Redis 8 已发布——而且是开源的
Redis 8 已发布——而且是开源的
了解更多

确认偏误是所有医疗专业人员都必须努力解决的一个问题。无法考虑挑战现有观点的不同想法,会损害他们在面对既有诊断时提出新诊断的能力。
这个问题根植于医学文献,专业人员更倾向于支持其原有观点的文章。观点的多样性对于形成能够做出有效诊断的整体视角至关重要。
因此,这个 Launchpad 应用创建了一个语言处理机器学习管道,以消除医学文献中的确认偏误。Launchpad 应用利用 Redis 构建了一个管道,能够通过高效的数据传输将文本转化为知识图谱。
让我们探究该团队是如何做到这一点的。但在深入探讨之前,请务必查看我们在 Launchpad 上提供的所有不同且创新的应用。

让我们探讨如何使用 Redis 构建自然语言处理(NLP)管道。
我们将揭示 Redis 如何被用于实现这个想法,同时突出显示所使用的每个组件并阐述其功能。


从头到尾,Redis 是此管道的数据基础。其功能是将文本转化为知识图谱。让我们快速概述一下什么是知识图谱及其在此项目中的功能。
当今的系统不仅仅存储文件夹、文件和网页。相反,它们是由实体(例如对象、情况或概念)组成的复杂网络。知识图谱会突出显示每个实体的属性以及它们之间的关系。这些信息通常存储在图数据库中,并可视化为图结构。
知识图谱由 2 个主要组成部分组成
下面是使用节点和边集成数据的示例。

在第一个管道中,您将了解如何使用医学词典创建医学文献的知识图谱。这通过 RedisGears 处理信息并将其存储在 RedisGraph 中。
首先,使用以下代码解压并解析 metadata.zip,其中文件名、标题和年份被提取到 HASH 中
redis_client.hset(f"article_id:{article_id}",mapping={'title': each_line['title']})
redis_client.hset(f"article_id:{article_id}",mapping={'publication_date':each_line['publish_time']})
以下代码通过读取 JSON 文件来工作——data/sample_folder 中的示例:the-pattern-platform/RedisIntakeRedisClusterSample.py
它还将 JSON 解析为 String
rediscluster_client.set(f”paragraphs:{article_id}“,” “.join(article_body))
以下代码是使用 RedisGears 进行的主要预处理任务:the-pattern-platform/gears_pipeline_sentence_register.py
它还监听段落的更新:key
gb = GB('KeysReader')
gb.filter(filter_language)
gb.flatmap(parse_paragraphs)
gb.map(spellcheck_sentences)
gb.foreach(save_sentences)
gb.count()
gb.register('paragraphs:*',keyTypes=['string','hash'], mode="async_local")
这使用了 RedisGears 和 HSET/SADD。
如何使用 Aho-Corasick 算法将句子转化为边(句子)和节点(概念)
第一步是使用以下代码
bg = GearsBuilder('KeysReader')
bg.foreach(process_item)
bg.count()
bg.register('sentence:*', mode="async_local",onRegistered=OnRegisteredAutomata)
下一行代码将在每个分片上创建一个 stream:
'XADD', 'edges_matched_{%s}' % shard_id, '*','source',f'{source_entity_id}','destination',f'{destination_entity_id}','source_name',source_canonical_name,'destination_name',destination_canonical_name,'rank',1,'year',year)
以下用于增加句子分数
zincrby(f'edges_scored:{source_entity_id}:{destination_entity_id}',1, sentence_key)
如何从 RedisGears 填充 RedisGraph
the-pattern-platform/edges_to_graph_streamed.py 通过在 RedisGraph 中创建节点、边或更新其排名来工作
"GRAPH.QUERY", "cord19medical","""MERGE (source: entity { id: '%s', label :'entity', name: '%s'})
ON CREATE SET source.rank=1
ON MATCH SET source.rank=(source.rank+1)
MERGE (destination: entity { id: '%s', label: 'entity', name: '%s' })
ON CREATE SET destination.rank=1
ON MATCH SET destination.rank=(destination.rank+1)
MERGE (source)-[r:related]->(destination)
ON CREATE SET r.rank=1, r.year=%s
ON MATCH SET r.rank=(r.rank+1)
ON CREATE SET r.rank=1
ON MATCH SET r.rank=(r.rank+1)""" % (source_id ,source_name,destination_id,destination_name,year))
the-pattern-api/graphsearch/graph_search.py
包含年份、节点 ID、限制和年份的边
"WITH $ids as ids MATCH (e:entity)-[r]->(t:entity) where (e.id in ids) and (r.year in $years) RETURN DISTINCT e.id, t.id, max(r.rank), r.year ORDER BY r.rank DESC LIMIT $limits"""
节点
"""WITH $ids as ids MATCH (e:entity) where (e.id in ids) RETURN DISTINCT e.id,e.name,max(e.rank)"""
接下来使用以下代码查找得分最高的文章:
app.py uses zrangebyscore(f"edges_scored:{edges_query}",'-inf','inf',0,5)
使用管道中最幽默的代码
向您的安全架构师展示以下代码
import httpimport
with httpimport.remote_repo(['stop_words'], "https://raw.githubusercontent.com/explosion/spaCy/master/spacy/lang/en/"):
import stop_words
from stop_words import STOP_WORDS
with httpimport.remote_repo(['utils'], "https://raw.githubusercontent.com/redis-developer/the-pattern-automata/main/automata/"):
import utils
from utils import loadAutomata, find_matches
这是必需的,因为 RedisGears 不支持提交项目或模块。

BERT 代表 Bidirectional Encoder Representations from Transformers。它由 Google AI 的研究人员创建,是处理自然语言任务的世界领导者,包括问答 (SQuAD v1.1.)、自然语言推理 (MNLI) 等等。
以下是 BERT 模型的一些流行用例
最先进的代码在 the-pattern-api/qasearch/qa_bert.py 中。它查询 RedisGears + RedisAI 集群,向用户提供一个问题:
get "bertqa{5M5}_PMC140314.xml:{5M5}:44_When air samples collected?"
这查询分片 {5MP} 上的 bertqa 前缀,其中 PMC140314.xml:{5M5}:44(见下文) 是预分词 REDIS AI Tensor(潜在答案)的 key,“When air samples collected?” 是用户的提问。
PMC140314.xml:{5M5}:44
然后 RedisGears 捕获 keymiss 事件 the-pattern-api/qasearch/qa_redisai_gear_map_keymiss_np.py
gb = GB('KeysReader')
gb.map(qa_cached_keymiss)
gb.register(prefix='bertqa*', commands=['get'], eventTypes=['keymiss'], mode="async_local")
然后 RedisGears 运行以下内容
对于非阻塞主线程模式,模型使用 AI.modelset 在每个分片上预加载,代码位于 the-pattern-api/qasearch/export_load_bert.py 中。

摘要功能通过运行在 sentence: 前缀上并运行 t5-base transformers tokenizer 来实现,使用简单的 SET 命令和 python.pickle 模块将结果保存在 RedisGraph 中,将 summary key(源自 article_id)添加到
rconn.sadd('processed_docs_stage3_queue', summary_key)
以下代码订阅队列,运行简单的 SET 和 SREM 命令
summary_processor_t5.py
这随后会更新 RedisGraph 中的 hash
redis_client.hset(f"article_id:{article_id}",mapping={'summary': output})
Redis 提供了 rgcluster Docker 镜像以及 redis-cluster 脚本。确保集群部署在高可用配置中非常重要。每个主节点必须至少有一个副本。这是因为部署机器学习模型时需要重启主节点。
如果主节点重启且没有副本,则集群将进入失败状态,您将不得不手动重新创建它。
其他参数包括执行时间和内存。BERT 模型在内存中占用 1.4 GB,因此需要包含 proto buffer 内存。您还需要增加集群和 gears chart 的执行时间,因为所有任务的计算量都很大,所以您需要确保可以容纳超时。
确保您的系统中安装了 virtualenv、Docker 和 Docker compose。
apt install docker-compose
brew install pyenv-virtualenv
git clone --recurse-submodules https://github.com/redis-developer/the-pattern.git
cd the-pattern
./start.sh
cd ./the-pattern-platform/
source ~/venv_cord19/bin/activate #or create new venv
pip install -r requirements.txt
bash cluster_pipeline.sh
稍等片刻,然后检查以下内容
RedisGraph 已填充
redis-cli -p 9001 -h 127.0.0.1 GRAPH.QUERY cord19medical "MATCH (n:entity) RETURN count(n) as entity_count"
redis-cli -p 9001 -h 127.0.0.1 GRAPH.QUERY cord19medical "MATCH (e:entity)-[r]->(t:entity) RETURN count(r) as edge_count"
API 是否响应
curl -i -H "Content-Type: application/json" -X POST -d '{"search":"How does temperature and humidity affect the transmission of 2019-nCoV"}' https://:8080/gsearch
cd the-pattern-ui
npm install
npm install -g @angular/cli@9
ng serve
cd the-pattern-api/qasearch/
sh start.sh
注意: 这将下载并预加载 1.4 GB 的 BERT QA 模型到每个分片上。由于其大小,它有可能在笔记本电脑上崩溃。通过运行以下命令进行验证:
curl -H "Content-Type: application/json" -X POST -d '{"search":"How does temperature and humidity affect the transmission of 2019-nCoV?"}' https://:8080/qasearch
从“the-pattern”仓库转到 RedisGears 集群上的仓库
cd the-pattern-bart-summary
# source same enviroment with gears-cli (no other dependencies required)
source ~/venv_cord19/bin/activate
gears-cli run --host 127.0.0.1 --port 30001 tokenizer_gears_for_sum.py --requirements requirements.txt
此任务可能会超时,但您可以安全地重新运行所有内容。
在 GPU 或服务器上配置 NVidia 驱动程序
sudo apt update
sudo apt install nvidia-340
lspci | grep -i nvidia
sudo apt-get install linux-headers-$(uname -r)
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')
wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-$distribution.pin
sudo mv cuda-$distribution.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/7fa2af80.pub
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
sudo apt-get update
sudo apt-get -y install cuda-drivers
# install anaconda
curl -O https://repo.anaconda.com/archive/Anaconda3-2020.11-Linux-x86_64.sh
sh Anaconda3-2020.11-Linux-x86_64.sh
source ~/.bashrc
conda create -n thepattern_env python=3.8
conda activate thepattern_env
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11 -c pytorch
配置从实例到 RedisGraph docker 镜像的访问(或使用 Redis Enterprise)
git clone https://raw.githubusercontent.com/redis-developer/the-pattern-bart-summary.git
#start tmux
conda activate thepattern_env
pip3 install -r requirements.txt
python3 summary_processor_t5.py
虽然 RedisGears 允许您部署和运行 spacy 和 BERT transformers 等机器学习库,但下面的解决方案采用了更简单的方法
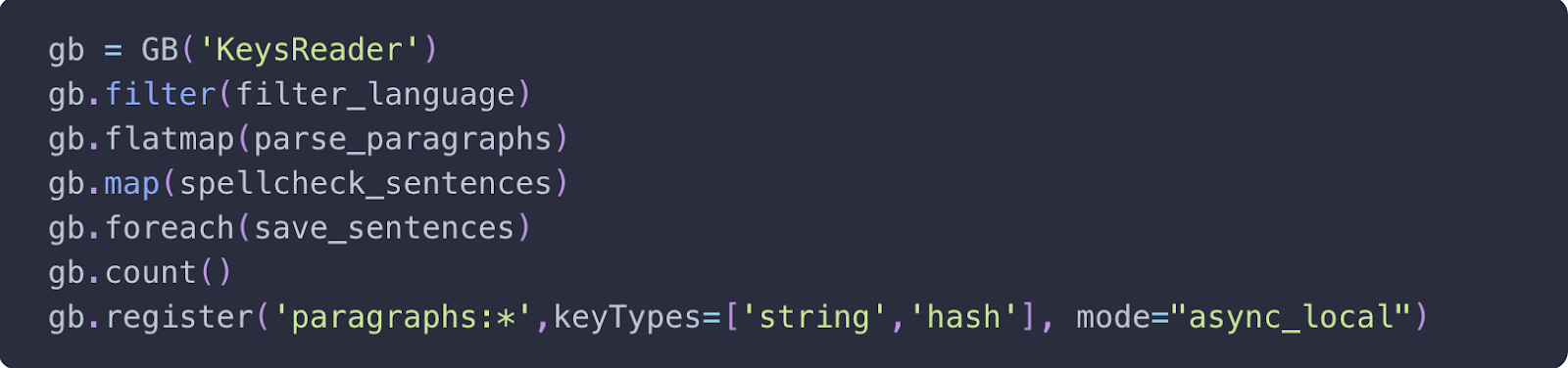
整体管道快速概览:以上 7 行代码允许您在分布式集群或使用所有可用 CPU 的单台机器上运行逻辑。顺便说一句,除非您需要扩展到 1000 个以上的节点,否则无需更改。
对所有字符串或 hash 使用为命名空间段落注册的 KeysReader。您的管道需要以 async 模式运行。如果您是数据科学家,我们建议使用 gb.run 来帮助确保 RedisGears 工作正常并以 batch 模式运行。它将以 batch 模式运行。之后,更改它以进行注册,以捕获新数据。
默认情况下,函数会返回到输出,因此需要使用 count () – 以防止将整个数据集(Cord19 为 90 GB)获取回发出命令的机器。
总的来说,预处理是一个简单的过程。您可以在此处访问完整的代码。


您可以直接从 UMLS 数据构建 Aho-Corasick 自动机。Aho-Corasick 将允许您将输入的句子匹配为节点对,并将句子表示为图中的边。与 Gears 相关的代码很简单:
bg = GearsBuilder('KeysReader')
bg.foreach(process_item)
bg.count()
bg.register('sentence:*', mode="async_local",onRegistered=OnRegisteredAutomata)
Redis 知识图谱旨在根据冗长详细的查询创建知识图谱。

初步步骤:选择“入门”并选择“护士”或“医学生”。
步骤 1: 在搜索栏中输入您的查询
步骤 2: 选择与您的搜索最相关的查询
步骤 3: 在不同的节点之间浏览,并使用底部的开关条更改搜索日期
Launchpad 应用使用 Redis 创建了一个管道,帮助医疗专业人员浏览医学文献而不会受到确认偏误的影响。紧密集成的 Redis 系统促进了组件之间数据的无缝传输,从而诞生了一个供医疗专业人员使用的知识图谱。
访问 Redis Launchpad,您可以了解更多关于此创新应用的方方面面。在那里,您可能还想浏览我们在 令人兴奋的应用系列 中提供的各种应用。
您可以前往 Launchpad 发现更多关于此应用以及我们精彩的应用系列中的许多其他应用。

Alexander Mikhalev

Alexander 是一位充满热情的研发人员,随时准备深入研究新技术并开发“新事物”。
请务必访问他的 GitHub 页面,查看他参与的所有最新项目。