 Redis 8 发布了——它是开源的
Redis 8 发布了——它是开源的

视频

RedisConf 2021 的九大要点
了解更多


投资组合是财富和资产管理行业的基础。自从 Harry Makowitz 开创了现代投资组合理论以来,资产和财富管理专业人士就一直致力于在给定风险水平下最大化投资组合的回报。如今,该行业的专业人士迎来了数百万散户投资者,他们永远改变了投资格局。这些新入局者对零售经纪商、交易所和清算所的交易基础设施基础技术产生了巨大影响。
以 2021 年 1 月的 GameStop 股票狂热为例。散户投资者开始以创纪录的水平交易 GameStop 股票。这些投资者还涌入 AMC Entertainment 等其他“表情包股票”,导致整个市场波动率在短短几个交易日内飙升超过 76%(根据 VIX 衡量)。这种波动导致数千种证券面临价格压力。数百万投资者同时疯狂地试图访问他们的投资组合,但却遇到了无法跟上需求的应用程序。当投资者最需要应用程序表现良好时,他们不会善待那些表现不佳的公司。
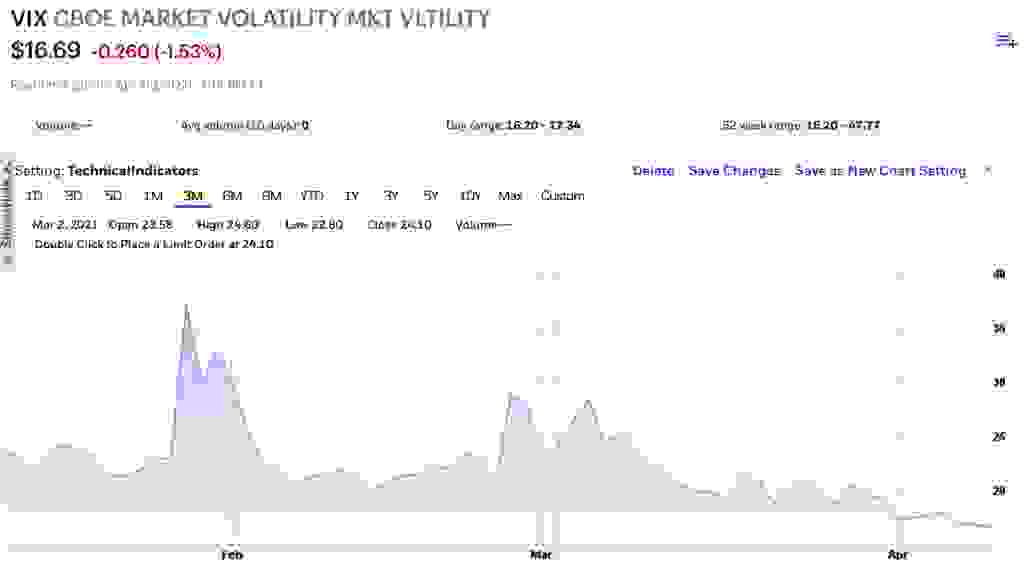
在这些疯狂时期,大多数投资者需要随时访问其投资组合的两个数据点
这些问题的答案可以引导投资者买入、卖出或持有特定证券。在当今快速变化的市场中,任何延迟都可能意味着机会和利润的损失。你需要实时访问价格来回答这些问题——然而,这里有两个主要挑战
证券价格会根据交易量、特定证券的波动性以及市场波动性快速变化。另一方面,一家经纪商可能拥有数百万客户,每位客户的投资组合中都有几十种证券。客户登录后,他们的投资组合需要立即更新到最新价格,并在经纪商收到交易所价格时保持更新。
本质上,我们正在创建一个实时股票图表。许多经纪商应用程序并未尝试大规模实现此功能。相反,这些应用程序会拉取最新价格,而不是将价格推送到数百万客户端。例如,他们的投资组合页面上可能有一个刷新按钮。
这些下一代挑战并非微不足道,也无法通过基于磁盘的数据库轻松解决,因为它们并非为每秒处理数百万次操作而设计。金融行业的需求需要一种能够轻松扩展并每秒处理数亿次操作的数据库。Redis Enterprise 内存数据库平台应运而生,它有潜力解决这些诸多挑战。

这是关于金融领域各种实时用例的系列博客的第一篇。我们将介绍每个用例的细节和业务挑战,以及 Redis Enterprise 在解决这些挑战中可以发挥的作用。作为博客的一部分,我们提供示例设计、数据模型和代码示例。我们还将讨论每种方法的优缺点。
在本篇博客文章中,我们将介绍以下内容
客户端应用程序检索到投资组合并接收到最新价格后,它可以
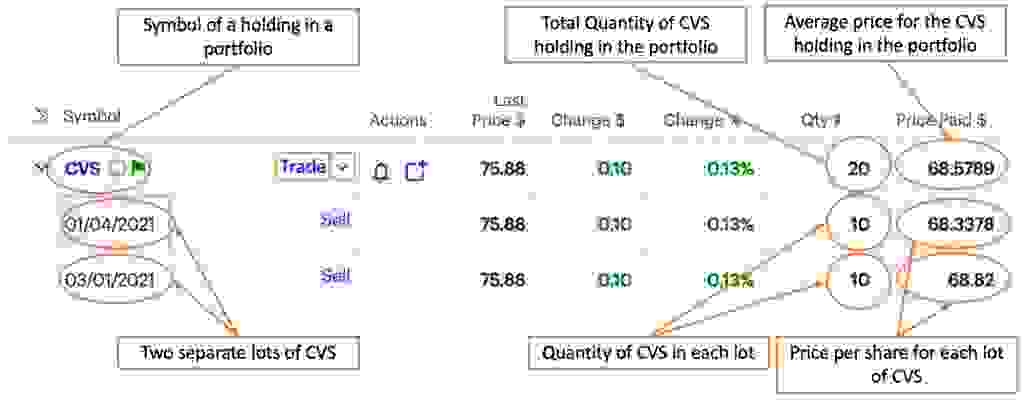
我们先来对投资组合中的一项持有进行建模。在下图中,CVS Health Corp. (NYSE: CVS) 是我们的一个示例持有。CVS 有两个独立的批次——第一个于 2021 年 1 月 4 日购买,第二个于 2021 年 3 月 1 日购买。每个批次的买入交易中购买了相同数量的股票。两次交易都是 10 股,但在不同的每股价格下——第一个批次为 68.3378 美元,第二个批次为 68.82 美元。投资组合中 CVS 持有的总数量为 20 股,平均成本计算如下:((68.3378 * 10) + (68.82 * 10))/20 = 每股 68.5789 美元。
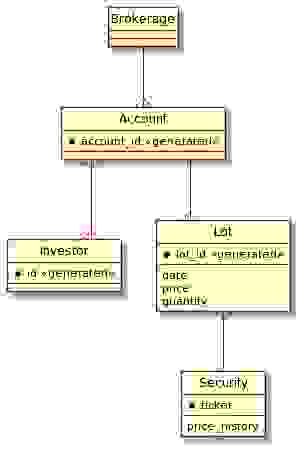
Redis 的数据表示是扁平的——例如,不能将 Set 嵌入到另一个 Set 中。因此,ER 图描述的数据模型不一定能直接实现。直接实现实体模型可能达不到期望的性能特性,所以当你进行实现时,需要换一种思路。本节介绍使用 Redis 设计高性能和可扩展实现所需的一些基本设计原则。
此处的数据模型提到了以下实体
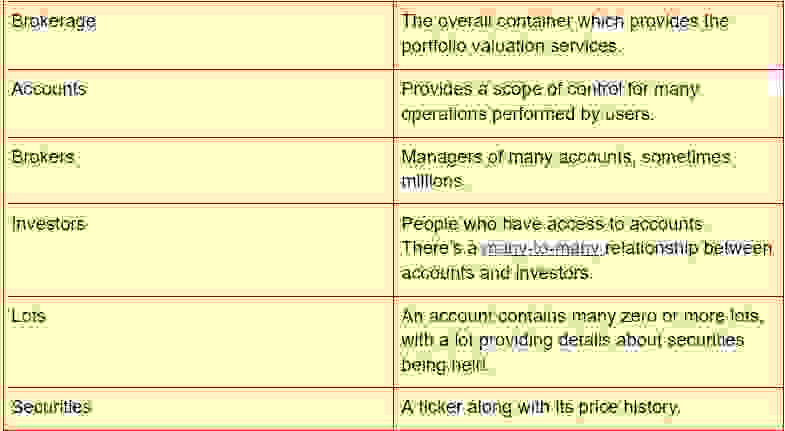
ER 图提供了一种可视化表示,可以帮助人们了解情况。
上图缺失了传入价格的集合,尽管它们记录在证券的价格历史中——以及价格变化时瞬时价值和收益的计算。因此,ER 图表示了用于执行投资组合估值的相对静态的数据上下文。
关于此系统需要考虑的关键点包括
鉴于这些要点,一些通用方法包括
以下是主要的计算组件和数据流
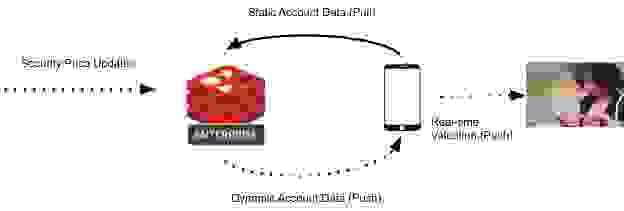
请注意,Redis Enterprise 由跨多台机器的一个或多个节点组成——可部署在本地、Kubernetes、混合云、托管服务或原生第一方云服务上——并且会有数十万投资者使用他们选择的客户端在线。
证券价格更新将由 Redis Streams 吸收。证券更新将在此流中混合在一起,需要进行分解才能使数据有用。将使用消费者组来执行分解,并将数据处理成每种证券的两种结构
下图详细说明了架构的这一部分
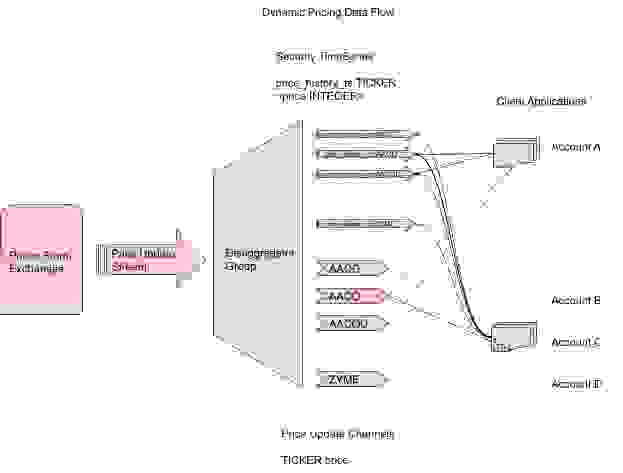
我们模型中最重要的因素是代表批次和相关证券的账户特定数据。我们将比较两种实现,作为如何在 Redis 中建模数据的示例,重点关注性能。还有其他实现方式——我们的目标是介绍在 Redis 中实现数据的整体设计原则和思考过程。
我们将使用以下信息作为具体示例

我们使用最低可能的货币面额进行定价,以避免浮点数并将所有内容保持为整数。我们可以允许客户端处理转换为美元和美分。在此示例中,我们使用精确到小数点后两位的价格。
我们的第一个实现使用一个 SET 记录账户中所有批次的 ID,该 SET 由账户 ID 标识,然后每个批次(由批次 ID 标识)使用一个 Redis HASH,其中股票代码、数量和购买价格作为字段。换句话说,我们使用 HASH 来建模批次实体结构,批次实体的每个属性都是 Redis HASH 中的一个字段。
使用此数据模型,我们为每个账户设置一个键,其值包含该账户的所有批次 ID,并存储为 Redis SET
批次ID:<账户_ID> SET <批次ID>
此外,对于每个批次 ID,我们都会有一个 HASH,其字段为股票代码、数量和购买价格
批次:<批次ID> HASH <股票代码 TICKER> <数量 INTEGER> <价格 INTEGER>
具体来说,我们将创建这样的键
127.0.0.1:6379> SADD lotids:ACC-1001 LOT-9001 LOT-9002 (integer) 2 127.0.0.1:6379> HMSET lot:LOT-9001 ticker AAPL quantity 200 price 12556 OK 127.0.0.1:6379> HMSET lot:LOT-9002 ticker CAT quantity 1200 price 18063 OK
RedisTimeSeries 模块支持存储和检索相关的时间值对,以及高吞吐量的插入和低延迟的读取。我们将获取客户端在使用相应时间序列键时访问的感兴趣的股票代码的最新价格
价格历史:<股票代码> TIMESERIES <价格 INTEGER>
127.0.0.1:6379> TS.GET price_history:APPL 1) (integer) 1619456853061 2) 12572 127.0.0.1:6379> TS.GET price_history:CAT 1) (integer) 1619456854120 2) 18021
并订阅价格频道以获取更新
<股票代码> 订阅频道
为了获取所有数据,客户端将执行以下操作
总时间复杂度为 O(N +T)。
具体来说,操作一和操作二将是
127.0.0.1:6379> SMEMBERS lotids:ACC1001 1) "LOT-9001" 2) "LOT-9002" 127.0.0.1:6379> HGETALL lot:LOT-9001 1) "ticker" 2) "AAPL" 3) "quantity" 4) "200" 5) "price" 6) "12556" 127.0.0.1:6379> HGETALL lot:LOT-9002 1) "ticker" 2) "CAT" 3) "quantity" 4) "1200" 5) "price" 6) "18063"
我们可以通过使用管线化 (pipelining)(一种客户端批处理形式)和/或重复使用 LUA 脚本(使用SCRIPT LOAD 和 EVALSHA)来最小化网络延迟。附注: 事务 (Transactions) 可以使用管线实现并减少网络延迟,但这取决于客户端,且其目标是服务器上的原子性,因此它们并不能真正解决网络延迟问题。管线包含输入和输出必须相互独立的命令。LUA 脚本要求提前提供所有键,并且所有键都必须散列到同一槽 (slot) 中(有关更多详细信息,请参阅Redis Enterprise 文档中关于此主题的部分)。
鉴于这些约束,我们可以看到操作到管线的分配如下
并且无法使用 LUA 脚本,因为每个操作使用不同的键,并且这些键没有可以散列到同一槽的共同部分。
使用此模型,我们的时间复杂度为 O(N+T),并有三次网络跳跃。
另一种模型是扁平化批次实体结构,并使用由账户 ID 标识的键来表示每个实体属性——批次的每个属性(数量、股票代码、价格)对应一个这样的键。每个 HASH 中的字段将是批次 ID 和对应的数量、股票代码或价格的值。因此,我们将拥有以下键
按批次区分的股票代码: <账户_ID> HASH <批次ID 股票代码>
按批次区分的数量:<账户_ID> HASH <批次ID INTEGER>
按批次区分的价格:<账户_ID> HASH <批次ID INTEGER>
这些哈希键将替换数据模型 A 中的批次 ID 和批次键,而 价格历史 和 <股票代码> 键将保持不变。
创建键
HSET tickers_by_lot:ACC-1001 LOT-9001 AAPL LOT-9002 CAT HSET quantities_by_lot:ACC-1001 LOT-9001 200 LOT-9002 1200 HSET prices_by_lot:ACC-1001 LOT-9001 125.56 LOT-9002 180.63
检索值
127.0.0.1:6379> HGETALL tickers_by_lot:ACC-1001 1) "LOT-9001" 2) "AAPL" 3) "LOT-9002" 4) "CAT" 127.0.0.1:6379> HGETALL quantities_by_lot:ACC-1001 1) "LOT-9001" 2) "200" 3) "LOT-9002" 4) "1200" 127.0.0.1:6379> HGETALL prices_by_lot:ACC-1001 1) "LOT-9001" 2) "12556" 3) "LOT-9002" 4) "18063"
客户端现在需要执行的操作如下
这带来了 O(N+T) 的总时间复杂度——与之前相同。
从管线的角度来看,这变为
因此,我们将网络跳跃次数减少了一次——绝对数量不多,但在相对意义上减少了 33%。
此外,由于我们知道键,并且可以将任何特定账户的所有键映射到同一槽中,因此我们可以轻松使用 LUA。考虑到操作的简单性,我们将不再深入研究 LUA,但请注意,这种设计至少使得使用 LUA 成为可能!
在一个简单的基准测试中,数据模型 B 运行速度快了 4.13 毫秒(通过数千次运行进行基准测试)。考虑到这仅在每次为账户初始化客户端时运行一次,这可能对整体性能没有影响。
在本博客中,我们展示了使用 Redis 数据类型实现实体模型的两种可能方法。我们还介绍了在选择 Redis 数据类型时应执行的时间复杂度分析,以及对网络性能改进的考虑——这在高规模和高性能要求下是关键的一步。在后续的博客中,我们将随着数据模型的扩展进一步阐述这些想法。
我们介绍了大规模管理证券投资组合的一些业务挑战,并展示了以下内容
具备了这两项关键功能后,经纪商应用程序客户端可以提供实时投资组合更新,其性能和可扩展性能够处理数百万个账户。此设计可以实时呈现投资组合的总价值以及每项持有的收益或损失。此数据模型和架构还可以应用于证券以外的用例,例如加密货币、广告交易等。