 Redis 8 已发布,并且是开源的
Redis 8 已发布,并且是开源的
了解更多

尽管人们对 机器学习 (ML) 普遍感兴趣,但在实时环境中有效使用它是一个复杂的问题,尚未得到框架开发人员足够的关注。几乎每种语言都有一个框架来实现机器学习的“学习”部分,但很少有框架支持机器学习的“预测”部分。
一旦您训练了一个机器学习模型,如何基于该模型构建一个实时应用程序?使用许多工具包,您必须构建自己的应用程序。我们刚刚开始看到专注于机器学习预测方面的框架。
之前的一篇文章概述了 Redis-ML 模块中可用的功能,因此在本文中,我们将更深入地探讨机器学习——以易于理解的方式解释一些技术,并展示如何使用 Redis 来增强机器学习管道。作为一个示例,我们将逐步讲解一个示例程序的代码,该程序根据社区的各种特征预测房屋中位数价格。
本文中的示例代码是用 Python 3 编写的,使用了各种免费的机器学习软件包。您需要使用 pip3 或您偏好的包管理器安装以下软件包才能运行示例
您还需要一个 Redis 4.0.0 实例和 Redis-ML 模块。Redis-ML 模块的开发者 Shay Nativ 创建了一个预装了 Redis 4.0.0 和 Redis-ML 模块的 Docker 容器。要将该容器与本文中的代码结合使用,请使用以下命令启动容器
docker run -it -p 6379:6379 shaynativ/redis-ml
Docker 将自动下载并运行容器,将容器的默认 Redis 端口 (6379) 映射到您的计算机上。
为了构建我们的房价预测器,我们将使用一种称为线性回归的机器学习技术。
线性回归在算法机器学习发明之前很久就是统计学家工具箱的一部分。通过线性回归,我们试图根据一个或多个已知量(解释变量)预测结果(有时称为因变量)。为了使线性回归奏效,我们必须能够用一条直线准确地估计我们的结果。

在上图中,取自维基百科关于线性回归的文章,我们可以看到我们的数据点如何聚集在一条理想化的直线周围。该数据集是进行线性回归的良好候选。在实践中,线性回归用于建模各种现实世界问题,其中从观察到的线性关系可以准确预测结果,例如根据房屋面积预测房价,或根据高中 GPA 和 SAT 分数预测大学 GPA。
从代数中我们知道一条线可以用形如 y = b + ax 的方程表示,因此要“学习”这种形式的模型,我们需要应用算法来发现线的参数——斜率和截距。这并不是什么特别花哨的东西,事实上,在算法机器学习出现之前,大多数统计学家都会手工“拟合”这些模型。如今,使用计算机寻找线参数更为常见,并且有各种各样的工具包(TensorFlow, Scikit, Apache Spark)可用于解决线性回归问题。重要的是要记住,一旦我们学习了线性回归模型,我们就拥有了一个可以被任何系统实现的预测结果的数学公式。
让我们通过一个使用流行的 Python scikit-learn 包和 Boston Housing 数据集执行线性回归并发现模型参数的示例。
Boston Housing 数据集是统计学和机器学习教学中使用的经典数据集。该数据集使用社区特征(如房屋的平均房间数、距离波士顿主要就业中心的距离或犯罪率)来预测波士顿地区社区的房屋中位数价格。为了更容易地可视化线性回归过程,我们将使用数据的单个特征,即每户住宅的平均房间数 (RM) 列。
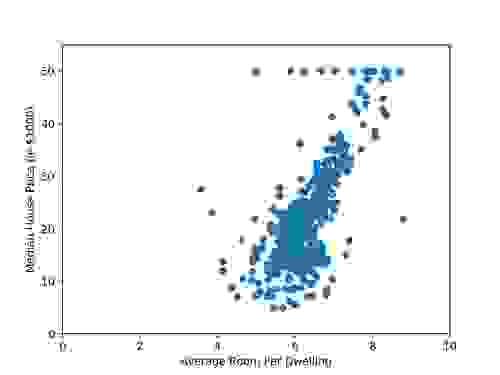
Boston Housing 数据集作为 scikit-learning 包的一部分提供,因此,让我们首先绘制数据图,以可视化房间数 (RM) 和中位数价格 (MEDV) 之间的关系
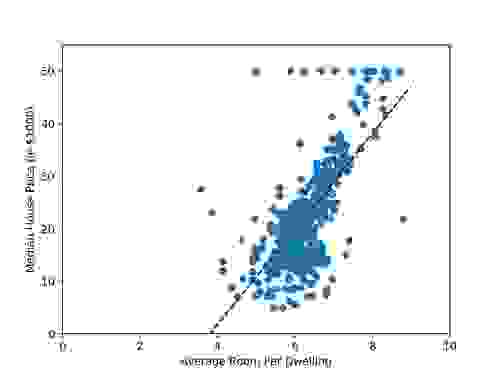
虽然不是一条完美的直线,但我们可以看到社区中房屋平均房间数与房屋中位数价格之间存在相当强的线性关系。我们甚至可以绘制这种关系的理想化表示,并查看数据点如何聚集在其周围。
以下代码演示了如何使用 scikit 加载 Boston Housing 数据集。Boston Housing 数据集包含十二种不同的用于预测房价的特征,因此在加载数据集后,我们从数据中提取第五列(RM 列)的数据作为我们的样本。
from sklearn.datasets import load_boston boston = load_boston() boston_RM = boston.data[:,5] boston_PRICE = boston.target
现在我们将数据分成两组:训练集和测试集。在我们的示例中,我们从前 400 个样本创建训练集,从剩余的 106 个样本创建测试集。
# slice the data into train and test sets x_train = boston_RM[:400].reshape(-1, 1) x_test = boston_RM[400:].reshape(-1, 1) y_train = boston.target[:400] y_test = boston.target[400:]
这种分割方法确保我们始终使用相同的集合来获得可重现的结果。
现在我们已经构建了训练集和测试集,我们可以使用 scikit 提供的 LinearRegression 模型来拟合一条直线到我们的数据
lm = LinearRegression()
lm.fit(x_train, y_train)
coef = lm.coef_[0]
int = lm.intercept_
print('Coef: {coef}, Intercept: {int}'.format(coef=coef, int=int))
运行代码后,我们发现 scikit 已经为我们的数据拟合了一条直线,其系数为 9.40550212,截距为 -35.26094818316348。
现在我们有了这些参数,我们可以实现一个线性模型,根据感兴趣的社区中房屋的平均房间数来预测波士顿地区的房价。现在我有了这个模型,我如何构建一个应用程序来实现实时预测并在应用程序或网站中使用此功能?
Scikit 包提供了一个 predict 函数来评估训练好的模型,但在应用程序中使用函数需要实现一系列其他服务以使其快速可靠。这就是 Redis 可以增强您的机器学习系统的地方。
Redis-ML 模块利用新的 Modules API 添加了标准的线性回归作为原生数据类型。该模块可以创建线性回归并使用它们来预测值。
要将线性回归添加到 Redis,您需要使用 ML.LINGREG.SET 命令将线性回归添加到数据库。ML.LINGREG.SET 命令具有以下形式
ML.LINREG.SET key intercept coeef [...]
按照惯例,Redis-ML 模块中的所有命令都以模块标识符 ML 开头。所有线性回归命令都以 LINGREG 为前缀。
要将 Redis 设置为使用我们在 scikit 中拟合的直线来预测波士顿房价的预测引擎,我们首先需要使用 loadmodule 指令加载 Redis-ML 模块。
redis-server --loadmodule /path/to/redis-ml/module.so
然后,我们使用 scikit 中的常量执行 ML.LINGREG.SET 命令来设置一个键代表我们的线性回归。请记住,截距是提供的第一个值,系数按照特征顺序提供。从我们用于将回归线拟合到住房数据的 scikit 代码中,我们确定我们的线对于 RM 变量的系数为 9.40550212,截距为 -35.26094818316348。我们可以使用 ML.LINGREG.SET 命令来设置一个 Redis 键以计算这个线性关系
127.0.0.1:6379> ML.LINREG.SET boston_house_price:rm-only -35.26094818316348 9.40550212 OK
一旦我们的boston_house_price:rm-only键创建后,我们可以使用 ML.LINGREG.PREDICT 命令反复预测社区的房屋中位数价格。要预测每户平均有 6.2 个房间的社区的房屋中位数价格,我们将运行以下命令
127.0.0.1:6379> ML.LINREG.PREDICT boston_house_price:rm-only 6.2 "23.053164960836519”
Redis 预测该社区的房屋中位数价格为 23,053 美元(请记住我们的房价单位是千)。
了解如何从 redis-cli 使用 ML.LINGREG 命令会有所帮助,但我们更有可能从应用程序中执行此操作。我们可以扩展我们用于拟合回归线的 Python 代码,以自动在 Redis 中创建 boston_house_price:rm-only 键。在 Redis 中创建键后,我们实现一个测试,使用我们的测试数据从 Redis 生成预测。
r = redis.StrictRedis('localhost', 6379)
r.execute_command("ML.LINREG.SET", "boston_house_price:rm-only", "-35.26094818316348", "9.40550212", )
redis_predict = []
for x in x_test:
y = r.execute_command("ML.LINREG.PREDICT", "boston_house_price:rm-only", x[0])
redis_predict.append(float(y))
我们还可以使用 predict 例程生成 scikit 对同一数据集的预测
y_predict = lm.predict(x_test)
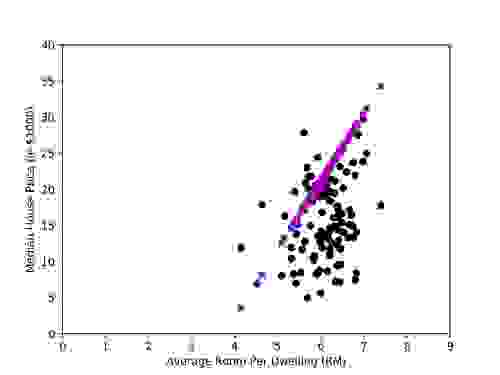
为了进行比较,我们绘制了结果。在下图中,黑色圆圈代表数据集中测试数据的实际价格。蓝色标记 (+) 代表 Scikit 预测的值,品红色标记 (x) 代表 Redis 预测的值。
如您所见,在给定平均房间数的情况下,Redis 和 scikit 对房屋中位数价格做出了相同的预测。虽然线性回归可能无法正确预测每个数据点的确切价格,但它提供了一种有用的方法来根据社区的一些可观察特征估计未知价格。
在本文中,我们更深入地探讨了 Redis-ML 的线性回归功能。我们介绍了如何使用流行的 scikit Python 包将线性回归线拟合到一些房屋数据,然后使用 Redis 4.0.0 和 Redis-ML 模块创建一个房价预测引擎。
在本系列的下一部分,我们将介绍如何使用 Redis-ML 来实现一个分类引擎,分类是另一种机器学习问题,旨在从之前的示例中确定未知数据的类别。

