 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多

 您可能会发现自己想知道是否应该在代码中使用更多的概率数据结构。 答案一如既往,取决于情况。 如果您的数据集相对较小,并且您有可用的必要内存,那么在索引中保留数据的另一个副本可能是有意义的。 您将保持 100% 的准确性并获得快速的执行时间。
您可能会发现自己想知道是否应该在代码中使用更多的概率数据结构。 答案一如既往,取决于情况。 如果您的数据集相对较小,并且您有可用的必要内存,那么在索引中保留数据的另一个副本可能是有意义的。 您将保持 100% 的准确性并获得快速的执行时间。
但是,当数据集变得很大时,您当前的解决方案很快就会变成一个缓慢的内存占用,因为它存储了项目或项目标识符的附加副本。 因此,当您处理大量项目时,您可能需要放宽 100% 准确性的要求,以便提高速度并节省内存空间。 在这些情况下,使用适当的 概率数据结构 可以发挥神奇的作用 – 支持高精度、预定义的内存分配和与数据集大小无关的时间复杂度。
在数据集或流中查找最大的 K 个元素(又名关键字频率)是许多现代应用程序的常见功能要求。 这通常是一项关键任务,用于跟踪网络流量以用于营销或网络安全目的,或者用作 游戏排行榜 或简单的单词计数器。 我们在 概率特征 中实现的最新 Top-K 使用了一种名为 HeavyKeeper1 的算法,该算法由一组研究人员提出。 他们放弃了先前算法(例如 Space-Saving 或不同的 Count Sketches)使用的常见count-all 或admit-all-count-some 策略。 相反,他们选择了count-with-exponential-decay 策略。 指数衰减 的设计偏向于鼠标(小)流,并且对大象(大)流的影响有限。 这确保了比以前的概率算法允许的更高的精度和更短的执行时间,同时将内存利用率保持在 Sorted Set 通常需要的内存的一小部分。
使用此 Top-K 概率数据结构的另一个好处是,每当元素进入或退出您的 Top-K 列表时,您都会收到实时通知。 如果元素添加命令进入列表,则将返回删除的元素。 然后,您可以使用此信息来帮助防止 DoS 攻击、与顶级玩家互动或发现书中写作风格的变化。
在 Probabilistic 中初始化 Top-K 键需要四个参数
根据经验,k*log(k) 的宽度、log(k) 或最小值为 5 的深度以及 0.9 的衰减会产生良好的结果。 您可以运行一些测试来微调这些参数以适应您的数据性质。
Redis 的 Sorted Set 数据结构提供了一种简单而流行的方式来维护一个简单、准确的排行榜2。 使用这种方法,您可以通过调用 ZINCRBY 来更新成员的分数,并通过调用 ZREVRANGE 来检索具有所需范围的列表。 另一方面,Top-K 使用 TOPK.RESERVE 命令进行初始化。 调用 TOPK.ADD 将更新计数器,如果您的 Top-K 列表已更改,则将返回删除的项目。 最后,正如您所期望的,TOPK.LIST 返回当前的 K 个项目列表。 为了比较这两个选项,我们使用排行榜用例运行了一个简单的基准测试。
在这个基准测试中,我们提取了 战争与和平 一书中,最常见的单词列表,其中包含超过 500,000 个单词。 为了完成这项任务,Redis Sorted Set 花费了不到 6 秒的时间,并且需要近 4MB 的 RAM,并保证 100% 的准确性。 相比之下,Top-K 平均花费四分之一的时间和一小部分内存,尤其是对于较低的 K 值。 在大多数情况下,其准确率为 100%,除了非常高的 K 值,其中“仅”实现了 99.9% 的准确率3。
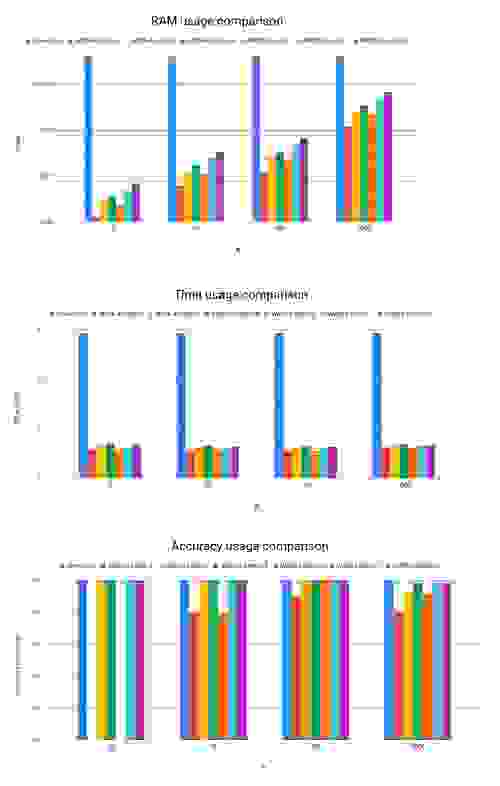
从上面的结果中得出的一些有趣的结论包括
重要的是要注意,不同类型的数据可能对不同的变量敏感。 在我的实验中,某些数据集的执行时间对“K”更敏感。 在其他情况下,对于相同的宽度和深度值,较低的衰减值会产生更高的精度。
Probabilistic 中新的 Top-K 概率数据结构快速、精简且非常准确。 对于任何具有流或增长的数据集且内存使用要求较低的项目,请考虑使用它。 就个人而言,这是我在 Redis 的第一个项目,我很幸运有机会从事如此独特的算法。 我对结果感到非常满意!
如果您有想讨论的用例,或者只是想分享一些想法,请随时 给我发送电子邮件。
[1] HeavyKeeper:由联合主要作者 Junzhi Gong 和 Tong Yang 编写的用于查找 Top-K Elephant Flows 的准确算法。
[2] 改变游戏规则的 3 大 Redis 用例。
[3] 图中的较低结果未遵循宽度和深度的指导方针。

