 Redis 8 已发布——并且它是开源的
Redis 8 已发布——并且它是开源的
了解更多


从最早的版本开始,Kong 就已支持 Redis。如今,Kong API 网关和 Redis 集成是一种强大的组合,可以在三个主要用例组中增强 API 管理
Kong 支持适用于所有用例的多种类型的 Redis 部署,包括 Redis 社区版(包括在使用 Redis Cluster 进行水平扩展或使用 Redis Sentinel 实现高可用性时)、Redis Software(提供生产工作负载常需要的企业级功能)以及 Redis Cloud(可在 AWS、GCP 上使用,也可作为 Azure 中的 Azure 管理型 Redis 使用)。
在这篇文章中,我们将重点介绍如何使用 Kong 和 Redis 来解决语义处理用例,包括跨多个 LLM 环境的相似性搜索和语义路由。
首先,让我们看看 Kong AI 网关的高级参考架构。如您所见,负责处理传入流量的 Kong Gateway 数据平面可以配置两种类型的 Kong 插件
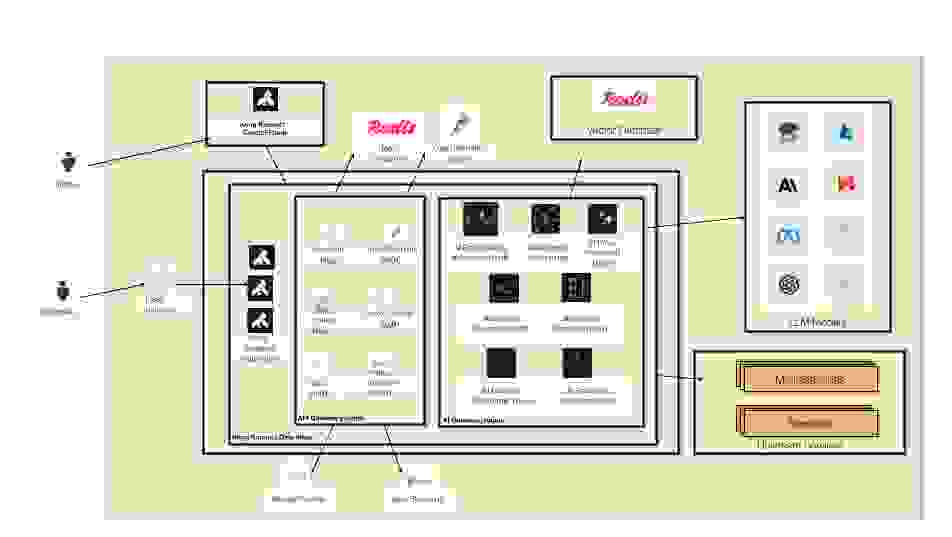
Kong Gateway 提供的主要能力之一是可扩展性。丰富的插件列表允许您实施特定的策略来保护和控制部署在网关中的 API。插件负责分担通常由后端服务和应用实现的复杂而关键的处理工作。通过使用网关及其插件,后端服务可以只专注于业务逻辑,从而加快应用开发过程。每个插件负责特定的功能,包括
此外,Kong API 网关还提供了多个与 Redis 集成的插件,包括
另一方面,Kong AI 网关利用现有的 Kong API 网关可扩展性模型来提供特定的基于 AI 的插件,更精确地保护 LLM 基础设施,包括
通过利用 Kong Gateway 相同的底层核心,并结合这两类插件,我们可以实现强大的策略,并降低部署 AI 网关功能的复杂性。
我们要关注的第一个用例是语义缓存,其中 AI 网关插件与 Redis 集成以执行相似性搜索。然后,我们将探讨高级 AI 代理插件如何利用 Redis 来实现跨多个 LLM 模型的语义路由。
Kong 和 Redis 的另外两个值得注意的用例是高级 AI 速率限制和 AI 语义提示保护插件,但我们不会在本文中详细介绍它们。
在深入探讨第一个用例之前,让我们强调并总结一下 Kong AI 网关和 Redis 所依赖的主要概念。
嵌入,也称为向量或向量嵌入,是文本、图像等非结构化数据的表示形式。在 LLM 环境中,嵌入的维度是指在给定句子的向量表示中捕获的特征数量——嵌入的维度越多,它就越好、越有效。
NLP 中有多种基于机器学习的嵌入方法,例如
这里有一个使用Sentence Transformers模块(也称为 SBERT 或 Sentence-BERT,由Hugging Face维护),并使用“all-mpnet-base-v2”嵌入模型将一个简单句子编码为嵌入的 Python 脚本示例
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import truncate_embeddings
model = SentenceTransformer('all-mpnet-base-v2', cache_folder="./")
embeddings = model.encode("Who is Joseph Conrad?")
embeddings = truncate_embeddings(embeddings, 3)
print(embeddings.size)
print(embeddings)
“all-mpnet-base-v2”嵌入模型将句子编码为 768 维向量。作为实验,我们仅将向量截断为 3 维。
输出应如下所示
3
[ 0.06030013 -0.00782523 0.01018228]
向量数据库存储和搜索向量嵌入。它们对于支持图像、文本等的基于 AI 的应用至关重要,这些应用提供向量存储、向量索引以及——更重要的是——实现向量相似性搜索的算法。
我们已经撰写了一些关于将 Redis 用于向量嵌入和向量数据库的介绍。我们非常适合这些用例的原因在于 Redis Query Engine——Redis 内置的一项功能,提供向量搜索功能(以及全文、数字等其他类型的搜索),并提供行业领先的性能。Redis 利用内存数据结构和高级优化,以亚毫秒级的延迟提供了无与伦比的性能,为大规模实时应用提供支持。这对于网关用例至关重要,因为部署发生在 LLM 查询的“热路径”中。
此外,Redis 可以部署为企业软件和/或云服务,从而增加了多项企业级功能,包括
通过相似性搜索,我们可以在通常是非结构化的数据集中找到与某个呈现项目相似(或不相似)的项目。例如,给定一张手机图片,尝试查找与其形状、颜色等相似的手机图片。或者,给定两张图片,检查它们之间的相似度得分。
在我们的 NLP 环境中,我们关注应用向 LLM 发送提示时返回的相似响应。例如,以下两个句子:“谁是约瑟夫·康拉德?”和“告诉我更多关于约瑟夫·康拉德的信息”,从语义上讲,它们的相似度得分应该很高。
我们可以扩展我们的 Python 脚本来试试看
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-mpnet-base-v2', cache_folder="./")
sentences = [
"Who is Joseph Conrad?",
"Tell me more about Joseph Conrad.",
"Living is easy with eyes closed.",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
输出应如下所示。嵌入是
(3, 768)
tensor([[1.0000, 0.8600, 0.0628],
[0.8600, 1.0000, 0.1377],
[0.0628, 0.1377, 1.0000]])
“shape”由 3 个各 768 维的嵌入组成。代码要求交叉检查所有嵌入的相似度。它们越相似,得分越高。请注意,如预期,当自检查给定嵌入时,会返回“1.0000”的得分。
“similarity”方法返回一个“Tensor”对象,该对象由 Sentence Transformer 使用的 ML 库PyTorch实现。
有几种计算相似度的技术,包括向量之间的距离或角度。最常用的方法是
在向量数据库环境中,向量相似性搜索 (VSS) 是指在向量数据库中查找与给定查询向量相似的向量的过程。
2022 年,Redis 推出了搜索——一个基于 Redis 数据存储构建的文本搜索引擎,带有 RedisVSS(向量相似性搜索)。
为了更好地理解 RedisVSS 的工作原理,请看这个实现基本相似性搜索的 Python 脚本
import redis
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
from redis.commands.search.query import Query
import numpy as np
import openai
import os
### Get environment variables
openai.api_key = os.getenv("OPENAI_API_KEY")
host = os.getenv("REDIS_LB")
### Create a Redis Index for the Vector Embeddings
client = redis.Redis(host=host, port=6379)
try:
client.ft('index1').dropindex(delete_documents=True)
except:
print("index does not exist")
schema = (
TextField("name"),
TextField("description"),
VectorField(
"vector",
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": 1536,
"DISTANCE_METRIC": "COSINE",
}
),
)
definition = IndexDefinition(prefix=["vectors:"], index_type=IndexType.HASH)
res = client.ft("index1").create_index(fields=schema, definition=definition)
### Step 1: call OpenAI to generate Embeddings for the reference text and stores it in Redis
name = "vector1"
content = "Who is Joseph Conrad?"
redis_key = f"vectors:{name}"
res = openai.embeddings.create(input=content, model="text-embedding-3-small").data[0].embedding
embeddings = np.array(res, dtype=np.float32).tobytes()
pipe = client.pipeline()
pipe.hset(redis_key, mapping = {
"name": name,
"description": content,
"vector": embeddings
})
res = pipe.execute()
### Step 2: perform Vector Range queries with 2 new texts and get the distance (similarity) score
query = (
Query("@vector:[VECTOR_RANGE $radius $vec]=>{$yield_distance_as: distance_score}")
.return_fields("id", "distance_score")
.dialect(2)
)
# Text #1
content = "Tell me more about Joseph Conrad"
res = openai.embeddings.create(input=content, model="text-embedding-3-small").data[0].embedding
new_embeddings = np.array(res, dtype=np.float32).tobytes()
query_params = {
"radius": 1,
"vec": new_embeddings
}
res = client.ft("index1").search(query, query_params).docs
print(res)
# Text #2
content = "Living is easy with eyes closed"
res = openai.embeddings.create(input=content, model="text-embedding-3-small").data[0].embedding
new_embeddings = np.array(res, dtype=np.float32).tobytes()
query_params = {
"radius": 1,
"vec": new_embeddings
}
res = client.ft("index1").search(query, query_params).docs
print(res)
首先,脚本创建一个索引来接收 OpenAI 返回的嵌入。我们使用的是“text-embedding-3-small” OpenAI 模型,它有 1536 个维度,因此索引定义了一个 VectorField 来支持这些维度。
接下来,脚本有两个步骤
这是一张表示这些步骤的图表

此代码假定您已有一个可用的 Redis 环境。请查阅Redis 产品文档以了解更多信息。它还假定您已定义了两个环境变量:OpenAI API 密钥和 Redis 可用的负载均衡器地址。
该脚本使用两个主要库编写
While executing the code, you can monitor Redis with, for example, redis-cli monitor. The code line res = client.ft("index1").search(query, query_params).docs
should log a message like this one:
"FT.SEARCH" "index1" "@vector:[VECTOR_RANGE $radius $vec]=>{$YIELD_DISTANCE_AS: score}" "RETURN" "2" "id" "score" "DIALECT" "2"
"LIMIT" "0" "10" "params" "4" "radius" "1" "vec" "\xcb9\x9c<\xf8T\x18=\xaa\xd4\xb5\xbcB\xc0.=\xb5………."
让我们检查一下命令。隐式地,.ft(“index1”)方法调用使我们能够支持Redis 搜索命令,因为 .search(query, query_params) 调用发送的是使用 FT.SEARCH Redis 命令的实际搜索查询。
FT.SEARCH 命令接收在 query 和 query_params 对象中定义的参数。使用 Query 对象定义的 query parameter 指定实际的命令以及返回字段和方言。
query = (
Query("@vector:[VECTOR_RANGE $radius $vec]=>{$yield_distance_as: distance_score}")
.return_fields("id", "distance_score")
.dialect(2)
)
我们要返回距离(相似度)得分,因此必须通过 $yield_distance_as 属性来获取它。
查询方言允许增强查询 API,在保持与现有应用兼容性的同时引入新功能。对于像我们这样的向量查询,查询方言的值应设置为等于或大于 2。请查阅特定的查询方言文档页面以了解更多信息。
另一方面,query_params 对象定义了额外的参数,包括半径和应该考虑用于搜索的嵌入。
query_params = {
"radius": 1,
"vec": new_embeddings
}
最终的 FT.SEARCH 还包括定义偏移量和结果数量的参数。请查阅我们的文档以了解更多信息。
事实上,脚本发送的 FT.SEARCH 命令只是 Redis 支持的向量搜索的一个示例。基本上,Redis 支持两种主要类型的搜索
我们脚本的目的是检查两个向量之间的距离,而不是实现任何过滤。这就是为什么它将向量范围查询的 “radius” 设置为 1。
运行脚本后,其输出应为
[Document {'id': 'vectors:vector1', 'payload': None, 'distance_score': '0.123970687389'}]
[Document {'id': 'vectors:vector1', 'payload': None, 'distance_score': '0.903066933155'}]
这意味着,正如预期,与参考文本“谁是约瑟夫·康拉德?”相关的存储嵌入,与第一个新文本“告诉我更多关于约瑟夫·康拉德的信息”更接近,而不是与第二个新文本“闭着眼睛生活很轻松”。
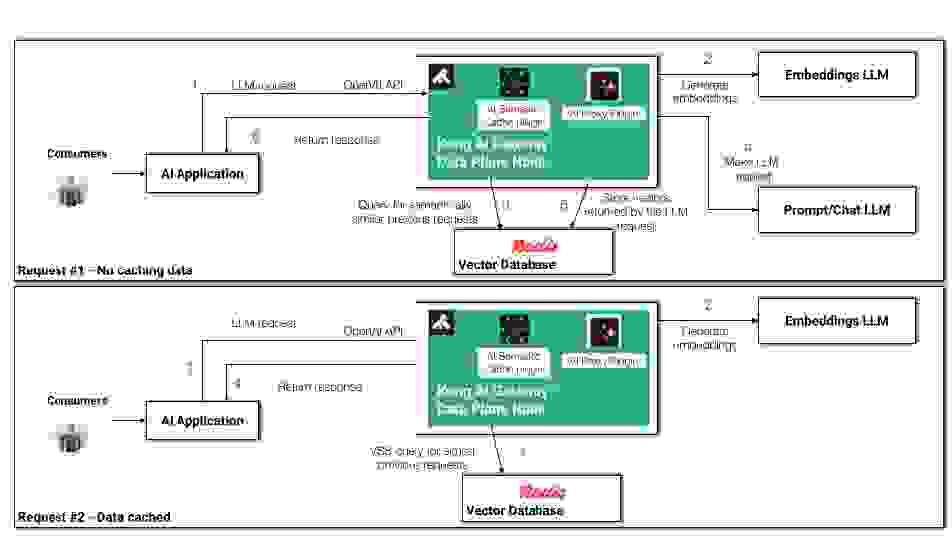
现在我们已经初步了解了如何使用 Redis 实现向量相似性搜索,接下来我们将研究负责实现语义缓存的 Kong AI 网关语义缓存插件。我们将看到它执行的搜索与我们使用 Python 脚本执行的搜索类似。
首先,从逻辑上讲,我们可以从两个不同的角度分析缓存流程
这是一张说明这些场景的图表
在探讨 Kong AI 网关语义缓存插件和 Redis 如何协同工作之前,我们必须部署一个 Konnect 数据平面(基于 Kong Gateway)。请参考Konnect 文档来注册并启动您的第一个数据平面。
接下来,我们需要创建 Kong Gateway 对象(Kong Gateway 服务、Kong 路由和 Kong 插件)来实现用例。有几种方法可以做到这一点,包括 Konnect RESTful API、Konnect GUI 等。使用decK(Kong 的声明),我们可以以声明方式管理 Kong Konnect 配置和创建 Kong 对象。请查阅decK 文档以了解如何将其与 Konnect 结合使用。
以下是我们将提交给 Konnect 以实现语义缓存用例的 decK 声明
_format_version: "3.0"
_info:
select_tags:
- semantic-cache
_konnect:
control_plane_name: default
services:
- name: service1
host: localhost
port: 32000
routes:
- name: route1
paths:
- /openai-route
plugins:
- name: ai-proxy
instance_name: ai-proxy-openai-route
enabled: true
config:
auth:
header_name: Authorization
header_value: Bearer <your_OPENAI_APIKEY>
route_type: llm/v1/chat
model:
provider: openai
name: gpt-4
options:
max_tokens: 512
temperature: 1.0
- name: ai-semantic-cache
instance_name: ai-semantic-cache-openai
enabled: true
config:
embeddings:
auth:
header_name: Authorization
header_value: Bearer <your_OPENAI_APIKEY>
model:
provider: openai
name: text-embedding-3-small
options:
upstream_url: https://api.openai.com/v1/embeddings
vectordb:
dimensions: 1536
distance_metric: cosine
strategy: redis
threshold: 0.2
redis:
host: redis-stack.redis.svc.cluster.local
port: 6379
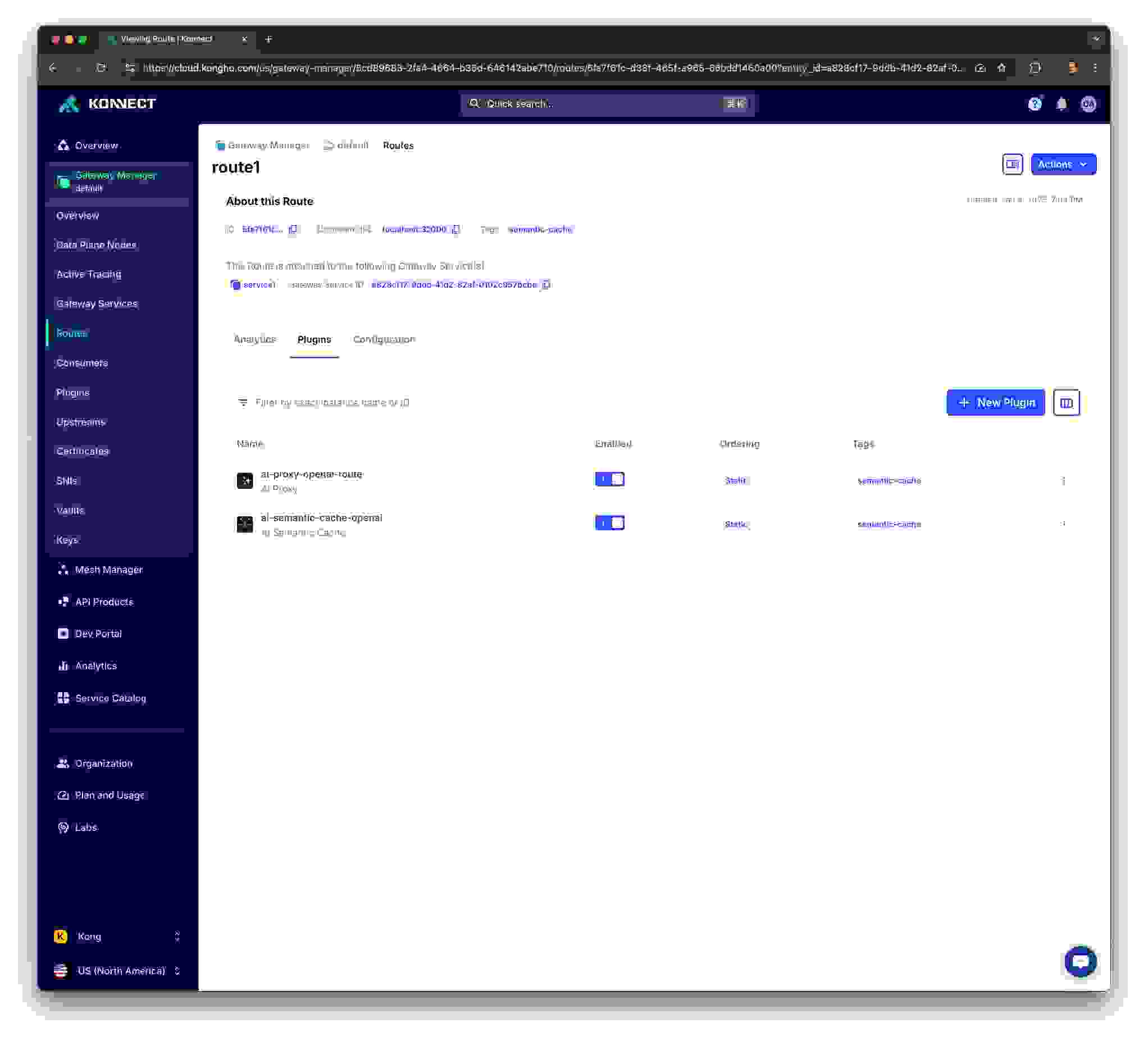
该声明在“default” Konnect 控制平面中创建了以下 Kong 对象
将 decK 声明提交到 Konnect 后,您应该可以使用 Konnect UI 查看新对象
配置好新的 Kong 对象后,Kong 数据平面将刷新并加载这些对象,然后我们就可以开始向其发送请求了。这是第一个请求,内容与我们在 Python 脚本中使用的相同
curl -i -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "Who is Joseph Conrad?"
}
]
}'
您应该会收到如下所示的响应,这意味着网关已成功将请求路由到 OpenAI,后者向我们返回了实际消息。从语义缓存和相似度的角度来看,最重要的 header 是
HTTP/1.1 200 OK
Content-Type: application/json
Connection: keep-alive
X-Cache-Status: Miss
x-ratelimit-limit-requests: 10000
CF-RAY: 8fce86cde915eae2-ORD
x-ratelimit-limit-tokens: 10000
x-ratelimit-remaining-requests: 9999
x-ratelimit-remaining-tokens: 9481
x-ratelimit-reset-requests: 8.64s
x-ratelimit-reset-tokens: 3.114s
access-control-expose-headers: X-Request-ID
x-request-id: req_29afd8838136a2f7793d6c129430b341
X-Content-Type-Options: nosniff
openai-organization: user-4qzstwunaw6d1dhwnga5bc5q
Date: Sat, 04 Jan 2025 22:05:00 GMT
alt-svc: h3=":443"; ma=86400
openai-processing-ms: 10002
openai-version: 2020-10-01
CF-Cache-Status: DYNAMIC
strict-transport-security: max-age=31536000; includeSubDomains; preload
Server: cloudflare
Content-Length: 1456
X-Kong-LLM-Model: openai/gpt-4
X-Kong-Upstream-Latency: 10097
X-Kong-Proxy-Latency: 471
Via: 1.1 kong/3.9.0.0-enterprise-edition
X-Kong-Request-Id: 36f6b41df3b74f78f586ae327af27075
{
"id": "chatcmpl-Am6YEtvUquPHdHdcI59eZC3UfOUVz",
"object": "chat.completion",
"created": 1736028290,
"model": "gpt-4-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Joseph Conrad was a Polish-British writer regarded as one of the greatest novelists to write in the English language. He was born on December 3, 1857, and died on August 3, 1924. Though he did not speak English fluently until his twenties, he was a master prose stylist who brought a non-English sensibility into English literature.\n\nConrad wrote stories and novels, many with a nautical setting, that depict trials of the human spirit in the midst of what he saw as an impassive, inscrutable universe. His notable works include \"Heart of Darkness\", \"Lord Jim\", and \"Nostromo\". Conrad's writing often presents a deep, pessimistic view of the world and deals with the theme of the clash of cultures and moral ambiguity.",
"refusal": null
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 12,
"completion_tokens": 163,
"total_tokens": 175,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"system_fingerprint": null
}
Kong Gateway 创建了一个新索引。您可以使用 redis-cli ft._list. 来检查它。索引应命名如下:idx:vss_kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4
并且 redis-cli ft.search idx:vss_kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4 “*” return 1 – 应返回 OpenAI 响应的 id。例如
1
kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4:fcdf7d8995a227392f839b4530f8d8c3055748b96275fa9558523619172fd2a8
以下 json.get 命令应返回从 OpenAI 收到的实际响应
redis-cli json.get kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4:fcdf7d8995a227392f839b4530f8d8c3055748b96275fa9558523619172fd2a8 | jq ‘.payload.choices[].message.content’
更重要的是,redis-cli monitor 命令告诉我们插件为了实现缓存而发送给 Redis 的所有命令。主要的命令包括
"FT.CREATE" "idx:vss_kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4" "ON" "JSON" "PREFIX" "1" "kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4:" "SCORE" "1.0" "SCHEMA" "$.vector" "AS" "vector" "VECTOR" "FLAT" "6" "TYPE" "FLOAT32" "DIM" "1536" "DISTANCE_METRIC" "COSINE"
"FT.SEARCH""idx:vss_kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4" "@vector:[VECTOR_RANGE $range $query_vector]=>{$YIELD_DISTANCE_AS: vector_score}" "SORTBY" "vector_score" "DIALECT" "2" "LIMIT" "0" "4" "PARAMS" "4" "query_vector" "\x981\x87<bE\xe4<b\xa3\..........\xbc" "range" "0.2"
您可以使用 Redis 控制面板检查新的索引键

如果我们发送另一个内容相似的请求,网关应该返回相同的响应,因为它会从缓存中获取,正如 X-Cache-Status: Hit header 中所指出的。此外,响应还包含与缓存相关的特定 header:X-Cache-Key 和 X-Cache-Ttl。
响应应该会更快返回,因为网关无需将请求路由到 OpenAI。
curl -i -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "Tell me more about Joseph Conrad"
}
]
}'
HTTP/1.1 200 OK
Date: Sun, 05 Jan 2025 14:28:59 GMT
Content-Type: application/json; charset=utf-8
Connection: keep-alive
X-Cache-Status: Hit
Age: 0
X-Cache-Key: kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4:fcdf7d8995a227392f839b4530f8d8c3055748b96275fa9558523619172fd2a8
X-Cache-Ttl: 288
Content-Length: 1020
X-Kong-Response-Latency: 221
Server: kong/3.9.0.0-enterprise-edition
X-Kong-Request-Id: eef1373a3a688a68f088a52f72318315
{"object":"chat.completion","system_fingerprint":null,"id":"fcdf7d8995a22…….
如果您发送另一个内容不相似的请求,插件将创建一个新的索引键。例如
curl -i -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "Living is easy with eyes closed"
}
]
}'
再次检查索引键,使用
redis-cli --scan
"kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4:fcdf7d8995a227392f839b4530f8d8c3055748b96275fa9558523619172fd2a8"
"kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4:22fbee1a1a45147167f29cc53183d0d2eef618c973e4284ad0179970209cf131"
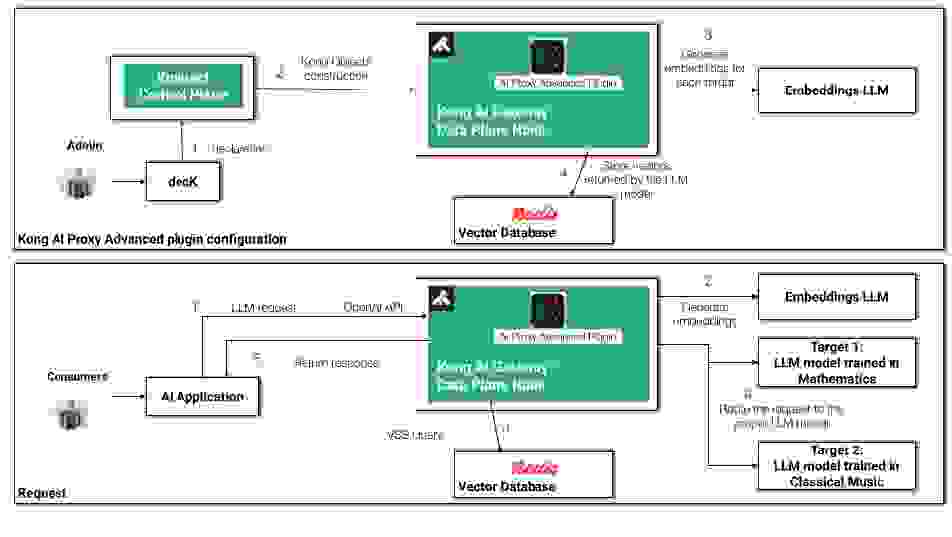
除了缓存之外,Kong AI 网关还提供了多种基于语义的功能。其中一个强大的功能是语义路由。通过此功能,我们可以让网关决定处理给定请求的最佳模型。例如,您可能有在特定主题(如数学或古典音乐)上训练过的模型,因此根据呈现的内容路由请求会很有趣。通过分析请求的内容,插件可以将其匹配到已知在类似上下文中表现更好的最合适的模型。此功能增强了模型选择的灵活性和效率,尤其是在处理各种 AI 提供商和模型时。
事实上,语义路由是高级 AI 代理插件支持的负载均衡算法之一。其他支持的算法包括
为了本文的目的,我们将探讨语义路由算法。
下图展示了高级 AI 代理插件的工作原理
这是新的 decK 声明
_format_version: "3.0"
_info:
select_tags:
- semantic-routing
_konnect:
control_plane_name: default
services:
- name: service1
host: localhost
port: 32000
routes:
- name: route1
paths:
- /openai-route
plugins:
- name: ai-proxy-advanced
instance_name: ai-proxy-openai-route
enabled: true
config:
balancer:
algorithm: semantic
embeddings:
auth:
header_name: Authorization
header_value: Bearer <your_OPENAI_APIKEY>
model:
provider: openai
name: text-embedding-3-small
options:
upstream_url: "https://api.openai.com/v1/embeddings"
vectordb:
dimensions: 1536
distance_metric: cosine
strategy: redis
threshold: 0.8
redis:
host: redis-stack.redis.svc.cluster.local
port: 6379
targets:
- model:
provider: openai
name: gpt-4
route_type: "llm/v1/chat"
auth:
header_name: Authorization
header_value: Bearer <your_OPENAI_APIKEY>
description: "mathematics, algebra, calculus, trigonometry"
- model:
provider: openai
name: gpt-4o-mini
route_type: "llm/v1/chat"
auth:
header_name: Authorization
header_value: Bearer <your_OPENAI_APIKEY>
description: "piano, orchestra, liszt, classical music"
主要配置部分包括
如您所见,为了方便起见,配置使用 OpenAI 的模型作为嵌入和目标。此外,仅用于本次探索,我们还将使用 OpenAI 的 gpt-4 和 gpt-4o-mini 模型作为目标。
将 decK 声明提交到 Konnect 控制平面后,Redis 向量数据库应该会定义一个新的索引,并为每个目标创建一个键。然后我们就可以开始向网关发送请求了。前两个请求的内容与古典音乐相关,因此响应应该来自相关的模型 gpt-4o-mini-2024-07-18。
% curl -s -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "Who wrote the Hungarian Rhapsodies piano pieces?"
}
]
}' | jq '.model'
"gpt-4o-mini-2024-07-18"
% curl -s -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "Tell me a contemporary pianist of Chopin"
}
]
}' | jq '.model'
"gpt-4o-mini-2024-07-18"
现在,下一个请求与数学相关,因此响应来自另一个模型,
"gpt-4-0613".
% curl -s -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{
"messages": [
{
"role": "user",
"content": "Tell me about Fermat''s last theorem"
}
]
}' | jq '.model'
"gpt-4-0613"
历史上,Kong 一直支持 Redis 来实现各种关键策略和用例。最近由 Kong AI 网关实现的合作,侧重于语义处理,其中 Redis 的向量相似性搜索能力发挥着重要作用。
这篇博文探讨了两个主要的基于语义的用例:语义缓存和语义路由。请查阅 Kong 和 Redis 的文档页面,以了解更多关于使用这两种技术可以实现的广泛的 API 和 AI 网关用例。

