 Redis 8 来了——它是开源的
Redis 8 来了——它是开源的
了解更多

从一开始,Redis 就是单线程的。这是 Redis 应用,以及最近出现的 Redis 模块(例如 RediSearch)必须面对的现实。
虽然保持单线程使得 Redis 简单且快速,但缺点是长时间运行的命令会阻塞整个服务器,直到查询执行完毕。大多数 Redis 命令都很快,这不是问题,但像 ZUNIONSTORE、LRANGE、SINTER 以及臭名昭著的 KEYS 等命令,可能会根据它们处理的数据大小,阻塞 Redis 几秒甚至几分钟。
RediSearch 是在 Redis 中编写的一个新的搜索引擎模块。它利用 Redis 强大的基础设施和高效的数据结构,创建了一个快速且功能丰富、实时的搜索引擎。
虽然它极快且使用高度优化的数据结构和算法,但它面临并发挑战。根据数据集的大小和搜索查询的基数,它们可能需要几微秒到几百毫秒,在极端情况下甚至几秒钟。一旦发生这种情况,引擎运行所在的整个 Redis 服务器都会被阻塞。
举个例子,考虑一个全文本查询,它交叉包含“hello”和“world”两个词条,每个词条有一百万个条目,共有五十万个共同的交叉点。要在毫秒内完成此操作,您必须在一纳秒内扫描、交叉和排名每个结果,这在当前的硬件下是不可能的。索引一个包含1000个词的文档时也是如此。它会完全阻塞 Redis 整个索引期间。
因此,搜索查询的行为可能与您平均的 Redis O(1) 命令非常不同,它们可能会长时间阻塞整个服务器。当然,您可以而且应该将您的搜索索引拆分成一个集群,并且 RediSearch 的集群版本很快将作为 Redis Enterprise 的一部分提供——但即使我们将数据分布在集群节点上,某些查询仍然可能会很慢。
幸好,在 Redis 4.0 即将发布以及模块 API 发布之际,Salvatore Sanfilippo 加入了一项革命性的改变:线程安全上下文和全局锁。
想法很简单。虽然 Redis 仍然是单线程的,但一个模块可以运行多个线程。任何一个线程在需要访问 Redis 数据时,都可以获取全局锁,对其进行操作,然后释放它。
我们仍然无法真正并行查询 Redis。只有一个线程可以获取锁,包括 Redis 主线程,但我们可以通过不时地让出这个锁来确保长时间运行的查询能够给其他查询时间正常运行(这个限制仅适用于此特定用例——在其他用例中,例如训练机器学习模型,实际的后台并行处理是可以实现且容易的)。
到目前为止,搜索查询的流程很简单:查询到达 Redis 模块中的一个命令处理程序回调函数,它将是 Redis 内部唯一运行的东西。然后它会解析查询、执行查询,耗时多久就多久,并返回结果。
为了实现并发,我们采用了以下设计
因此,操作系统的调度程序确保所有查询线程都能获得 CPU 时间来运行。当一个线程运行时,其余线程空闲等待,但由于执行每秒让出约 5000 次,这产生了并发的效果。快速查询将一次性完成而无需让出执行,慢速查询需要多次迭代才能完成,但会允许其他查询并发运行。
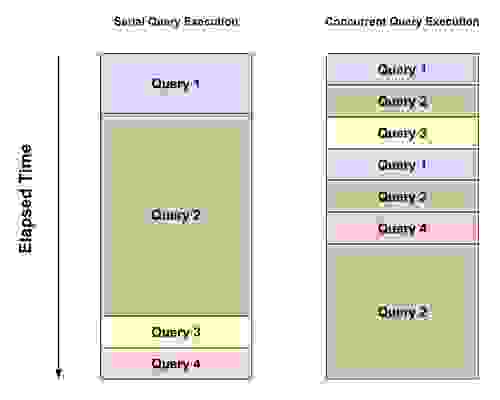
同样的方法也适用于索引。如果一个文档太大,对其进行分词和索引会长时间阻塞 Redis——我们会将其分解成许多更小的迭代,并允许 Redis 执行其他任务,而不是长时间阻塞。事实上,在索引的情况下,有足够的工作可以利用多核并行完成,即对文档进行分词和规范化。这对于非常大的文档特别有效。
顺带一提,这也可以通过单个线程在所有查询执行循环之间切换来实现,但这需要进行更大的代码重构,并且在合理负载下的效果仍然相似,所以我们选择将其留待未来版本。
虽然这并非魔法,如果您的所有查询都很慢,它们仍然会很慢,这里也没有进行真正的并行处理——但这在 Redis 方面是革命性的。想想在繁忙的 Redis 实例中运行 KEYS * 的老问题。在单线程操作中,这会导致实例挂起几秒甚至几分钟。现在可以在模块中实现一个并发版本的 KEYS,它几乎不会影响性能。事实上,Salvatore 已经实现了一个!
然而,也存在负面影响:我们为了并发,在一定程度上牺牲了读写的原子性。考虑以下情况:一个线程正在处理一个应该检索文档 A 的查询,然后让出执行上下文;与此同时,另一个线程删除了或更改了文档 A。结果是——第一个线程运行的查询将无法检索该文档,因为它在该线程“休眠”期间已经被更改或删除。
这当然只与高更新/删除负载以及相对缓慢和复杂的查询有关。在我们看来,对于大多数用例来说,这种牺牲是值得的,而且通常查询处理速度足够快,发生这种情况的可能性非常低。
然而,如果需要,这可以很容易地克服:如果操作的强原子性很重要,可以将 RediSearch 配置为在“安全模式”下运行,使所有搜索和更新具有原子性,从而确保每个查询都引用其调用时刻索引的状态。
要在加载时启用安全模式并禁用查询并发,可以配置 RediSearch:在命令行中使用 redis-server --loadmodule redisearch.so SAFEMODE 或者将 loadmodule redisearch.so SAFEMODE 添加到您的 redis.conf 中——具体取决于您加载模块的方式。
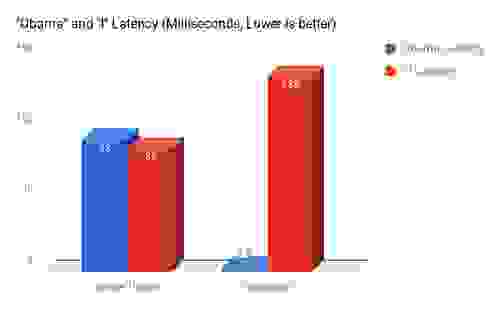
我在相同的设置下,对模块的两个版本——简单的单线程版本和并发多线程版本——进行了基准测试。
1. 数据集包含大约 1,000,000 条 Reddit 评论。
2. 运行了两个使用 Redis 基准测试的客户端——首先是单独运行,然后并行运行
3. 一个客户端执行了一个非常耗时的查询——“i”,它有 200,000 个结果,并使用了 5 个并发连接。
4. 一个客户端执行了一个非常轻量的查询——“Obama”,它有大约 500 个结果,并使用了 10 个并发连接(我们假设在正常情况下,轻量级查询会比重量级查询多)。
5. 客户端和服务器都在我的个人笔记本电脑上运行——配备 Intel Quad Core i7 @ 2.2Ghz 的 MacBook Pro。

这个小小的全局锁功能和线程安全上下文,也许是模块 API 提供的最强大的功能。我们在这里只触及了并发问题,但它也支持后台任务、对不接触 Redis 键空间的数据进行真正的并行处理等等。
对于 RediSearch 来说,它使其从一个适用于小型用例的不错引擎,转变为一个能够在高负载下处理海量数据集的真正强大引擎。结合即将推出的 RediSearch 分布式版本(它也利用了线程 API,但这又是另一篇文章的故事了),这将使 RediSearch 成为一个非常强大的搜索和索引引擎。

