 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的

视频
Redis Streams 和 Java 入门
了解更多

Redis 的开发非常注重性能。我们尽最大努力确保每次发布都能为您提供一个非常稳定和快速的产品。
然而,如果您正在寻找提高 Redis 效率的空间,或者正在进行性能回归调查,您将需要一种简洁且有条理的方法来监控和分析 Redis 的性能。这是其中一个优化的故事。
最后,我们将 stream 的摄取性能 提高了约 20%,您已经可以在 Redis v7.0 上利用这一改进。
在深入研究优化之前,我们想向您介绍一下我们是如何实现它的。
如前所述,我们希望识别 Redis 性能回归和/或潜在的 on-CPU 性能改进。为此,我们认为有必要在所有与性能和可观察性要求和期望相关的事项上,促进一套跨公司和跨社区的 标准。
简而言之,我们不断地运行 SPEC 的基准测试,按分支/标签分解它们,并以“零接触”全自动模式解释生成的性能数据,包括分析工具/探针输出和客户端输出。
所使用的工具都是开源的,并依赖于诸如 memtier_benchmark、redis-benchmark、Linux perf_events、 bcc/BPF 跟踪工具 以及 Brendan Greg 的 FlameGraph 仓库 等工具/流行框架。
如果您有兴趣了解更多关于我们如何将分析器与 Redis 结合使用的详细信息,我们建议您查看我们非常详细的“用于 on-CPU 性能分析和跟踪的性能工程指南。”
一旦完成了第一步,我们就开始解释分析工具/探针的输出。Streams 的摄取基准测试中呈现出了一种有趣的模式,它只是将数据摄取到 stream 中,使用的命令类似于下面的命令
`XADD key * field value`。
我们观察到,当添加到没有 ID 的 stream 时,它会在 SDS 创建/释放/sdslen 上产生重复的工作,这占用了大约 10% 的 CPU 周期,如下面两个 perf 报告打印的详细展示。
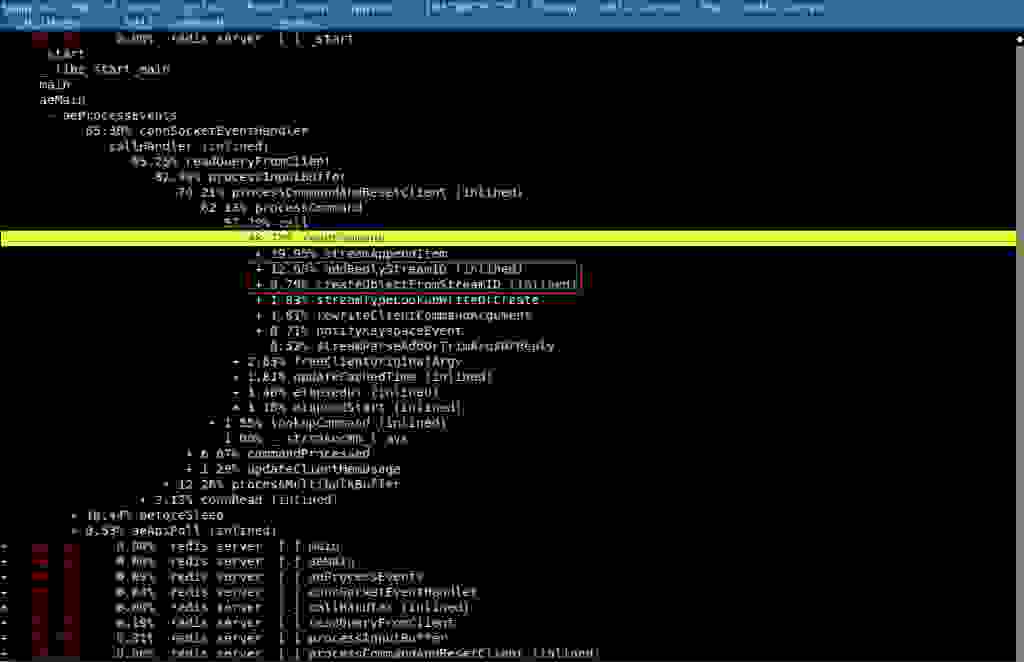
对于相同的输入,sdscatfmt 和 _sdsnewlen 被调用了两次

这使我们能够将 Streams 的摄取优化约 9-10%,如下面的基准测试结果所证实。
不稳定分支上的基线(6b403f5):
此 PR 的第一个提交(避免重复工作)

这个用例改进的最初重点引导 Oran(核心团队成员之一)进行了进一步的分析,他注意到在同一个代码块中还有另一种 CPU 周期浪费。这一次,是由于非最佳内存管理。我们正在分配一个空的 SDS,然后再重新分配它。减少调用次数将为我们带来另一个速度提升,如下所示。
第二次提交(避免重新分配)

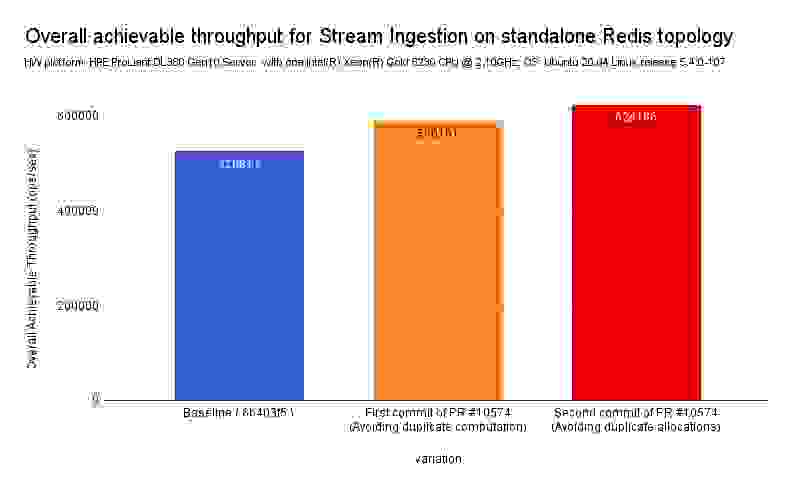
正如预期的那样,通过简单地重用中间计算,并因此减少内部调用函数中的冗余计算和分配,我们测量到 Redis Streams 的总体 CPU 时间减少了约 20%。
我们认为这是一个例子,说明了有条不紊的简单改进如何能够显著提高性能,即使对于像 Redis 这样已经经过深度优化的代码也是如此。
我们的目标是扩大我们对 Redis 的性能可见性,并鼓励来自行业和学术界的成员,包括组织和个人,做出贡献。如果我们不测量它,我们就无法改进它。

