 Redis 8 发布了 — 并且它是开源的
Redis 8 发布了 — 并且它是开源的
了解更多
我们这些使用 Redis 和 Memcached 的人都知道,它们从头开始设计,旨在为应用提供最高的吞吐量和最低的延迟,它们实际上是当今最快的数据存储系统。它们从 RAM 提供数据,并以 O(1) 复杂度执行所有简单操作(例如 SET 和 GET)。然而,当在 AWS 等云基础设施上运行时,Redis 或 Memcached 在不同实例和平台上的性能可能会出现显著差异,这会极大地影响应用的性能。作为托管 Redis 和 Memcached 数据集的云服务提供商,我们 Garantia Data 始终致力于优化性能的最佳实践,因此我们最近进行了一项基准测试,比较了在不同 AWS 实例和平台上运行的中小型(<=12GB)Redis 和 Memcached 数据集。
架构考量
在构建基准测试时,我们首先考虑的是我们希望比较的各种架构方案。用户通常会根据数据集的初始大小估算选择最经济的 AWS 实例,然而,至关重要的是还要记住,其他 AWS 用户可能共享运行您数据的同一物理服务器(Adrian Cockcroft 这里 有很好的解释)。如果您使用中小型数据集,尤其如此,因为 m1.small 和 m1.large 之间的实例比 m2.2xlarge 和 m2.4xlarge 等大型实例更有可能共享物理服务器,后者通常在专用物理服务器上运行。一旦您的“邻居”开始占用您物理服务器过多的 I/O 和 CPU 资源,他们就可能变得“嘈杂”。此外,中小型实例的处理能力天生就弱于大型实例。您的实例选择可能会对 Redis/Memcached 的性能产生重大影响,Redis/Memcached 通常使用最优的代码行数来运行每个命令。任何“嘈杂邻居”的轻微干扰或处理能力不足导致的操作延迟(例如内存访问、网络传输或上下文切换)都会显著降低吞吐量并增加延迟。 因此,可以合理地认为,使用中小型 AWS 实例运行 Redis 或 Memcached 数据的应用更容易出现性能下降。在 AWS 上运行 Redis 或 Memcached 的另一种方式是使用服务,例如 AWS ElastiCache(用于 Memcached),或我们自己的 Redis Cloud 或 Memcached Cloud。然而,使用 ElastiCache 时,用户仍然需要选择实例大小,因此可能会遇到相同的性能问题。Garantia Data 的 Redis Cloud 和 Memcached Cloud 采用了不同的方法:我们在 m2.2xlarge 或 m2.4xlarge 实例上运行所有集群节点,以确保最佳性能,但我们仅根据用户的实际数据集大小(以 GB 为单位)收费。有关我们如何设置基准测试的所有详细信息,包括资源、数据集和配置,请随时跳转到文章末尾。
基准测试结果
闲话少说,以下是我们关于在 AWS 上运行 Redis 和 Memcached 的各种方案在性能方面比较的结果。
吞吐量
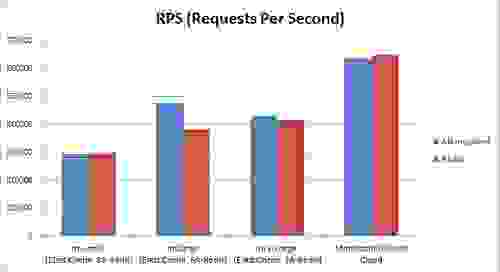
注意:ElastiCache 在 m1.large 实例上使用 2 个 Memcached 线程,在 m1.xlarge 实例上使用 4 个线程,而独立 Redis 基于单线程架构 如上所示,Garantia Data Memcached/Redis Cloud 的 RPS(每秒请求数)比 ElastiCache 或独立 Redis 好 25-100%(取决于实例类型)。
延迟
我们还看到,我们的 Memcached/Redis Cloud 集群的平均响应时间比 ElastiCache 或独立 Redis 好 25-50%,而其 99% 分位数的响应时间显著更好,比 ElastiCache 或独立 Redis 快 6-30 倍。
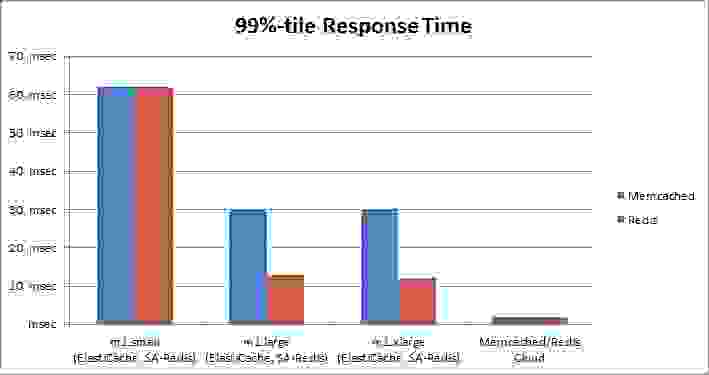
注意:我们的响应时间测量考虑了网络往返时间、Redis/Memcached 处理时间以及 memtier_benchmark 工具解析结果所需的时间。
结论
这项基准测试表明,不同的架构方法可以提高云中 Redis 和 Memcached 的吞吐量并显著降低延迟。我们相信这些发现可以用我们 Redis Cloud 和 Memcached Cloud 服务的独特架构来解释。我们 Garantia Data 开发了几种技术,这些技术运行在我们集群的每个节点上,并保证用户之间的干扰最小化,即:
在幕后,我们监控每一个 Redis 或 Memcached 命令,并不断将其响应时间与应该有的最优值进行比较。此外,我们以非侵入的方式实时重新分片数据集,这是一项非常具有挑战性的操作,涉及多个分布式元素之间复杂的同步机制。这种架构允许任何大小的数据集(包括中小型数据集)的用户在最强大的实例上运行并享受最高性能,同时仅按小时为实际使用的 GB 付费——这样我们的客户就能获得两全其美的体验。
基准测试设置
我们知道您想了解我们基准测试的详细信息,以下是我们使用的资源:
这是我们生成负载的设置
我们在每种配置上运行了 3 次测试,并使用以下参数计算平均结果:
我们的数据集大小包括


