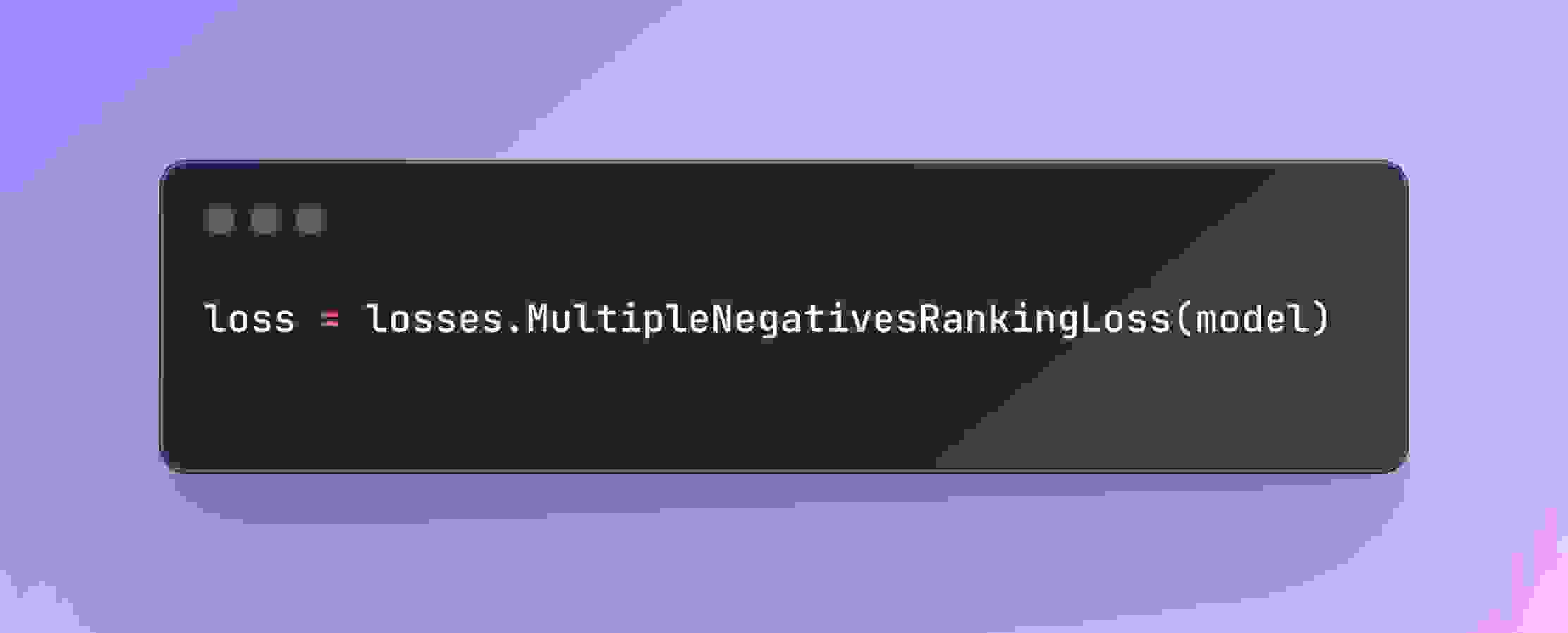
损失函数 MultipleNegativesRankingLoss 有助于模型生成适合检索任务的嵌入。
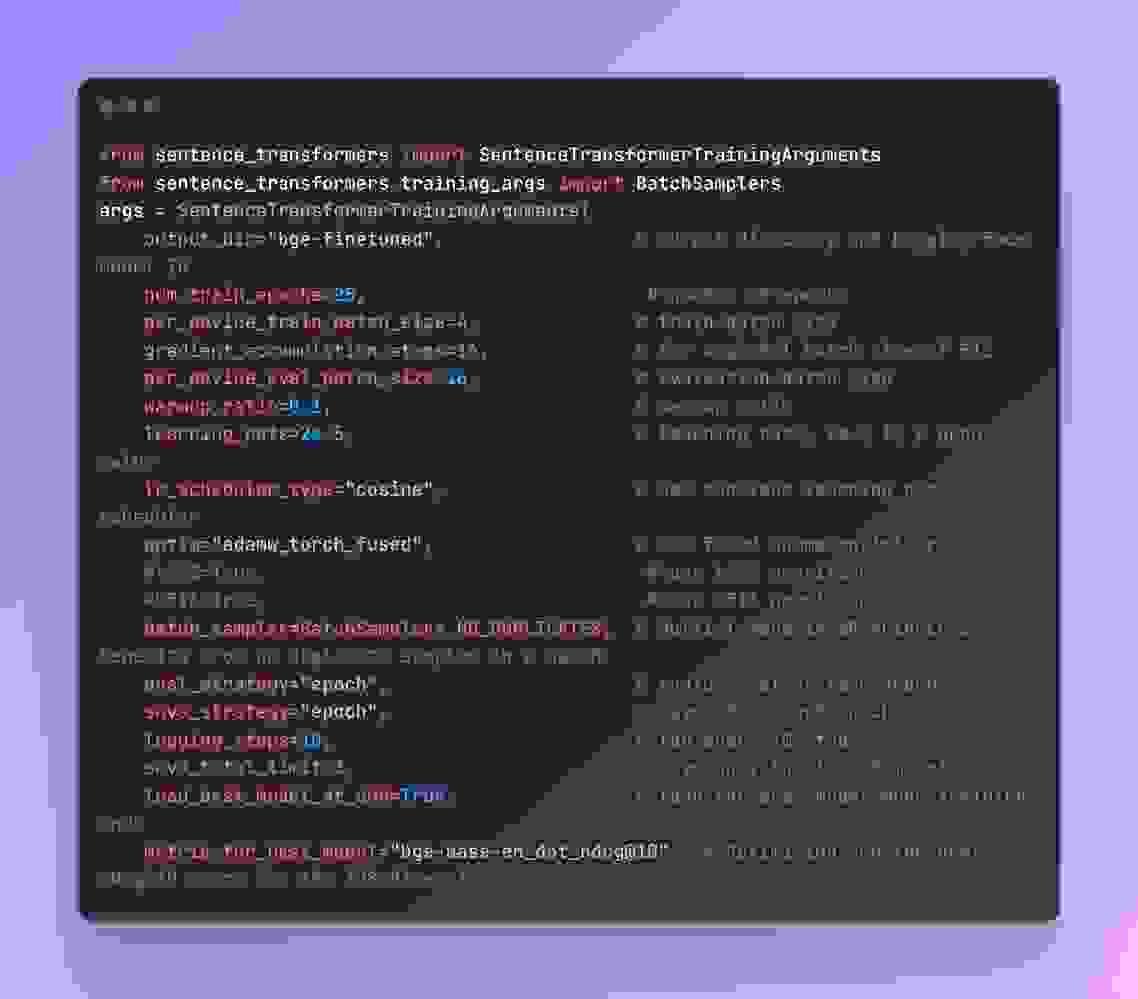
使用 SentenceTransformerTrainingArguments 定义训练参数。这包括
metric_for_best_model=”bge-base-en_dot_ndcg@10″, # 针对 128 维度的最佳 ndcg@10 分数进行优化
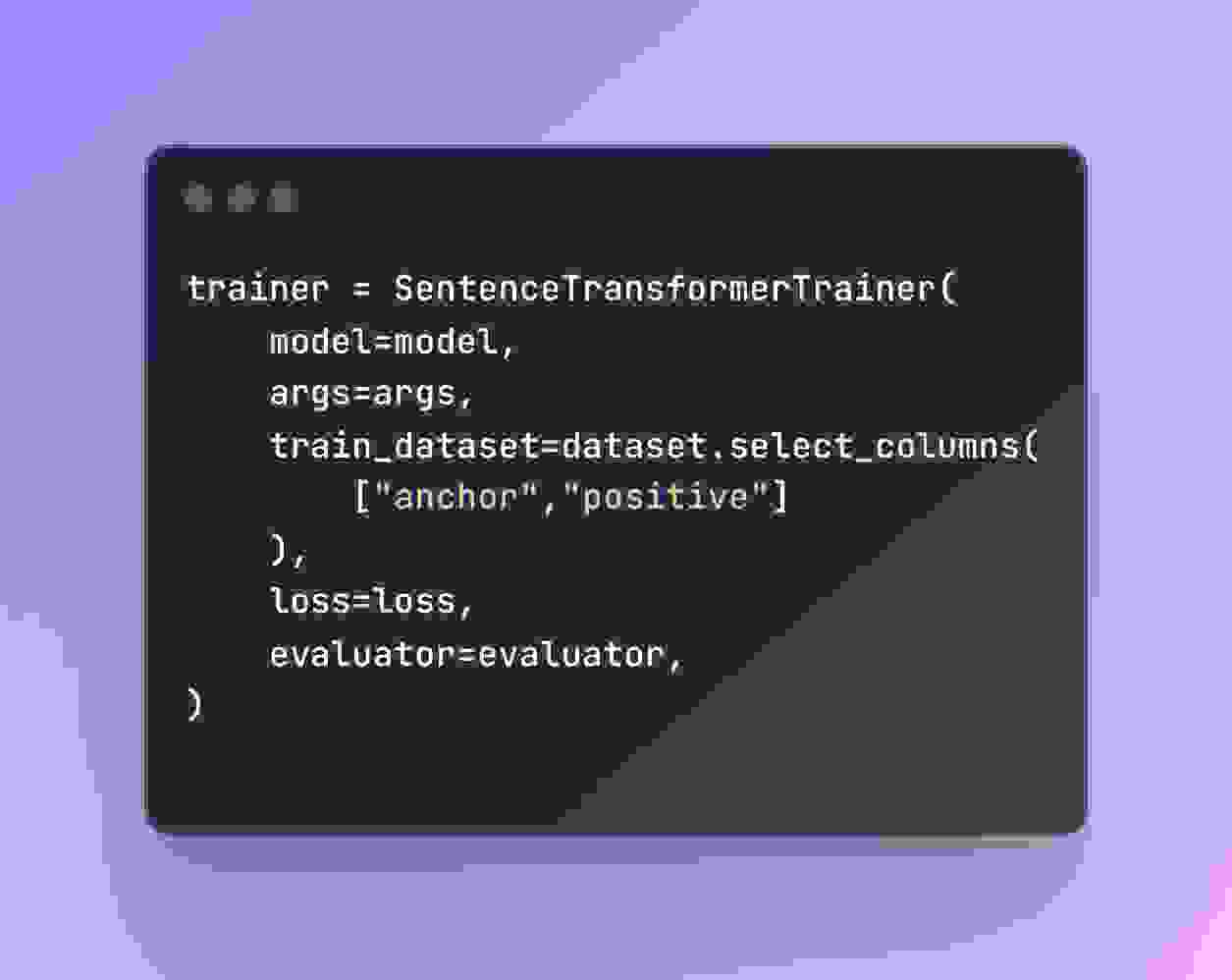
创建一个 SentenceTransformerTrainer 对象,指定模型、训练参数、数据集、损失函数和评估器
trainer.train() 方法启动微调过程,使用提供的数据和损失函数更新模型的权重。
微调前 bge-base-en_dot_ndcg@10 指标为 0.5949908809486526。

微调后 bge-base-en_dot_ndcg@10 指标为 0.8245911858212284。

为您的领域微调嵌入模型有助于 NLP 应用更好地理解行业特定语言和概念,从而使问答、文档检索和文本生成等任务更加准确。
构建领域特定嵌入模型的实用技术包括利用 MRL 和使用 BGE-base-en 等强大模型。虽然微调是关键,但数据集的质量和精心策划对于取得最佳结果同样重要。
NLP 正在不断发展,新的嵌入模型和微调方法不断拓展可能性。紧跟这些变化并完善您的方法将有助于您构建更智能、更有效的领域特定应用。

