 Redis 8 已发布——而且它是开源的
Redis 8 已发布——而且它是开源的
了解更多

哈希字段过期 (HFE) 是 Redis Community Edition 和 Stack 7.4 中引入的一个令人兴奋的新功能,也是自 Redis 早期以来需求最多的增强功能之一(参见 [1]、[2]、[3])。
我们将首先探讨 HFE 实现的细节以及其重要性。然后,我们将把 Redis 与阿里巴巴的 TairHash 和 Snap 的 KeyDB 进行比较,看看其表现如何。
基准测试显示,Redis 比其他解决方案消耗的内存少得多,在所有用例中均表现出色,并且是唯一能够稳定处理高达 1000 万或更多 HFE 的解决方案。此外,Redis 还拥有一套既有效又干扰性极小的主动过期机制。最后,我们将探讨此功能如何为未来令人兴奋的创新和优化奠定基础。
就像用于键的 EXPIRE 命令一样,哈希字段的过期需要支持主动和被动过期机制。主动过期由一个定时的 cron 作业管理,该作业会定期查找并移除已过期的哈希字段。这可以防止陈旧数据堆积,即使这些字段不常被访问,也能阻止过时信息的积累。另一方面,被动过期发生在检索时,意味着当访问一个元素时,系统会检查其过期状态,如果已过期则将其移除。
为了使其高效工作,一个可靠的数据结构至关重要。挑战不仅在于管理哈希和单个字段两个层面的过期,还在于依赖现有的键空间过期机制的局限性,该机制并不完全符合 HFE 的需求。
即便如此,我们最初考虑简单地将此功能集成到现有的 EXPIRE 实现中以完成任务。但这种方法有增加当前系统挑战和潜在局限性的风险,使其可扩展性更差,更难维护。此外,添加更多逻辑可能会危及我们未来改进键空间过期机制的能力。最终,我们意识到需要一个更健壮的解决方案来解决这些低效问题并更有效地管理增加的复杂性。
退一步来看,我们对键空间的整体过期机制进行了评估,采取了一种全局观来理解更广泛的挑战。我们的目标是找到一种既适用于哈希字段也适用于键空间过期机制的模式。
这段历程引导我们提出了一种创新设计:一种名为 ebuckets 的通用数据结构。它针对主动过期进行了优化,按过期时间对项目进行排序,并将每项元数据的内存使用量从之前的 40 字节削减到约 20 字节。然而,它确实要求已注册的项目包含一个嵌入式的过期结构体。
因此,通过从使用普通的 Redis SDS 字符串切换到一种称为 MSTR 的新数据结构,我们将过期结构体嵌入到了已注册的哈希字段中。MSTR 是一种通用的不可变字符串,可以选择附加一个或多个元数据。我们对其进行了集成,以便每个哈希实例可以在其私有的 ebuckets 中管理自己的 HFE 集。为了支持跨哈希实例的主动过期,我们添加了全局 ebuckets 来注册具有相关 HFE 的哈希。
ebuckets 由 RAX 树构成,在规模较小时则为链表。它按项目的 TTL(存活时间)排序。RAX 树中的每个叶子都是一个 bucket,代表一个时间间隔,并包含一个或多个段(segment)。每个 bucket 中的每个段最多包含 16 个项目,形成链表。下图总结了这些想法。它还暗示了 MSTR 的布局以及 dict 类型的哈希表将如何与之集成。过期结构体(用黄色绘制)基本上包含“next”指针、过期时间(简称 TTL)以及一些其他相关元数据
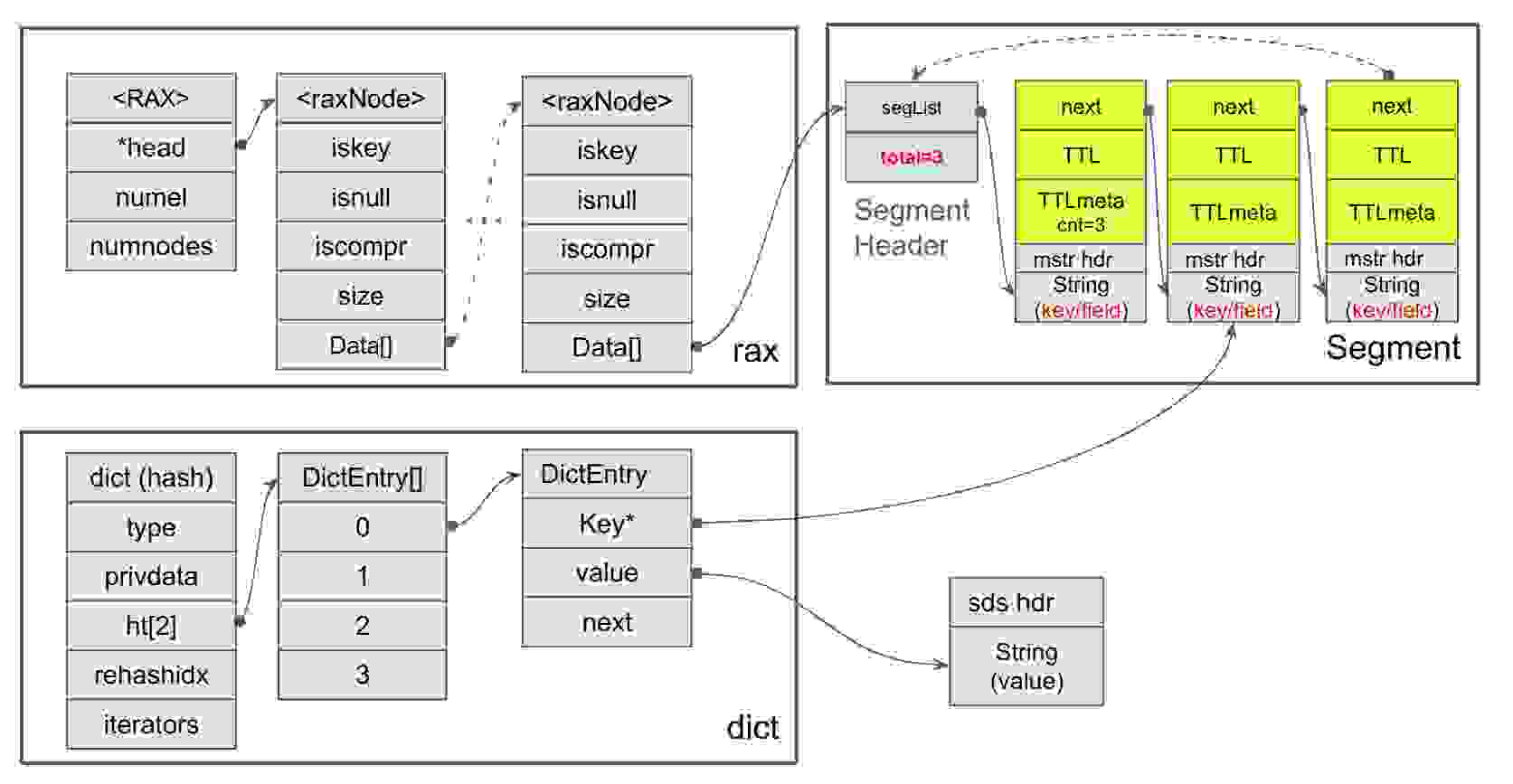
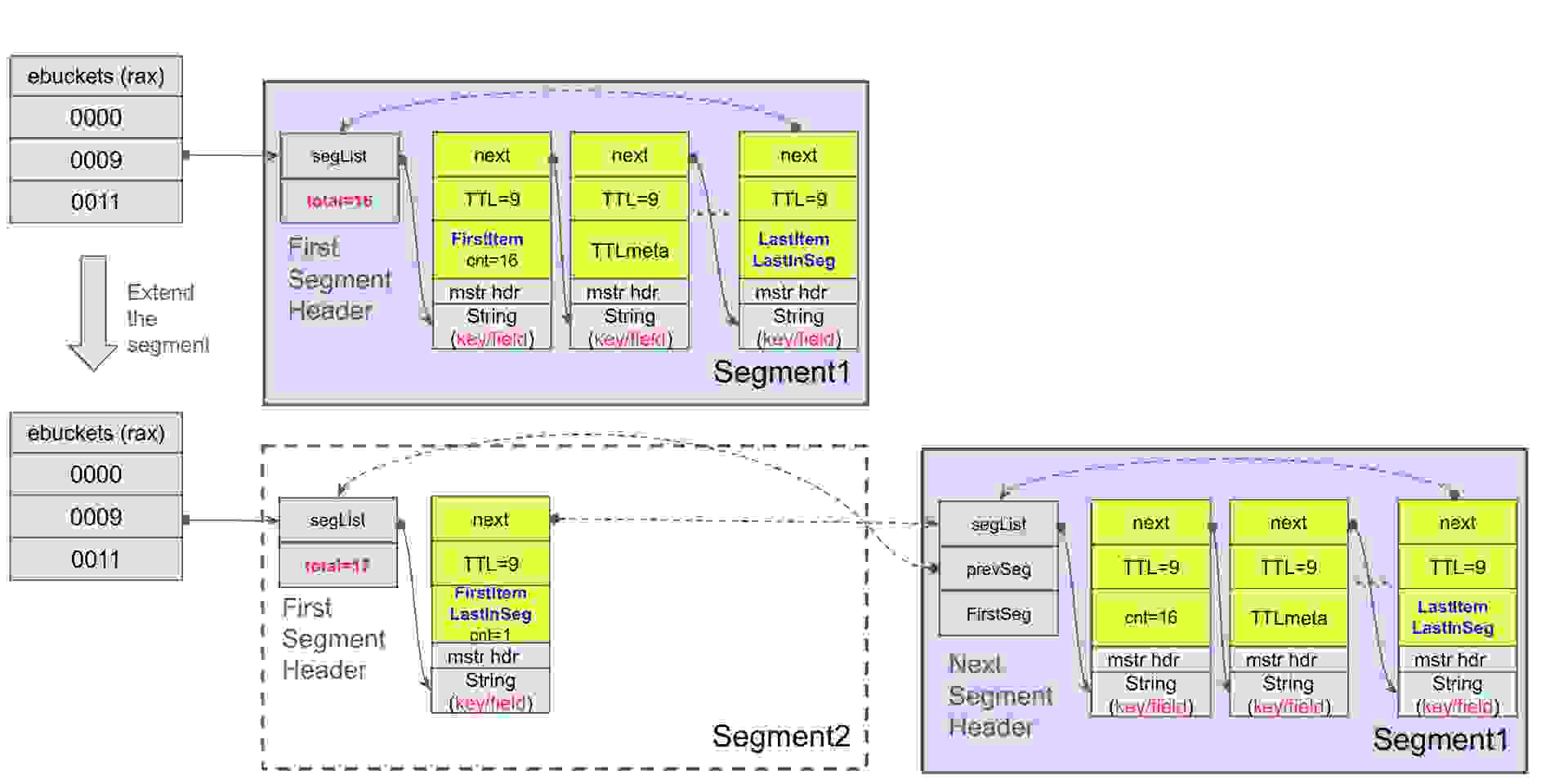
如果一个段达到其限制,它就会分裂,同时也将 bucket 分裂成数据结构中两个较小的时间间隔。如果该段包含具有相同 TTL 的项目,分裂可能不均匀,因为这些具有相同 TTL 的项目必须留在同一个 bucket 中。这引出了另一个关键点:如果一个段满了,并且所有项目都具有相同的 TTL,则 bucket 无法进一步分裂。相反,所有具有相同 TTL 的项目将通过创建一个扩展段并将其链接到原始段来聚合。
多年来,少数项目提出了处理 HFE 的解决方案,它们或是 Redis 的模块或分支。其中,Snap 的 KeyDB 和阿里巴巴的 TairHash 表现突出。它们的开发努力令人印象深刻,足以引起我们的重视,并决定对其能力进行基准测试(具体测试的是提交 603ebb2 和 4dbecf3)。为了了解 Redis 与它们的对比情况,我们在 AWS 的 m6i.large 实例上运行了一系列性能测试,分为三个回合,侧重于:
这些元素展示了该功能的细微动态,突出了资源效率、操作速度、过期项目的及时移除以及它们对服务器影响之间的复杂平衡。基准测试代码可在此处进行查阅。
下图展示了两种测试用例的内存使用情况,以 query used_memory_human 测量。
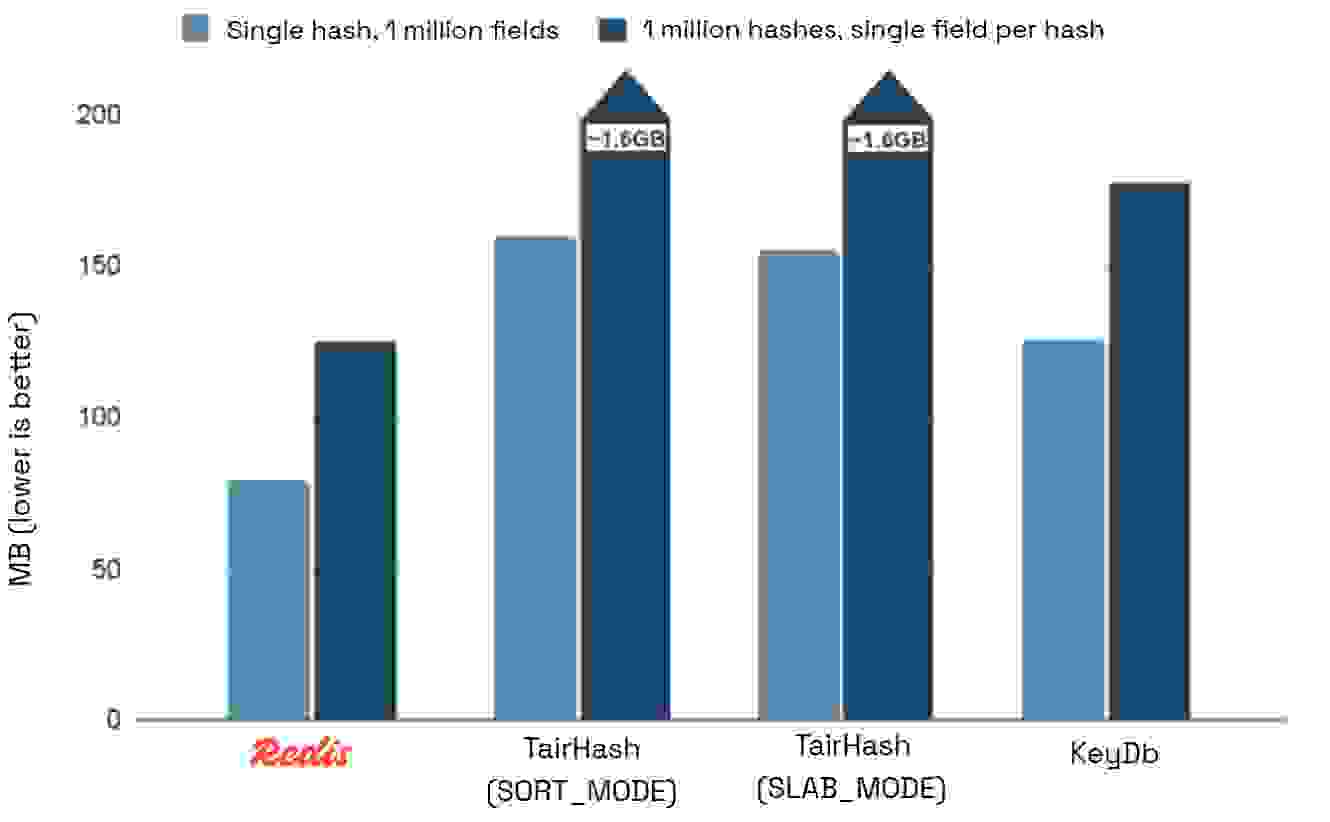
我们预计 TairHash 会比 Redis 和 KeyDB 表现差,因为它是一个模块并带来额外开销。但与 Redis 相比,其内存使用量增加了 12.9 倍,这表明 TairHash 存在严重的低效问题。虽然模块会带来一些每键元数据开销,但如此大的差距表明其设计选择存在缺陷。
KeyDB 的表现优于 TairHash,但在单个哈希上仍比 Redis 多使用 58% 的内存,在多个哈希上则多使用 41%。
本回合侧重于在一个哈希中设置 1000 万个字段的过期时间(每个字段具有不同的过期时间)的性能。
我们设置了四个测试用例来评估性能,在一个哈希上创建 1000 万个字段,并按如下方式设置字段的过期时间:
该基准测试使用实用工具 memtier_benchmark 来填充哈希,然后设置字段的过期时间。如果过期时间很远,它还会查询所有字段的 TTL。例如,Redis 的测试用例 #1 将对单个哈希运行 HSET 命令,然后对所有字段应用 HEXPIRE,最后查询所有字段的 HTTL。需要注意的是,测试用例 #3 旨在查看 KeyDB 的多线程在涉及多个客户端时是否能带来优势。
下表显示了设置字段过期时间命令的每秒请求数,因为此命令最容易出错,也是我们主要关注的重点(越高越好)
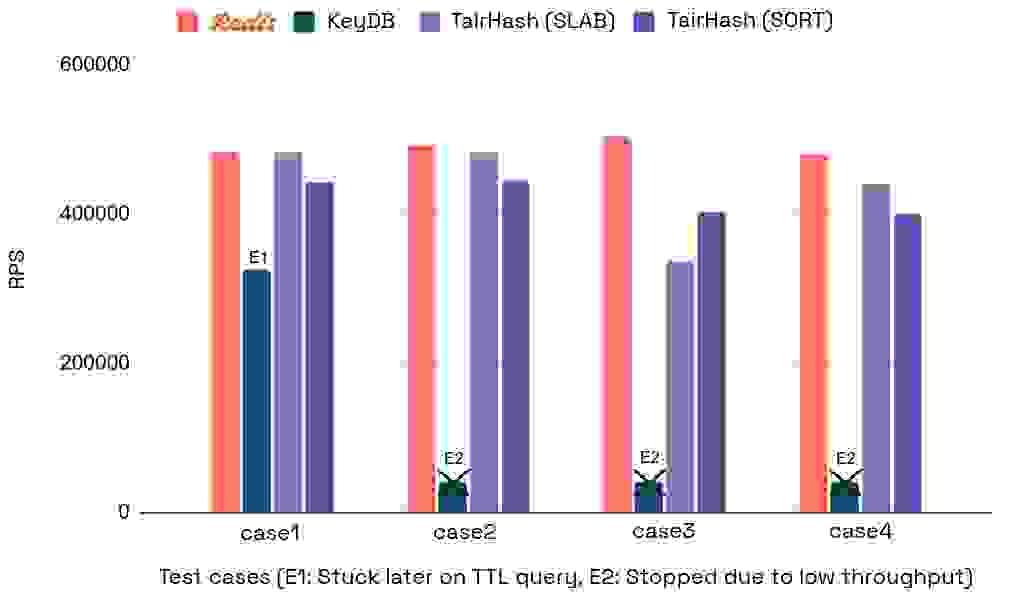
下表还显示了针对每个执行命令测得的 ops/sec(每秒操作数)
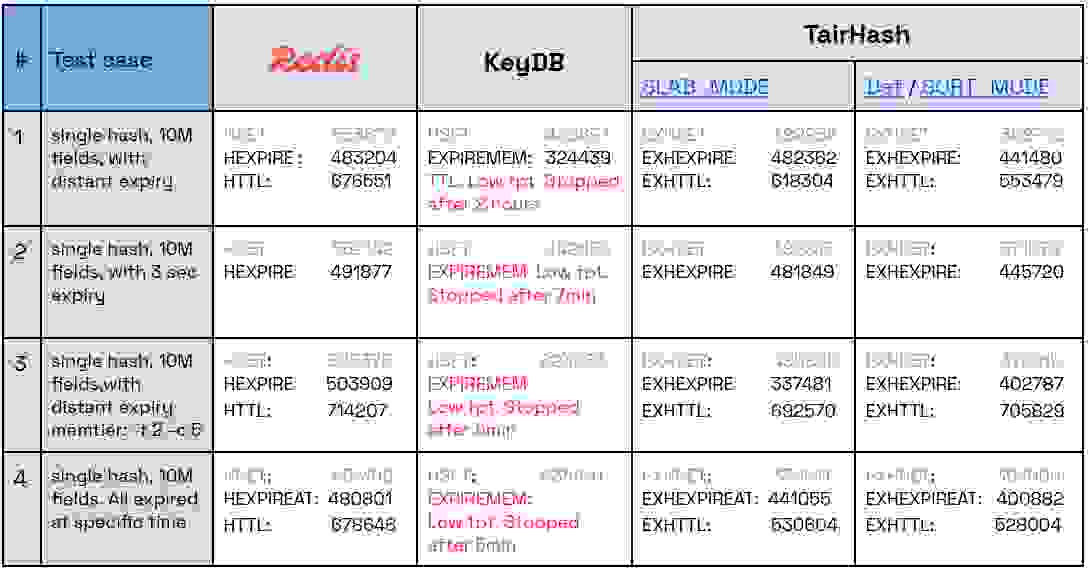
虽然 Redis 和 TairHash 都表现出有竞争力的性能,但 Redis 脱颖而出,在最佳情况下吞吐量比 SLAB_MODE 高出 49%,比 SORT_MODE 高出 25%。 KeyDB 在大规模执行 EXPIREMEMBER 时表现不佳,性能无法容忍且吞吐量非常低,在处理了 5% 的流量后就降至 1k ops/sec 以下。即使将测试规模减小到 100 万个字段,KeyDB 也表现出同样的糟糕结果。
我们还想测试 1000 万个哈希,每个哈希只有一个字段的场景,但测试 TairHash 在此场景下具有挑战性。AWS 实例 (m6i.large) 在 SLAB 模式下处理 100 万个哈希后就因内存耗尽而崩溃(每个哈希只有一个字段),在 SORT 模式下则在处理 400 万个哈希时崩溃。另一方面,KeyDB 出现了极低的吞吐量,并且在超过 10 分钟仍未完成时停止了测试。相比之下,Redis 在此场景下也表现出了卓越的性能
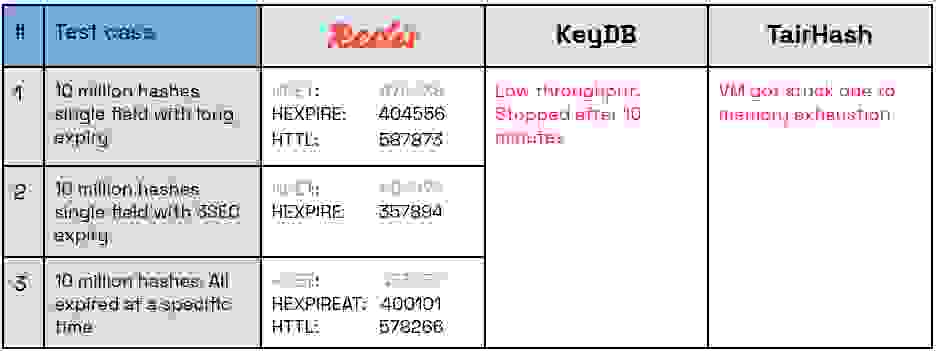
虽然设置哈希字段的 TTL 和内存使用量很重要,但这里的真正目标是在后台高效地删除过期字段,接近它们的过期时间,并且对服务器的影响最小——尤其是在不同的工作负载条件下。请注意,这些是相互冲突的要求。
为了了解主动过期后台任务的处理能力,我们测试了两个侧重于具有短 TTL 的哈希字段过期以触发快速过期的场景
一旦进入主动过期,它会以一种非常低效的方式简单地阻塞在此任务上直到完成。在一个哈希上仅有 10 万个字段时,服务器对一个简单查询在 5.2 秒内都无法响应。然后我们再次尝试了第二个测试用例,即 10 万个哈希,每个哈希有一个过期字段,对一个微不足道的查询得到了 5.8 秒的延迟。对于 100 万个项目,在等待服务器响应超过 1 分钟后,我们最终放弃了测试。
TairHash 表现稍好。它每秒总共释放的字段不超过 1000 个,无论是在单个哈希还是跨多个哈希。并且无论有多少待过期的元素或系统有多繁忙,它都不会超过这个限制。对于 1000 万个项目,假设您有足够的内存,释放全部数据将花费近 3 小时,因此如果应用程序将其用于具有高流量的短 TTL 会话,最终将导致内存耗尽。此限制在一定程度上是可配置的,但不能根据待过期字段的数量或工作负载进行自适应调整。
Redis 通过每秒运行 10 次后台作业来处理主动过期,每次触发时旨在释放 1000 个项目。它会记录因达到此限制而连续停止了多少次调用。如果在连续释放的过期字段数量达到某个阈值,在这种情况下,它会在每次调用时将限制因子乘以 2,最高可达 32 倍。
Redis 在大约 30 秒内释放 1000 万个项目,延迟极小,即使在处理新命令时也是如此。根据内部基准测试,这项 HFE 功能比传统的键过期机制更高效,后者可能会更多地干扰服务器可用性。
下图显示了一个极端情况,其中 Redis 主动使一个名为 hash1 的单个哈希中的 1000 万个字段过期,所有字段都在时间 0 过期。与此同时,另一个名为 hash2 的哈希正在使用 memtier_benchmark(memtier: -t 1 -c 1 –pipeline 200)填充多达 1500 万个字段。此测试有助于评估对服务器可用性和主动过期效率的影响。虚线作为参考,显示了如果 hash1 不存在且在此期间没有字段被主动过期释放,hash2 将如何填充。
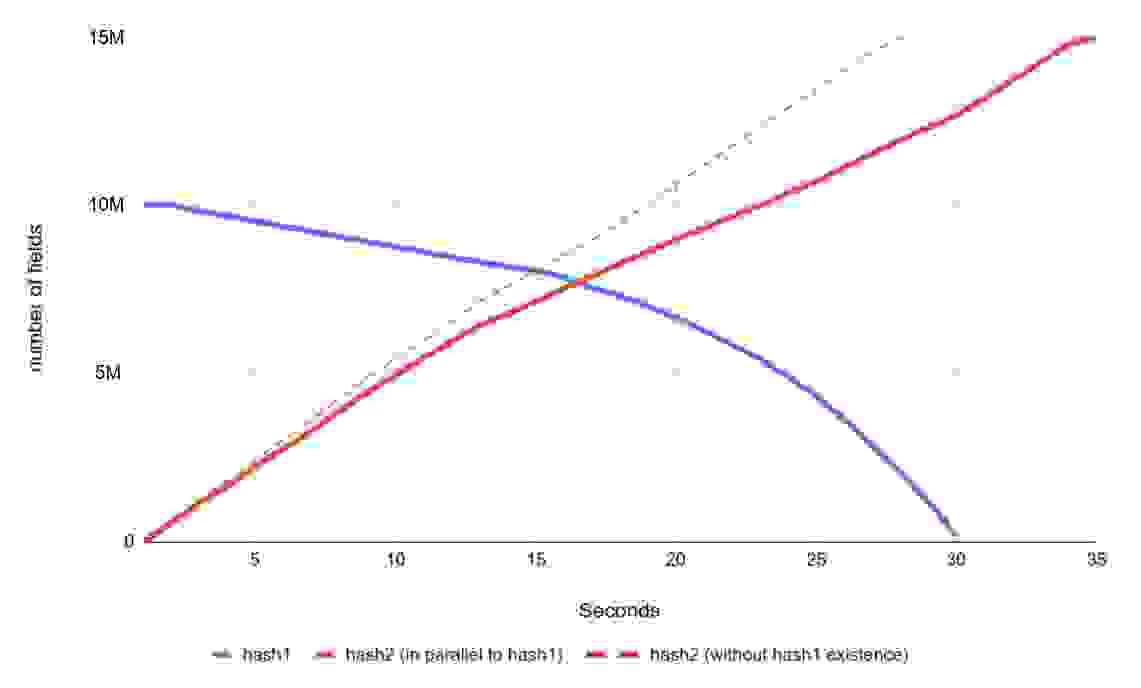
如图所示,用 1500 万个字段填充 hash2 花费了 34.5 秒,而原本为 28 秒,这意味着吞吐量下降了约 18.8%。
简而言之,此基准测试突显了 Redis 卓越的内存效率、即使处理 1000 万或更多哈希字段过期时依然保持一致的高性能,以及其自适应、高效的主动过期机制——使其远优于 KeyDB 和 TairHash。
eBuckets 对具有过期时间的字段强制实施完整的 TTL 顺序。Redis 可以利用此功能作为轻量级二级索引 ID,用于对哈希字段进行排序或分类。这可以与哈希字段的常规过期使用并行工作,即使在同一个哈希上也是如此。唯一的限制是同一个字段不能同时设置过期时间和索引。每个字段最多可以存储 48 位过期时间,但用户只能设置 46 位。因此,在轻量级索引的情况下,我们可以提升第 48 位,并保留 46 位(1 位保留)用于 USER_INDEX。这只是一个初步想法,可以通过不同的形式和 API 进行开发。目前,它尚未纳入 Redis 路线图。
ebuckets 数据结构看起来是替代当前 EXPIRE 实现的有力竞争者。它相对于现有方法显示出一些明显的优势,Redis 计划对此进行进一步探索。
社区长期以来一直寻求管理哈希等复杂数据类型中单个元素过期时间的能力。尽管存在对复杂性和资源需求的担忧,Redis 找到了一种高效的方法,不仅满足了用户对性能和简单性的需求,还为未来的创新奠定了基础。与阿里巴巴的 TairHash 和 Snap 的 KeyDb 等 Redis 分支产品的基准测试突显了 Redis 卓越的内存效率和操作稳定性。

