 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多

本文是探讨 Redis-ML 模块功能的系列文章的第五部分。该系列的第一篇文章可以在这里找到。本文包含的示例代码需要几个 Python 库和一个加载了 Redis-ML 模块的 Redis 实例。运行时环境的详细设置说明在第一部分和第二部分中提供。
决策树
决策树 是用于机器学习中分类和回归问题的预测模型。 决策树将规则序列建模为二叉树。 树的内部节点代表一个分裂或规则,叶子代表一个分类或值。
树中的每个规则都在数据集的单个特征上运行。 如果满足规则的条件,则移动到左子节点; 否则移动到右子节点。 对于分类特征(枚举),规则使用的测试是特定类别的成员资格。
对于具有连续值的特征,测试是“小于”或“等于”。 要评估数据点,请从根节点开始并通过评估内部节点中的规则来遍历树,直到到达叶节点。 叶节点标有要返回的决策。 示例决策树如下所示
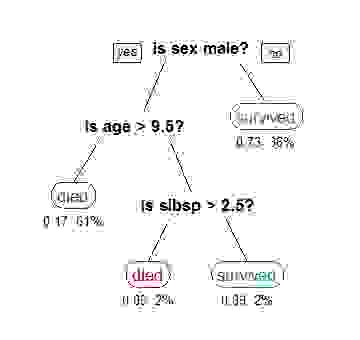
可以使用许多不同的算法(递归分区、自上而下的归纳等)来构建决策树,但评估过程始终相同。 为了提高决策树的准确性,通常将它们聚合到随机森林中,随机森林使用多棵树来对数据点进行分类,并将所有树中的多数决策作为最终分类。
为了演示决策树的工作原理以及如何在 Redis 中表示决策树,我们将使用 scikit-learn Python 包和 Redis 构建一个泰坦尼克号生存预测器。
泰坦尼克号数据集
1912 年 4 月 15 日,泰坦尼克号在北大西洋与冰山相撞后沉没。 超过 1500 名乘客因碰撞而死亡,使其成为现代历史上最致命的商业海难之一。 虽然幸存者中存在一些运气成分,但查看数据表明,一些乘客群体比其他群体更容易幸存下来。
泰坦尼克号数据集,其副本可在此处获取:这里,是机器学习中使用的经典数据集。我们用于本文的数据集副本来自范德比尔特档案馆,包含泰坦尼克号上 1309 名乘客的记录。这些记录包含 14 个不同的字段:乘客等级、是否幸存、姓名、性别、年龄、兄弟姐妹/配偶数量、父母/子女数量、票号、票价、船舱、登船港口、救生艇、尸体编号和目的地。
在 Excel 中粗略扫描我们的数据表明我们的数据集中存在大量缺失数据。缺失字段将影响我们的结果,因此我们需要在构建决策树之前对我们的数据进行一些清理。我们将使用 pandas 库来预处理我们的数据。 您可以使用 pip(Python 包管理器)安装 pandas 库:
pip install pandas
或您喜欢的包管理器。
使用 pandas,我们可以快速分解数据中每个记录类的值的计数
pclass 1309 survived 1309 name 1309 sex 1309 age 1046 sibsp 1309 parch 1309 ticket 1309 fare 1308 cabin 295 embarked 1307 boat 486 body 121 home.dest 745
由于船舱、救生艇、尸体和 home.dest 记录缺少大量记录,我们将直接从数据集中删除它们。 我们还将删除票证字段,因为它几乎没有预测价值。 对于我们的预测器,我们最终构建了一个包含乘客等级 (pclass)、生存状态 (survived)、性别、年龄、兄弟姐妹/配偶数量 (sibsp)、同船父母/子女数量 (parch)、票价和登船港口 (“embarked”) 记录的特征集。 即使在删除了稀疏填充的列之后,仍然有几行缺少数据,因此为了简单起见,我们将从数据集中删除这些乘客记录。
数据清理的初始阶段使用以下代码完成
import pandas as pd # load data from excel orig_df = pd.read_excel('titanic3.xls', 'titanic3', index_col=None)
# remove columns we aren't going to work with, drop rows with missing data df = orig_df.drop([“name”, "ticket", "body", "cabin", "boat", "home.dest"], axis=1) df = df.dropna()
我们需要对数据执行的最终预处理是使用整数常量对分类数据进行编码。 pclass 和 survived 列已经编码为整数常量,但 sex 列记录了字符串值 male 或 female,并且 embarked 列使用字母代码来表示每个港口。 scikit 包在预处理子包中提供了用于执行数据编码的实用程序。
清理数据的第二阶段,转换非整数编码的分类特征,使用以下代码完成
from sklearn import preprocessing # convert enumerated columns (sex,) encoder = preprocessing.LabelEncoder() df.sex = encoder.fit_transform(df.sex) df.embarked = encoder.fit_transform(df.embarked)
现在我们已经清理了我们的数据,我们可以计算按乘客等级 (pclass) 和性别分组的几个特征列的平均值。
survived age sibsp parch fare pclass sex 1 female 0.961832 36.839695 0.564885 0.511450 112.485402 male 0.350993 41.029250 0.403974 0.331126 74.818213 2 female 0.893204 27.499191 0.514563 0.669903 23.267395 male 0.145570 30.815401 0.354430 0.208861 20.934335 3 female 0.473684 22.185307 0.736842 0.796053 14.655758 male 0.169540 25.863027 0.488506 0.287356 12.103374
请注意,基于乘客等级,男性和女性之间的生存率存在显着差异。 我们的决策树构建算法将发现这些统计差异,并使用它们来选择要拆分的特征。
构建决策树
我们将使用 scikit-learn 在我们的数据上构建决策树分类器。 我们首先将清理后的数据分成训练集和测试集。 使用以下代码,我们从特征集中分离出数据的标签列(survived),并保留数据的最后 20 条记录作为测试集。
X = df.drop(['survived'], axis=1).values Y = df['survived'].values X_train = X[:-20] X_test = X[-20:] Y_train = Y[:-20] Y_test = Y[-20:]
一旦我们有了训练集和测试集,我们就可以创建一个最大深度为 10 的决策树。
# Create the real classifier depth=10 cl_tree = tree.DecisionTreeClassifier(max_depth=10, random_state=0) cl_tree.fit(X_train, Y_train)
我们的深度为 10 的决策树很难在博客文章中可视化,因此为了可视化决策树的结构,我们创建了第二棵树并将树的深度限制为 3。下图显示了分类器学习的决策树的结构
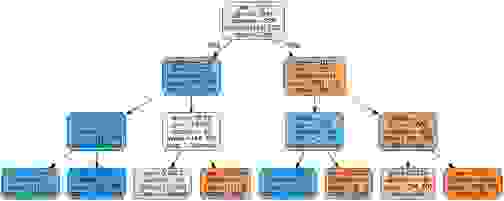
加载 Redis 预测器
Redis-ML 模块提供了两个用于处理随机森林的命令:ML.FOREST.ADD 用于在森林上下文中创建决策树,ML.FOREST.RUN 用于使用随机森林评估数据点。 ML.FOREST 命令具有以下语法
ML.FOREST.ADD key tree path ((NUMERIC|CATEGORIC) attr val | LEAF val [STATS]) [...] ML.FOREST.RUN key sample (CLASSIFICATION|REGRESSION)
Redis-ML 中的每个决策树都必须使用单个 ML.FOREST.ADD 命令加载。 ML.FOREST.ADD 命令由一个 Redis 键组成,后跟一个整数树 ID,然后是节点规范。 节点规范由一个路径组成,该路径是一系列 。 (根)、l 和 r,表示树中节点的路径。 内部节点是分割器或规则节点,并使用 NUMERIC 或 CATEGORIC 关键字来指定规则类型、要测试的属性以及要拆分的阈值的值。 对于 NUMERIC 节点,该属性会根据阈值进行测试,如果小于或等于阈值,则采用左侧路径;否则采用右侧路径。 对于 CATEGORIC 节点,测试是相等。 相等的值采用左侧路径,不相等的值采用右侧路径。
scikit-learn 中的决策树算法将分类属性视为数值属性,因此当我们在 Redis 中表示树时,我们将仅使用 NUMERIC 节点类型。 要将 scikit 树加载到 Redis 中,我们将需要实现一个遍历树的例程。 以下代码执行 scikit 决策树的先序遍历以生成 ML.FOREST.ADD 命令(由于我们只有一棵树,因此我们生成一个只有一棵树的简单森林)。
# scikit represents decision trees using a set of arrays, # create references to make the arrays easy to access the_tree = cl_tree t_nodes = the_tree.tree_.node_count t_left = the_tree.tree_.children_left t_right = the_tree.tree_.children_right t_feature = the_tree.tree_.feature t_threshold = the_tree.tree_.threshold t_value = the_tree.tree_.value feature_names = df.drop(['survived'], axis=1).columns.values # create a buffer to build up our command forrest_cmd = StringIO() forrest_cmd.write("ML.FOREST.ADD titanic:tree 0 ") # Traverse the tree starting with the root and a path of “.” stack = [ (0, ".") ] while len(stack) > 0: node_id, path = stack.pop() # splitter node -- must have 2 children (pre-order traversal) if (t_left[node_id] != t_right[node_id]): stack.append((t_right[node_id], path + "r")) stack.append((t_left[node_id], path + "l")) cmd = "{} NUMERIC {} {} ".format(path, feature_names[t_feature[node_id]], t_threshold[node_id]) forrest_cmd.write(cmd) else: cmd = "{} LEAF {} ".format(path, np.argmax(t_value[node_id])) forrest_cmd.write(cmd) # execute command in Redis r = redis.StrictRedis('localhost', 6379) r.execute_command(forrest_cmd.getvalue())
比较结果
将决策树加载到 Redis 后,我们可以创建两个向量来比较 Redis 的预测结果与 scikit-learn 的预测结果
# generate a vector of scikit-learn predictors s_pred = cl_tree.predict(X_test) # generate a vector of Redis predictions r_pred = np.full(len(X_test), -1, dtype=int) for i, x in enumerate(X_test): cmd = "ML.FOREST.RUN titanic:tree " # iterate over each feature in the test record to build up the # feature:value pairs for j, x_val in enumerate(x): cmd += "{}:{},".format(feature_names[j], x_val) cmd = cmd[:-1] r_pred[i] = int(r.execute_command(cmd))
要使用 ML.FOREST.RUN 命令,我们必须生成一个特征向量,该特征向量由以逗号分隔的 <feature>:<value> 对的列表组成。 向量的 <feature> 部分是一个字符串特征名称,必须与 ML.FOREST.ADD 命令中使用的特征名称相对应。
将 r_pred 和 s_pred 预测值与实际标签值进行比较
Y_test: [0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 0 0] r_pred: [1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0] s_pred: [1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0]
Redis 的预测与 scikit-learn 包的预测相同,包括测试项目 0 和 14 的错误分类。
乘客的生存几率与等级和性别密切相关,因此存在一些令人惊讶的案例,即一些具有较高生存概率的个人实际上已经丧生。 调查其中一些异常值会导致那次命运攸关的航行中引人入胜的故事。 有许多在线资源讲述了泰坦尼克号乘客和船员的故事,向我们展示了数据背后的人们。 我鼓励您调查一些被错误分类的人,并了解他们的故事。
在下一篇也是最后一篇文章中,我们将把所有内容联系起来,并结束对 Redis-ML 的介绍。与此同时,如果您对此或之前的文章有任何疑问,请在 Twitter 上与我联系 (@tague)。

