 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多

这篇文章是介绍 Redis-ML 模块的系列文章的第三部分。该系列的第一篇文章可以在这里找到。本文的示例代码需要几个 Python 库和一个运行 Redis-ML 的 Redis 实例。 运行代码的详细设置说明可以在本系列的第一部分或第二部分中找到。
Logistic 回归
Logistic 回归是另一种线性模型,用于从观察到的数据构建预测模型。与用于预测值的线性回归不同,logistic 回归用于预测二元值(通过/失败、赢/输、健康/生病)。这使得 logistic 回归成为一种分类形式。基本的 logistic 回归可以进行扩充,以解决多类分类问题。
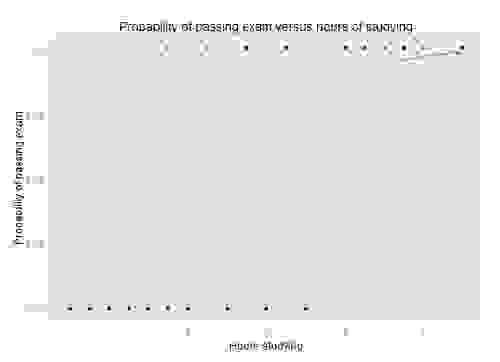
上面的例子,取自 维基百科关于 Logistic 回归的文章,显示了相对于学习时间,考试通过的概率图。 Logistic 回归是解决此问题的好技术,因为我们试图确定通过/失败,这是一个二元选择器。 如果我们想确定考试的等级或百分比,简单的回归将是一种更好的技术。
为了演示 logistic 回归以及如何在 Redis 中使用它,我们将探索另一个经典数据集,费希尔鸢尾花植物数据集。
数据集
费希尔鸢尾花数据库包含 150 个数据点,标记为 3 种不同的鸢尾花:鸢尾花 Setosa、鸢尾花 Versicolor 和 鸢尾花 Virginica。 每个数据点都包含植物的四个属性(特征)。 使用 logistic 回归,我们可以使用这些属性将鸢尾花分类为三种中的一种。
费希尔鸢尾花数据库是 Python scikit learn 包中包含的数据集之一。 要加载数据集,请使用以下代码
from sklearn.datasets import load_iris iris = load_iris()
我们可以将数据打印在表格中,看到我们的数据包括萼片长度、萼片宽度、花瓣长度和花瓣宽度,所有单位均为厘米。
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
5 5.4 3.9 1.7 0.4
我们的目标分类被编码为整数值 0、1 和 2。0 对应于鸢尾花 Setosa,1 对应于鸢尾花 Versicolor,2 对应于鸢尾花 Virginica。
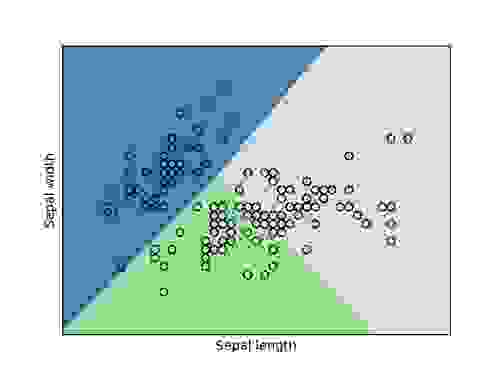
为了更好地了解各种测量值与花类型之间的关系,我们生成了两个图:一个是萼片宽度与长度的图,另一个是花瓣宽度与长度的图。 每个图都显示了三个类的分类边界(通过 logistic 回归确定),并将其与我们数据集中的点叠加在一起。 蓝色代表被分类为鸢尾花 Setosa 的区域,绿色代表鸢尾花 Versicolor,灰色代表鸢尾花 Virginica
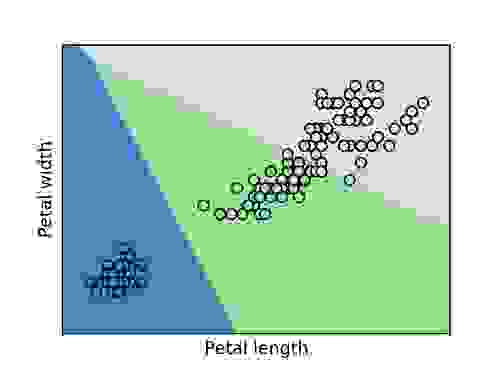
我们可以在两个图中看到,有一些离群值被错误分类,但我们的大多数鸢尾花类型聚集在一起,形成不同的组。
执行 Logistic 回归
在 scikit 中执行 logistic 回归的代码与我们之前用于执行线性回归的代码类似。 我们首先需要创建我们的训练集和测试集,然后拟合一个 logistic 回归。
要拆分训练集和测试集,我们使用以下代码
x_train = [ x for (i, x) in enumerate(iris.data) if i%10 !=0 ] x_test = [x for (i, x) in enumerate(iris.data) if i%10 == 0 y_train = [ y for (i, y) in enumerate(iris.target) if i%10 != 0 ] y_test = [ y for (i, y) in enumerate(iris.target) if i%10 == 0 ]
在本示例中,我们将数据拆分为 10 个元素的块,将第一个元素放入测试集,其余 9 个元素放入训练集。 为了确保我们的数据包含来自所有三个类的选择,我们需要在本示例中使用比以前的示例更复杂的过程。
一旦我们构建了训练集和测试集,拟合 logistic 回归需要两行代码
logr = LogisticRegression() logr.fit(x_train, y_train) y_pred = logr.predict(x_test)
最后一行代码使用我们训练好的 logistic 回归来预测我们测试集的鸢尾花类型。
Redis 预测器
与我们的线性回归示例一样,我们可以使用 Redis 构建一个 logistic 回归预测器。
Redis-ML 模块提供 ML.LOGREG.SET 和 ML.LOGREG.PREDICT 函数来创建 logistic 回归键。
要将 logistic 回归模型添加到 Redis,您需要使用 ML.LOGREG.SET 命令将键添加到数据库。 ML.LOGREG.SET 命令具有以下形式:
ML.LINREG.SET key intercept coeef [...]
并且 ML.LOGREG.PREDICT 函数用于从特征值评估 logistic 回归,其形式为:
ML.LOGREG.PREDICT key feature [...]
PREDICT 命令中特征值的顺序必须与系数对应。 PREDICT 命令的结果是观察结果属于特定类的概率。
要使用 Redis 构建多类分类器,我们必须模拟用于多类分类的一对多过程。 在一对多过程中,创建多个分类器,每个分类器用于确定观察结果属于特定类的概率。 然后,观察结果被标记为最有可能属于的类。
对于我们的三类鸢尾花问题,我们将需要创建三个单独的分类器,每个分类器确定数据点属于该特定类的概率。 scikit LogisticRegression 对象默认为一对多(scikit API 中的 ovr),并拟合三个单独分类器的系数。
为了在 Redis 中模拟此过程,我们首先创建三个 logistic 回归键,对应于 scikit 拟合的系数
r = redis.StrictRedis('localhost', 6379) for i in range(3): r.execute_command("ML.LOGREG.SET", "iris-predictor:{}".format(i), logr.intercept_[i], *logr.coef_[i])
我们模拟了在 LogisticRegression.predict 函数中发生的一对多预测过程,方法是迭代我们的三个键,然后取概率最高的类。 以下代码对我们的测试数据执行一对多过程,并将结果标签存储在向量中:
# Run predictions in Redis r_pred = np.full(len(x_test), -1, dtype=int) for i, obs in enumerate(x_test): probs = np.zeros(3) for j in range(3): probs[j] = float(r.execute_command("ML.LOGREG.PREDICT", "iris-predictor:{}".format(j), *obs)) r_pred[i] = probs.argmax()
我们通过打印出三个结果向量来比较最终分类
# Compare results as numerical vector print("y_test = {}".format(np.array(y_test))) print("y_pred = {}".format(y_pred)) print("r_pred = {}".format(r_pred))
输出向量显示了实际的鸢尾花种类 (y_test) 以及 scikit (y_pred) 和 Redis (r_pred) 所做的预测。 每个向量都将输出存储为标签的有序序列,编码为整数。
y_test = [0 0 0 0 0 1 1 1 1 1 2 2 2 2 2] y_pred = [0 0 0 0 0 1 1 2 1 1 2 2 2 2 2] r_pred = [0 0 0 0 0 1 1 2 1 1 2 2 2 2 2]
Redis 和 scikit 做出了相同的预测,包括将一种 Virginica 错误标记为 Versicolor。
您可能不需要高度可用、实时的鸢尾花分类器,但通过利用这个经典数据集,您已经了解了如何使用 Redis-ML 模块来为您自己的数据实现高度可用、实时的分类器。
在下一篇文章中,我们将继续研究 Redis-ML 模块的特性,研究 Redis-ML 支持的矩阵运算以及如何使用它们来解决 ML 问题。 在此之前,如果您对这些文章有任何疑问,请在 Twitter 上与作者联系 (@tague)。

