 Redis 8 来了——而且它是开源的
Redis 8 来了——而且它是开源的
了解更多

今天,我们很高兴地宣布 RedisGraph v1.0 正式发布 (GA)。RedisGraph 是一个由 Redis 开发的 Redis 模块,用于为 Redis 添加图数据库功能。我们在六个月前发布了 RedisGraph 的预览/测试版,并感谢社区和客户在我们共同开发第一个 GA 版本期间提供的所有宝贵反馈和建议。
与现有图数据库实现不同,RedisGraph 将连接的数据表示为邻接矩阵,而不是每个数据点的邻接列表。通过将数据表示为稀疏矩阵并利用GraphBLAS(一个高度优化的稀疏矩阵操作库)的力量,RedisGraph 提供了一种快速高效的方式来存储、管理和处理图。事实上,我们初步的基准测试已经发现 RedisGraph 比现有图数据库快六到 600 倍!下面,我将分享我们如何对 RedisGraph v1.0 进行基准测试,但如果您想了解更多关于我们如何使用稀疏矩阵的信息,可以先查看这些链接
在进入我们的基准测试之前,我应该指出 Redis 默认是一个单线程进程。在 RedisGraph 1.0 中,我们没有发布将图数据分区到多个分片上的功能,因为将所有数据放在单个分片中有助于执行更快的查询,同时避免分片之间的网络开销。RedisGraph 绑定到 Redis 的单线程以支持所有传入的查询,并包含一个线程池,该线程池在模块加载时获取可配置数量的线程来处理更高的吞吐量。每个图查询都由 Redis 主线程接收,但在线程池的一个线程中进行计算。这使得读取操作可以轻松扩展并处理大吞吐量。在任何给定时刻,每个查询只在一个线程中运行。
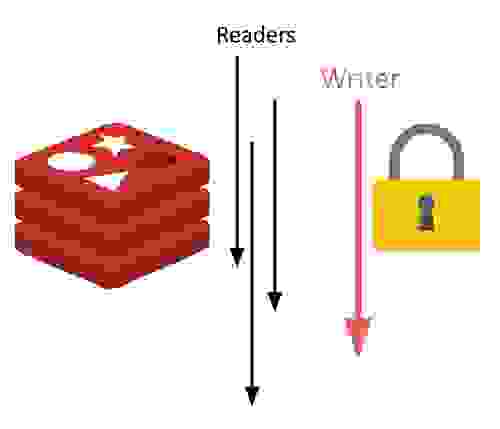
这与其他图数据库实现不同,后者通常在机器的所有可用核心上执行每个查询。我们认为我们的方法更适合实时真实世界的用例,在这些用例中,高吞吐量和并发操作下的低延迟比一次处理一个序列化请求更重要。
虽然 RedisGraph 可以并发执行多个读取查询,但任何修改图的写入查询(例如引入新节点或创建关系和更新属性)都必须完全隔离执行。RedisGraph 通过使用读/写 (R/W) 锁来强制实现写/读分离,这样多个读取者可以获取锁,或者只有一个写入者可以获取锁。只要写入者正在执行,任何人都无法获取锁;只要有读取者正在执行,写入者就无法获取锁。
现在我们已经介绍了重要的背景信息,下面来详细介绍我们最新的基准测试。在图数据库领域,有多种基准测试工具可用。最全面的工具是LDBC graphalytics,但对于本次发布,我们选择了 TigerGraph 在 2018 年 9 月发布的更简单的基准测试。该测试评估了 TigerGraph、Neo4J、Amazon Neptune、JanusGraph 和 ArangoDB 等领先的图数据库,并发布了所有查询在所有平台上的平均执行时间和总运行时间。TigerGraph 基准测试涵盖以下方面
TigerGraph 的基准测试报告称,TigerGraph 比其他任何图数据库快 2 到 8000 倍,因此我们决定挑战这个(文档齐全的)实验,并使用完全相同的设置来比较 RedisGraph。由于 TigerGraph 已经比较了所有其他图数据库,我们使用了他们基准测试发布的结果,而不是重复这些测试。
考虑到 RedisGraph 是 v1.0 版本,我们计划在未来的版本中添加更多特性和功能,因此在当前的基准测试中,我们主要关注 k 跳邻居计数查询。当然,我们将在不久的将来发布其他查询的结果。
| 云实例类型 | vCPU | 内存 (GiB) | 网络 | SSD |
|---|---|---|---|---|
| AWS r4.8xlarge | 32 | 244 | 10 千兆 | 仅 EBS |
| 名称 | 描述和来源 | 顶点数 | 边数 |
|---|---|---|---|
| graph500 | 合成 Kronecker 图 http://graph500.org |
240 万 | 6400 万 |
| Twitter 用户关注有向图 http://an.kaist.ac.kr/traces/WWW2010.html | 4160 万 | 14.7 亿 |
k 跳邻居查询是一种局部图查询。它计算单个起始节点(种子节点)在特定深度连接到的节点数量,且仅计算距离为 k 跳的节点。
以下是 Cypher 代码
MATCH (n:Node)-[*$k]->(m) where n.id=$root return count(m)
这里,$root 是我们开始探索图的种子节点的 ID,$k 代表我们计算邻居的深度。为了加快执行速度,我们在根节点 ID 上使用了索引。
虽然我们采用了与 TigerGraph 完全相同的基准测试,但令人惊讶的是,他们只比较了单个请求的查询响应时间。该基准测试未能测试并发并行负载下的吞吐量和延迟,这几乎是所有实时真实世界场景的代表性指标。正如我之前提到的,RedisGraph 从头开始构建,以实现极高的并行性,每个查询由单个线程处理,该线程利用 GraphBLAS 库进行线性代数矩阵运算。RedisGraph 可以增加线程并以接近线性的方式扩展吞吐量。
为了测试这些并发操作的影响,我们在 TigerGraph 基准测试中添加了并行请求。尽管 RedisGraph 仅利用了单个核心,而其他图数据库使用了多达 32 个核心,但 RedisGraph 的响应时间比其他任何图数据库都更快(有时甚至快得多)(Twitter 数据集上的单个请求 k 跳查询测试中 TigerGraph 除外)。
单请求基准测试基于一跳和两跳查询的 300 个种子节点,以及三跳和六跳查询的 10 个种子节点。这些种子节点在所有图数据库上按顺序执行。`time (msec)` 行表示给定数据集下每个数据库所有种子节点的平均响应时间。每数据集的“normalized”行表示将这些平均响应时间相对于 RedisGraph 进行归一化后的结果。
需要注意的是,TigerGraph 对所有数据库上的所有请求应用了超时限制:一跳和两跳查询为三分钟,三跳和六跳查询为 2.5 小时(有关每个数据库有多少请求超时,请参阅TigerGraph 的基准测试报告)。如果给定数据集和给定数据库的所有请求都超时,我们将结果标记为“N/A”。当显示平均时间时,这仅适用于成功执行的请求(种子节点),意味着查询没有超时或产生内存不足异常。这有时会扭曲结果,因为某些数据库无法响应更困难的查询,从而导致平均单请求时间看起来更好,给人一种对数据库性能的错误印象。在所有测试中,RedisGraph 从未超时或产生内存不足异常。
| 数据集 | 衡量指标 | RedisGraph | TigerGraph | Neo4j | Neptune | JanusGraph | ArangoDB |
|---|---|---|---|---|---|---|---|
| graph500 | 时间 (毫秒) | 0.39 | 6.3 | 21.0 | 13.5 | 27.2 | 91.9 |
| 归一化 | 1 | 16.2 | 53.8 | 34.6 | 69.7 | 235.6 | |
| 时间 (毫秒) | 0.8 | 24.1 | 205.0 | 289.2 | 394.8 | 1,674.7 | |
| 归一化 | 1 | 30.1 | 256.3 | 361.5 | 493.5 | 2,093.4 |
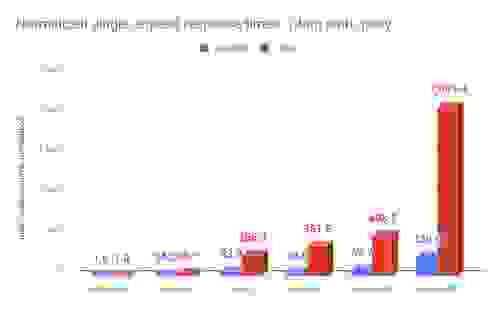
| 数据集 | 衡量指标 | RedisGraph | TigerGraph | Neo4j | Neptune1 | JanusGraph | ArangoDB2 |
|---|---|---|---|---|---|---|---|
| graph500 | 时间 (毫秒) | 30.7 | 71 | 4,180.0 | 8,250.0 | 24,050.0 | 16,650.0 |
| 归一化 | 1 | 2.3 | 136.2 | 268.7 | 783.4 | 542.3 | |
| 时间 (毫秒) | 503.0 | 460.0 | 18,340.0 | 27,400.0 | 27,780.0 | 28,980.0 | |
| 归一化 | 1 | 0.9 | 36.5 | 54.5 | 55.2 | 57.6 |
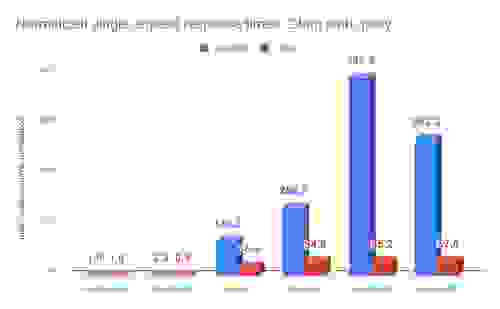
| 数据集 | 衡量指标 | RedisGraph | TigerGraph | Neo4j | Neptune1 | JanusGraph | ArangoDB*2 |
| graph500 | 时间 (毫秒) | 229 | 410 | 51,380.0 | 2,270.0 | 1,846,710.0 | 3,461,340.0 |
| 归一化 | 1 | 1.8 | 224.4 | 9.9 | 8,064.2 | 15,115.0 | |
| 时间 (毫秒) | 9301 | 6730 | 298,000.0 | 38,700.0 | 4,324,000.0 | 3,901,600.0 | |
| 归一化 | 1 | 0.7 | 32.0 | 4.2 | 464.9 | 419.5 |

| 数据集 | 衡量指标 | RedisGraph | TigerGraph | Neo4j | Neptune1 | JanusGraph | ArangoDB2 |
|---|---|---|---|---|---|---|---|
| graph500 | 时间 (毫秒) | 1614 | 1780 | 1,312,700.0 | N/A | N/A | N/A |
| 归一化 | 1 | 1.1 | 813.3 | N/A | N/A | N/A | |
| 时间 (毫秒) | 78730 | 63000 | N/A | N/A | N/A | N/A | |
| 归一化 | 1 | 0.8 | N/A | N/A | N/A | N/A |
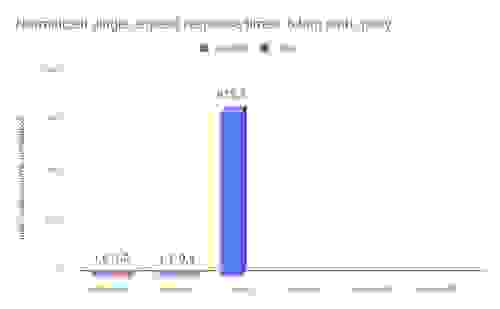
对于并行请求测试,我们仅比较了 RedisGraph 和 TigerGraph。此设置包括在同一测试机器上运行的 22 个客户端线程,共生成 300 个请求。以下结果显示了每个图数据库在每个深度(一跳、两跳、三跳和六跳)响应所有请求的总耗时(毫秒)。
对于 TigerGraph,我们通过将单请求平均响应时间乘以 300 来推断出每个深度的结果。我们认为这是最好的情况,因为 TigerGraph 在处理单个请求时已经完全利用了所有 32 个核心。下次,我们将在 22 个客户端的相同负载下重复这些测试,我们预计(考虑到并行性定律以及执行并行请求将产生的开销)我们的结果会更好。
| 一跳 | 两跳 | 三跳 | 六跳 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 数据集 | 衡量指标 | RedisGraph | TigerGraph | RedisGraph | TigerGraph | RedisGraph | TigerGraph | RedisGraph | TigerGraph |
| graph500 | 时间 (毫秒) | 29 | 1,890 | 772 | 21,000 | 5,554 | 123,000 | 24,388 | 534,000 |
| 归一化 | 1 | 65.2 | 1 | 27.2 | 1 | 22.1 | 1 | 21.9 | |
| 时间 (毫秒) | 117 | 7,200 | 12,923 | 138,000 | 286,018 | 2,019,000 | 3,117,964 | 18,900,000 | |
| 归一化 | 1 | 61.5 | 1 | 10.7 | 1 | 7.1 | 1 | 6.1 | |
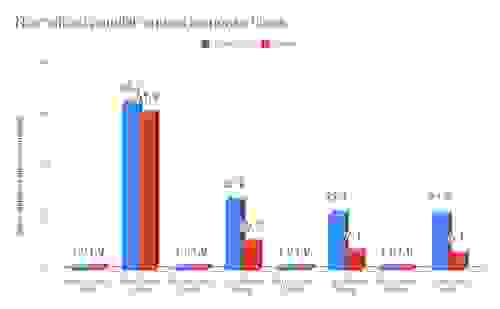
我们对 v1.0 GA 版本取得的这些初步基准测试结果感到非常自豪。RedisGraph 是由 Roi Lipman(我们自己的图专家)在 Redis 的一次黑客马拉松期间,仅仅两年前开始的。最初,该模块使用了 hexastore 实现,但随着时间的推移,我们看到了稀疏矩阵方法和 GraphBlas 使用的巨大潜力。现在我们正式验证了这一决定,RedisGraph 已经成熟为一个稳固的图数据库,在大数据集 (twitter) 上负载下的性能比现有图解决方案快 6 到 60 倍,在普通数据集 (graph500) 上快 20 到 65 倍。
最重要的是,RedisGraph 在单请求响应时间方面超越了 Neo4j、Neptune、JanusGraph 和 ArangoDB,速度提升了 36 到 15000 倍。与 TigerGraph 相比,我们在单请求响应时间上快了 2 倍和 0.8 倍,TigerGraph 使用全部 32 个核心处理单个请求,而 RedisGraph 仅使用单个核心。同样重要的是要注意,我们的大数据集上的查询都没有超时,也没有产生内存不足异常。
在这些测试期间,我们的工程师还对 RedisGraph 进行了性能分析,发现了一些容易实现的改进,这将使我们的性能进一步提升。此外,我们即将推出的路线图包括
图处理愉快!
RedisGraph 团队
2019 年 1 月 17 日
在我们发布这些 RedisGraph 基准测试结果后,TigerGraph 的人发表了一些看法。虽然我们感谢听到竞争对手的观点,但我们想回应他们关于假新闻的指控。在此阅读我们的基准测试更新博客。

