 Redis 8 来了——而且它是开源的
Redis 8 来了——而且它是开源的

视频
自动分层为大型数据集提供两倍吞吐量和一半延迟
了解更多

十多年来,您一直信任 Redis,因为我们让创建强大、快速且能大规模运行的应用程序变得容易——并且我们努力不辜负这一声誉。Redis 正通过我们在 Redis 7.2 中注入的所有创新延续这一精神。
以下是我们正在做的,以增加您喜爱我们的理由。
有一种无可替代的学习方式,只能通过使用你主导开发的工具来获得。在我担任 Redis CEO 之前,我作为一名开发者,一头扎进了使用这款产品的实践中。它无与伦比的性能、可伸缩性以及设计方法(正如 Redis 宣言中所述)都激励着我,正如它激励着全球数百万其他开发者一样。我看到了 Redis 之所以能成为世界上最成功的开源数据库之一的原因。
Redis 增长的原因包括对更快应用程序、实时推理以及生成式 AI 和向量数据库广泛采用的需求不断增长。随着 Redis 远远超出其作为数据结构服务器(通常用于缓存)的起点,新一代开发者希望享受到 Redis 的优势。我们意识到,我们需要扩大对所有 Redis 实践者(开发者、架构师和运维人员)的整体体验的责任。
作为一名开发者,我非常欣赏 Redis 核心 API 的优雅和易用性。事实上,我非常希望这种愉快的体验也能体现在产品组合的其他部分,例如客户端、集成、工具和文档中。我决定——我们需要解决这个问题,并发挥更积极的引导作用。
我于二月加入 Redis。自那时起,我们制定了扩大作为 Redis 项目管理者角色的策略。在这一角色中,我们拥抱 Redis 社区驱动的魅力,同时使所有 Redis 发行版更容易导航,提供清晰的指引和明确的路径。通过充当社区管理者,我们帮助 Redis 新手和长期实践者都能享受到 Redis uncompromising 的性能、传奇般的可靠性和简单性。
Redis 一直是科技行业中的强大竞争者,但成为最好的自己的旅程永无止境。我们一直在努力工作,让 Redis 对开发者、架构师和运维人员更有价值。
今天,我很高兴介绍 Redis 7.2,这是我们持续改进和提升您体验之旅中的又一步。
那么,让我们深入探讨一下我们如何让 Redis 用户更容易地使用技术。因为在 Redis,我们致力于帮助每个人更快、更自信地构建更好的软件。
Redis 7.2 是我们迄今为止影响最深远的版本。它包含广泛的新功能集,并在支持 AI 项目的功能上投入了大量资金。在这些增强功能中,您会注意到一个强烈的主题:让开发者更容易使用 Redis,让它运行得更快,并让创新更容易实现。
我们承诺通过所有分发渠道同时提供所有这些功能,我们称这种方法为“统一 Redis 版本发布”。
利用大型语言模型(LLM)和生成式 AI 的努力正以惊人的速度改变着计算机软件,我们一直在努力在我们的平台中提供各种功能,使这项工作变得简单。我们一直在为世界上一些最大的客户(包括 OpenAI)提供支持,并且多年来一直在投资,使机器学习(ML)——以及现在的向量数据库——无缝且易于访问。
我们也理解那些正在尽力基于它们进行创新的企业所关心的问题。例如,我最早的客户拜访之一是拜访了一家大型金融服务客户。该公司有多个 ML 工作负载完全运行在 Redis 上,数百 TB 的数据以 5 个 9 的可用性运行。企业正在寻找一种经过验证的企业级向量数据库,该数据库具有 Active-Active 地理分布式、多租户、基于标签的混合搜索、基于角色的访问、嵌入式对象(即 JSON)、文本搜索功能和索引别名。我们在 Redis Enterprise 中内置了所有这些功能,并经过了实战考验。
Redis 通过多种策略在其数据库服务中支持生成式 AI 工作负载,这些策略旨在提高效率、降低成本并增强可伸缩性和性能。Redis 的向量数据库支持两种向量索引类型:FLAT(暴力搜索)和 HNSW(近似搜索),以及三种流行的距离度量:余弦相似度、内积和欧氏距离。其他功能包括范围查询、混合搜索(结合过滤器和语义搜索)、JSON 对象支持等。
但是,当人们问我们 Redis 如何帮助构建和部署基于 LLM 的应用程序时?我们究竟能做什么?
在过去的 12 个月里,我们已将 Redis 与最流行的应用程序开发框架集成,用于创建基于 LLM 的聊天机器人、代理和链。其中包括 LlamaIndex、Langchain、RelevanceAI、DocArray、MantiumAI 以及 ChatGPT 检索插件。此外,我们还与 NVIDIA 密切合作了一些其领先的 AI 项目:NVIDIA 的 AI 工作流(Merlin 和 Morpheus)、工具(Triton 和 RAPIDS),以及正在开发中的 RAPIDS RAFT——由 NVIDIA 提供的最先进的索引,以实现更高的每秒查询次数 (QPS)。
这些用例需要新水平的高性能搜索。在 Redis Enterprise 7.2 中,我们推出了可伸缩搜索能力的预览版。它允许在集群之间以优化的分布式处理方式运行高 QPS、低延迟的工作负载。与之前使用 Redis Enterprise 的搜索和查询引擎实现的功能相比,它能够将查询吞吐量提高多达 16 倍。
如果不重视开发者,你就无法成为最受赞赏的 NoSQL 数据库(根据 Stack Overflow 2023 年调查)。
Redis 7.2 解决了在我 Redis 开发者旅程初期困扰我的一个问题,那就是搞清楚一百多个社区开发的客户端库中哪个适合我的需求。哪个支持最新的 Redis 功能?拥有适当的安全和性能水平?
借助 Redis 7.2,我们为 Redis 客户端带来了新的指导和支持水平。我们正与 五个客户端库的社区维护者直接合作——Jedis (Java)、node-redis (NodeJS)、redis-py (Python)、NRedisStack (.Net) 和 Go-Redis (Go)——以在文档、用户界面、治理和安全等方面建立一致性。我们还在 Redis Stack 和 Redis Enterprise(云和软件)中支持 RESP3 协议。

在此版本中,我们还为实时数据带来了新的可编程性水平。Triggers and Functions 的公开预览带来了服务器端事件驱动引擎,可在数据库内部执行 Typescript/JavaScript 代码。此功能允许开发者直接在 Redis 上执行复杂的数据操作,确保任何客户端应用程序的执行一致性。
Triggers and functions 使集群级别的跨分片读操作成为可能。此功能在之前的 Redis 可编程引擎(如 Lua 和 functions)中不可用。
亲身体验。阅读完整的Triggers and Functions公告并加入公开预览。
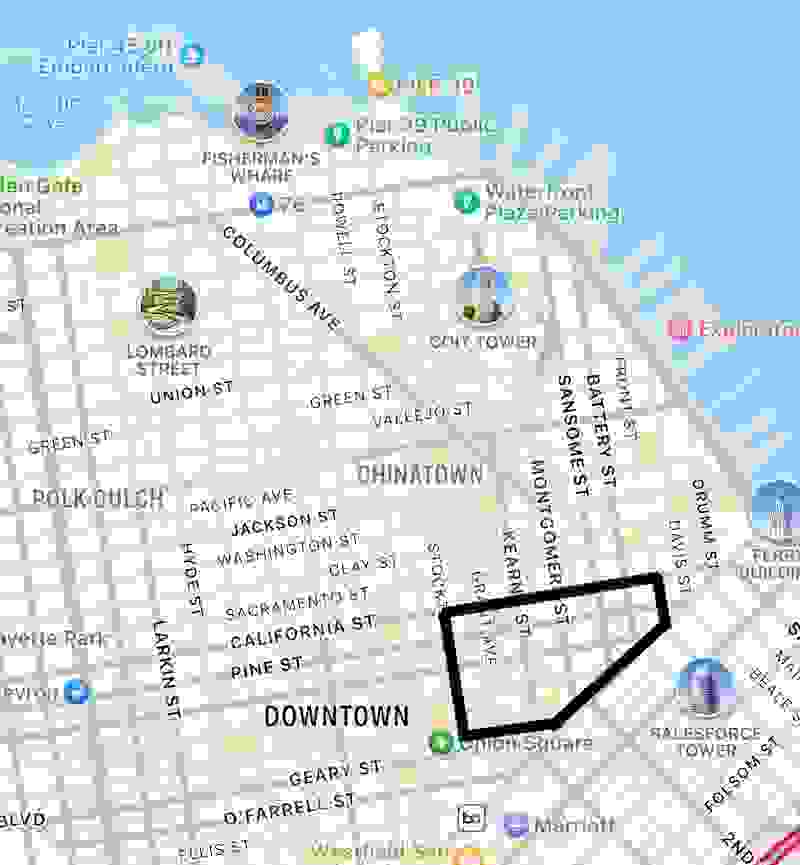
地理空间功能也得到了改进。我们改进了 Redis Stack 中的多边形搜索功能,以方便对地理空间数据进行搜索,从而查找特定地理区域内的信息。
例如,在一个用于定位墨西哥玉米卷餐厅的应用程序中,地理空间信息是旧金山所有餐厅的索引位置数据。用户在数字地图上绘制的多边形就是搜索的地理区域。Redis 只检索与绘制的多边形边界内的餐厅相关的键。
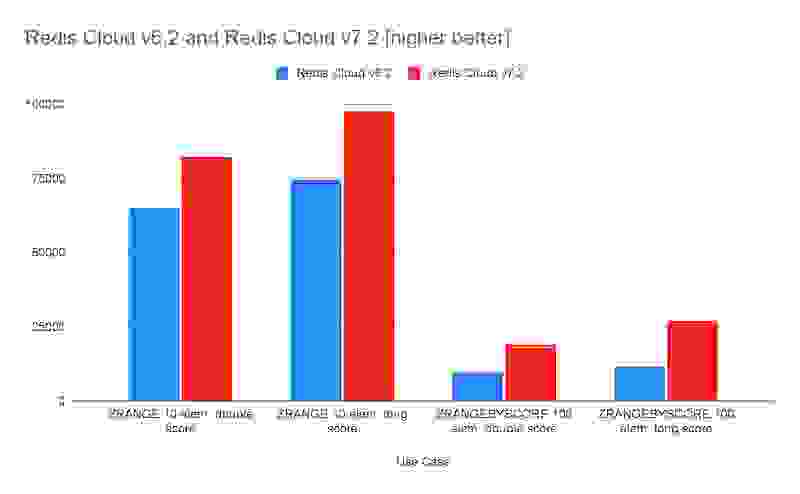
我们还在 Redis 数据类型有序集合 (sorted sets)方面进行了显著的性能改进,该类型常用于创建游戏排行榜等用途。与 Redis Enterprise Cloud 6.2 相比,我们的增强功能带来了 30% 到 100% 的性能提升。
现在,您可以使用 Redis 数据集成 (RDI),这是一个直接在 Redis Enterprise 上运行的工具,可以轻松地将任何数据集转换为 Redis。我们捕捉了最常见的用例,并通过一个基于配置而非代码的界面使它们可用。
RDI 可以从各种来源(如 Oracle、Postgres 或 Cassandra)获取数据,并实际将其转换为实时数据。类似地,当数据不再“实时”时,RDI 可以将 Redis Enterprise 中的下游更改带入记录系统,而无需添加更多代码或执行繁琐的集成。
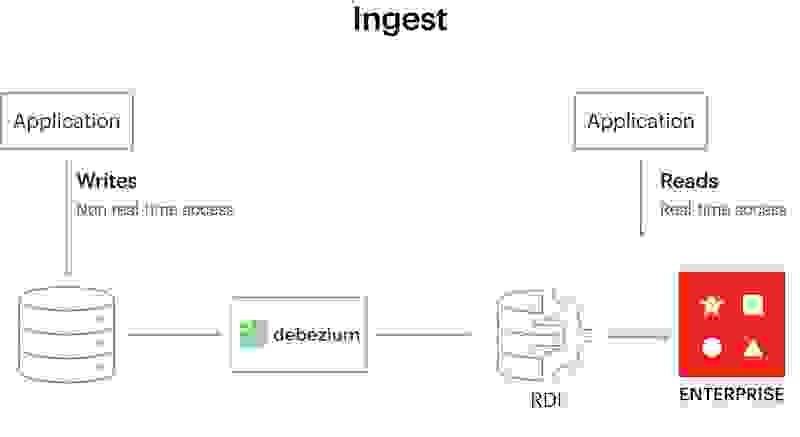
RDI(目前处于公开预览阶段)将源数据库的变更直接流式传输到 Redis,在那里它们被进一步过滤、转换并映射为 JSON 和 Hash 等格式。
了解如何试用 Redis 数据集成以及为何您会想试用。
您的应用程序并非在所有用例中都需要最快的速度。有时您无需将所有数据存储在内存中。利用 SSD 等成本较低的存储更合理——也更省钱。
在 Redis Enterprise 7.2 中,我们引入了自动分层 (Auto Tiering)(以前称为 Redis on Flash),并使用了新的默认存储引擎 Speedb。自动分层允许运维人员使用固态硬盘 (SSD) 将 Redis 数据库的大小扩展到物理 DRAM 的限制之外。这对于拥有大型数据集的应用程序非常有用,其中频繁使用的数据保留在内存中,而不经常使用的数据保留在 SSD 中。Redis Enterprise 会根据使用情况自动管理内存。
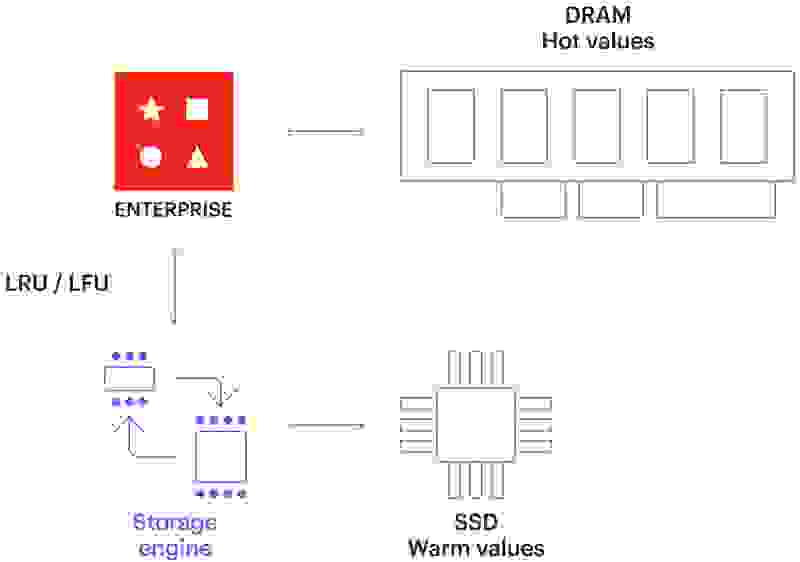
自动分层在吞吐量和延迟方面提供了显著的性能改进,吞吐量是上一代存储引擎 (RocksDB) 的两倍,而延迟只有其一半,并将基础设施成本降低了高达 70%。
在详细公告中了解自动分层的好处。
此版本中还有另外两项创新值得强调。运维人员会发现更新的集群管理器 (CM) 用户界面极大地有助于加快日常管理任务。其直观的界面具有与 Redis Enterprise Cloud 媲美的功能,可减少学习曲线并最大程度地减少错误。例如,使用新的 CM,只需两次鼠标点击即可部署新的 Redis Enterprise 数据库。
另一则好消息肯定会让容器化应用程序的运维人员感到高兴,那就是支持 Active-Active 数据库部署的Redis Enterprise Operator for Kubernetes已正式发布。通过 YAML 文件中的几行声明性语句,您可以简化许多耗时耗力的任务,例如创建地理分布式数据库以及从 Active-Active 数据库中移除、添加和更新参与集群。
许多开发者更喜欢从云端的 Redis 服务开始构建,而不是将其下载到本地机器。我们也从许多客户那里听到,对于他们混合使用的 Redis OSS、Redis Stack 和 Redis Enterprise 实例,处理新 Redis 版本的不同发布日期带来了挑战。
Redis 7.2 是我们的第一个统一 Redis 版本,现已正式发布。我们正在让开发者更容易在不同的 Redis 发行版之间构建和移植代码。这对于希望简化对其 Redis 足迹的控制的运维人员来说是一个重大利好。架构师将赞赏将其他数据存储与 Redis 集成的自由度。
我们对 Redis 社区和客户的承诺是同时发布所有 Redis 产品和发行版。这包括 Redis OSS、Redis Stack、Redis Enterprise Cloud、Redis Enterprise Software 和 Redis Enterprise on Kubernetes。
Redis 7.2 标志着我们坚定不移的承诺,即让所有 Redis 爱好者更容易开始使用 Redis 进行构建,更轻松、更经济地大规模运行 Redis,并将慢速数据带入 Redis 并使其能够实时可用。
AI 革命已经到来,它对我们的工作和生活产生的深远影响,我再怎么强调也不为过。我们对向量数据库和向量相似性搜索的关注,使其成为帮助您利用 Redis 技能快速启动 AI 项目的完美选择。
我们邀请您阅读有关 Redis Enterprise 7.2 新功能的更多详细信息,包括自动分层、Triggers and Functions以及Redis 数据集成的具体内容。
您准备好亲自试用了吗?最简单的方法是使用Redis Enterprise Cloud,创建一个免费帐户来试用 Redis Stack 的最新功能,或者下载软件进行自托管或 Kubernetes 部署。
对于公开预览中的功能,例如 Triggers and Functions,请在 Google Cloud/亚太地区(东京)或 AWS/亚太地区(新加坡)区域的固定层级部署 Redis Enterprise Cloud 上的数据库。对于自托管体验,请访问我们的下载中心。



