 Redis 8 已发布,并且它是开源的
Redis 8 已发布,并且它是开源的
了解更多

了解如何将 Redis PubSub 与 Bytewax 结合使用以有效处理实时数据。本指南深入探讨了如何创建自定义输入源并高效聚合点击流数据。
在本指南中,我们将展示如何为 bytewax 编写自定义输入源,该输入源从 Redis pubsub 通道读取数据。所有代码都可以在 bytewax/example-redis 仓库中找到。
我们先来看看 Redis PUBSUB 通道。本质上,它是一种消息传递范例,虽然 Redis 以缓存系统闻名,但其能力远不止于此(PUBSUB 通道只是在数据基础设施中使用 Redis 集群的众多方式之一)。PUBSUB 通道功能自 2.8.0 版本(于 2013 年 11 月发布)以来就已经存在。一个更近期的补充是 Redis Streams,它于 2018 年在 Redis 5.0 中引入。这两者主要在交付保证上有所不同。Streams 提供 至多一次 (at-most-once) 和 至少一次 (at-least-once) 语义,而 PUBSUB 只支持 至多一次 (at-most-once)。我发现 PUBSUB 是一个更普遍的功能,但在本指南之后,适应 Streams 应该也很顺利。
假设我们从两个 Python 脚本开始——一个发布者和一个监听器(也许是团队中的另一位开发者传下来的)。这两个脚本都利用官方的 redis-py 库进行基本操作:连接和交换消息。
假设我们的消息是某种点击流。为了简单起见,我们将从文件中读取它,消息看起来像这样
{"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "[email protected]", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
{"click_id": "dd5a2b23-3357-4bba-857a-1afdb45f9144", "os": "Android 1.5", "os_name": "Android", "os_timezone": "America/Sao_Paulo", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "[email protected]", "user_domain_id": "e7a09617-3635-44b5-b119-8c1034865a9f"}
{"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "[email protected]", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
...
您可以在 仓库中查看事件文件
下面的发布者脚本读取一个 .jsonl 文件,并将其内容发布到 Redis 通道
# redis_publisher.py
import os
import pathlib
import redis # pip install redis
# Configuration
REDIS_HOST = os.getenv('REDIS_HOST', 'localhost')
REDIS_PORT = int(os.getenv('REDIS_PORT', '6379'))
CHANNEL_NAME = os.getenv('REDIS_CHANNEL_NAME', 'device_events')
JSONL_FILE = 'events.jsonl'
# Connect to Redis
r = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)
# Read the .jsonl file and publish it to the Redis channel
with pathlib.Path(JSONL_FILE).open() as file:
for line in file:
r.publish(CHANNEL_NAME, line)
print("👍 events published")
运行 Redis 实例的 docker 命令
docker run -d --rm -p 6379:6379 redis:latest
发布消息
python redis_publisher.py
使用 JSONL 文件格式时,文件的每一行都是一个 json 对象,因此我们在发布端不需要进行任何处理,只需“原样”发送消息即可。如果我们使用提供的命令运行容器,我们将使用默认连接设置,因此无需提供任何环境变量,只需在不带任何参数的情况下运行发布者脚本(假设 events.jsonl 位于同一目录中)
监听器脚本监听一个通道并记录接收到的消息。除了轮询机制外,它相当简单。这样的脚本可能看起来像这样
# redis_listener.py
import logging
import os
import redis
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Configuration
REDIS_HOST = os.getenv('REDIS_HOST', 'localhost')
REDIS_PORT = int(os.getenv('REDIS_PORT', '6379'))
CHANNEL_NAME = os.getenv('REDIS_CHANNEL_NAME', 'device_events')
# Connect to Redis
r = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)
# Function to handle the messages from the channel
def message_handler(message):
data = message['data'].decode('utf-8')
logger.info(f'Received data: {data}')
# Subscribe to the channel
pubsub = r.pubsub()
pubsub.subscribe(**{CHANNEL_NAME: message_handler})
# Listen for incoming messages
logger.info(f'Listening to channel: {CHANNEL_NAME}')
pubsub.run_in_thread(sleep_time=0.001)
运行此脚本然后向通道发布消息应该会输出如下内容
INFO:__main__:Listening to channel: device_events
INFO:__main__:Received data: {"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "[email protected]", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
INFO:__main__:Received data: {"click_id": "dd5a2b23-3357-4bba-857a-1afdb45f9144", "os": "Android 1.5", "os_name": "Android", "os_timezone": "America/Sao_Paulo", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "[email protected]", "user_domain_id": "e7a09617-3635-44b5-b119-8c1034865a9f"}
...
尽管这种方法可行,但随着复杂性的增加,它可能显得笨拙。如果你有写 Python 的经验,你可能已经注意到了这个脚本中一些可能让你皱眉的地方。消息处理程序使用 kwargs 参数注册,带有一个 awkward 的 channel name -> function 字典,然后我们使用线程来运行监听器。我不知道你怎么看,但对我来说,在 Python 中使用线程从来都不是一件有趣的事。此外,每当我在代码中看到某个地方有一个带浮点值的 sleep 时,我总是会质疑自己。而这一切都只是为了一个简单的类似 echo 的管道:如果我们添加更多步骤,它很容易就会变成一个混乱的、循环复杂度很高的回调函数。
值得一提的是,使用 redis-py 设置 pub/sub 有多种方式, 有些比其他方式更优雅。根据您的具体情况,您可以找到更合适的方式,但您仍然需要管理处理的复杂性。因此,为了构建更结构化和可扩展的管道,我们将转向 bytewax。
在继续之前,让我们回顾一下我们当前的小型 echo 管道是什么样子,并约定一些术语
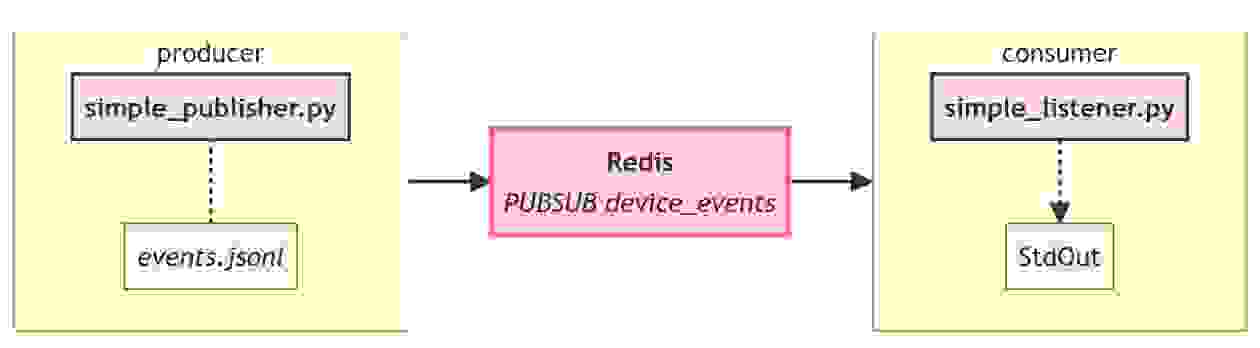
我们将把“Redis 左侧的一切”称为 “生产者(producer)” ,将“Redis 右侧的一切”称为 “消费者(consumer)”。这只是一个约定,我们也可以选择“writer”/“reader”或“publisher”/“subscriber”。严格来说,如果你要吹毛求疵,这些术语有一些差异,但在本文的上下文中,它们是无关紧要的。使用这个术语,我们应该补充一点
现在,当我们进一步使用 bytewax 重写消费者时,左侧的一切都将保持不变。当然,Bytewax 也可以用于生产者端,但这将是另一篇博客文章的主题 🙂
在尝试新工具时,从小处着手总是一个好主意。因此,我们将首先使用 bytewax 复现我们的 echo 管道。一旦验证了基本功能,我们随时可以添加更多的计算步骤。幸运的是,由于我们已经有一个功能正常的监听器脚本,主要任务就是以正确的方式将其集成到 bytewax 中。
创建自己的连接器时,内置的 KafkaSource 是一个很好的参考。我们将把我们的命名为 RedisPubSubSource,它应该是 FixedPartitionedSource 的子类,以确保每个分区维护一个独立的 StatefulSourcePartition 对象,这也是我们需要编写的。让我们深入探讨一下。
消息处理的核心逻辑位于 StatefulSourcePartition 中,这也是我们放置通道处理代码的地方
class RedisPubSubPartition(StatefulSourcePartition):
def __init__(self, redis_host, redis_port, channel):
r = redis.Redis(host=redis_host, port=redis_port)
self.pubsub = r.pubsub(ignore_subscribe_messages=True)
self.pubsub.subscribe(channel)
def next_batch(self, _sched):
message = self.pubsub.get_message()
if message is None:
return []
data = message['data']
if isinstance(data, bytes):
data = data.decode('utf-8')
return [data]
def snapshot(self):
return None
def close(self):
self.pubsub.close()
请记住,这不是生产就绪的代码。在实际应用中,您可能需要更多连接设置,并且需要处理其他细节。但对于我们的目的来说,这已经足够了。
让我们仔细看看 next_batch 函数
def next_batch(self, _sched):
message = self.pubsub.get_message()
if message is None:
return []
data = message['data']
if isinstance(data, bytes):
data = data.decode('utf-8')
return [data]
在这里,它首先从订阅的通道中检索消息。如果没有消息,它返回一个空列表。收到消息后,我们对其进行解码。这并非必须在 next_batch 内部发生,但这可以减少后续管道中的冗余。然而,您可能已经发现,这里不包含反序列化。这是因为我们希望在不使代码过度复杂化的情况下灵活更改适合管道需求的序列化格式。当然,这并非严格限制,对于具有稳定模式的源,在此处包含反序列化步骤可能是实用的。或者,通过子类化或将序列化函数作为构造函数参数传递也是实现此目的的一种方式。
让我们概述创建自己的 bytewax StatefulSourcePartition 的两个指导原则
此外,除了 next_batch 之外,我们还添加了两个与快照机制和资源生命周期相关的辅助方法。虽然 KafkaSourcePartition 使用偏移量进行快照,但 Redis PubSub 通道不支持,因此我们在那里使用了一个只返回 None 的占位函数。关闭连接需要调用 PubSub 的 .close() 方法。请注意,我们没有使用任何线程,并且到目前为止的代码与我们原始的监听器代码相比,更加清晰、更符合 Python 风格。
接下来,我们将概述 Source 类,它使用 Partition 并为我们的数据流创建一个输入(或者可以说,“数据入口点”)。
Input 的主要目的是初始化我们之前编写的 PubSub 源,并使用必要的环境连接详细信息对其进行初始化。如果需要进行健全性检查,将其纳入此 Input 类的构造函数中将是最合乎逻辑的选择。
import os
import redis
from bytewax.inputs import FixedPartitionedSource, StatefulSourcePartition
class RedisPubSubPartition(StatefulSourcePartition):
...
class RedisPubSubSource(FixedPartitionedSource):
def __init__(self):
self.redis_host = os.getenv('REDIS_HOST', 'localhost')
self.redis_port = int(os.getenv('REDIS_PORT', '6379'))
self.channel_name = os.getenv('REDIS_CHANNEL_NAME', 'device_events')
def list_parts(self):
return ['single-part']
def build_part(self, now, for_key, resume_state):
return RedisPubSubPartition(
self.redis_host,
self.redis_port,
self.channel_name,
)
将 Input 代码与我们之前简单的监听器脚本进行比较,可以注意到这一部分与原始脚本的配置部分非常一致。至于消息处理,我们不再使用之前使用的直接回调,因为处理已委托给 RedisPubSubPartition。另外还有两个方法, list_parts 和 build_part 值得详细讨论一下。
Bytewax 的底层架构将分区输入视为一组独立、不同的流。理想情况下,在构建管道时,您会知道输入源中有多少个数据分区,这对于任何数据处理管道都是有效的。在大数据处理中拥有多个分区是很常见的,bytewax 被设计为适应多样化的数据需求,因此它需要提供这种灵活性的 API。作为开发者,这基本上意味着您需要实现这两个方法, list_parts 用于获取分区列表,以及 build_part 用于为每个分区构建一个单独的 Partition 对象。
因此,bytewax 的灵活性是以执行这个额外的仪式为代价的,即使您只处理一个分区。这还简化了一些内部考虑,例如快照恢复和故障转移。将这个仪式设为强制是经过深思熟虑的,因为它以一种方式平衡了提供的 API,从而避免了可能让用户感到困惑的“神奇自动化” (“明确比隐晦更好”)。幸运的是,我们当前的场景只使用单通道分区,这使得我们的实现相对简单。
所有组件都已就位,我们现在可以将其全部组合起来,有效地重新创建我们之前的解决方案
# An echo dataflow would consist of an input and an output to stdout
from bytewax.dataflow import Dataflow
from bytewax.connectors.stdio import StdOutSink
from bytewax import operators as op
# ... (definitions of RedisPubSubPartition, RedisPubSubSource)
flow = Dataflow('redis_echo')
stream = op.input('inp', RedisPubSubSource())
op.output('out', stream, StdOutSink())
完整的代码可以在 示例仓库中找到。我们当前的实现看起来像这样
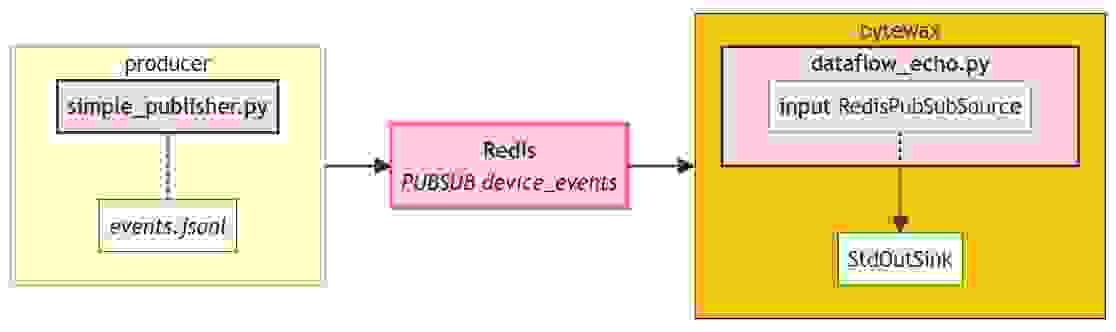
从结构上看,这与我们之前的实现相似,管道的左侧保持不变。
您需要像往常一样运行数据流,使用 bytewax.run 辅助函数
python -m bytewax.run ./src/dataflow_echo.py:flow
输出将保持不变,这是好事,因为这就是我们所期望的
{"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "[email protected]", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
{"click_id": "dd5a2b23-3357-4bba-857a-1afdb45f9144", "os": "Android 1.5", "os_name": "Android", "os_timezone": "America/Sao_Paulo", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "[email protected]", "user_domain_id": "e7a09617-3635-44b5-b119-8c1034865a9f"}
在继续之前,让我们快速将设置 Docker 容器化。这确保我们在隔离的环境中工作,同时也使重新运行管道的发布者部分变得更容易。
compose 文件将包含我们的管道、生产者脚本和 bytewax 数据流
version: '3.8'
services:
redis:
image: "redis:7.2.1"
ports:
- "6379:6379"
simple-publisher:
build:
context: .
dockerfile: docker/redis-simple.Dockerfile
command: python /app/redis_publisher.py
depends_on:
- redis
environment:
REDIS_HOST: redis
REDIS_PORT: 6379
REDIS_CHANNEL_NAME: device_events
EVENTS_JSONL_FILE: /data/events.jsonl
volumes:
- ./data:/data
bytewax-echo:
build:
context: .
dockerfile: docker/redis-bytewax.Dockerfile
command: python -m bytewax.run /app/dataflow_echo.py:flow
depends_on:
- redis
environment:
REDIS_HOST: redis
REDIS_PORT: 6379
REDIS_CHANNEL_NAME: device_events
用于 bytewax dataflow 的 Dockerfile 安装了 redis 和 bytewax 并复制了必要的文件。 发布者脚本的 Dockerfile 基本相同,但 不包含 bytewax。
有了这个结构,我们就可以完全准备好开始让我们的数据流更加复杂化了,所以我们开始吧!对于那些渴望直接看到最终结果的人,此示例的完整源代码可在 此处找到。只需克隆仓库并执行 docker compose up 即可查看我们在下一节将要构建的数据流。
我们的 RedisPubSubSource 已准备好并经过测试,我们不再需要将注意力放在 Redis 上进行任何我们可能感兴趣的数据处理。这使我们可以自由地使用任何现有的数据流步骤,只需做少量修改,当然也可以从头开始编写自己的步骤,将所需的操作串联起来。甚至可以将此 RedisPubSubSource 用作基础设施开销非常小的前期测试设置,然后再将管道过渡到成熟的 Kafka 系统。
为了展示 bytewax 的一些功能,让我们找出我们在不同区域有多少移动用户。为此,我们需要执行以下步骤
以上每一点大致相当于我们数据流中的一个独立步骤。生成的数据流的完整代码
import json
from datetime import timedelta, datetime, timezone
from bytewax import operators as op
from bytewax.connectors.stdio import StdOutSink
from bytewax.dataflow import Dataflow
from bytewax.operators.window import SystemClockConfig, TumblingWindow
from bytewax.operators import window as window_op
from bytewax_redis_input import RedisPubSubSource
def deserialize(payload):
try:
data = json.loads(payload)
except json.decoder.JSONDecodeError:
return None
return data
def initial_count(data):
if data is None:
return 'Uknown', 0
return data['os_timezone'], int(data['device_is_mobile'])
def add(count1, count2):
return count1 + count2
def jsonify(timezone__mobile_count):
tz, count = timezone__mobile_count
return {'timezone': tz, 'num_mobile_users': count}
clock_config = SystemClockConfig()
window_config = TumblingWindow(
length=timedelta(seconds=5),
align_to=datetime(2023, 1, 1, tzinfo=timezone.utc),
)
## build the dataflow
flow = Dataflow('dataflow_mobile_counts)
inp = op.input('inp', flow, RedisPubSubSource())
des = op.map('deserialize', inp, deserialize)
init_count = op.map('initial_count', des, initial_count)
reduce = window_op.reduce_window('sum', init_count, clock_config, window_config, add)
serialize = op.map('jsonify', reduce, jsonify)
op.output('out', serialize, StdOutSink())
这有很多步骤!如果我们运行这个数据流,应该会看到以下输出
{'timezone': 'America/El_Salvador', 'num_mobile_users': 0}
{'timezone': 'Asia/Bangkok', 'num_mobile_users': 0}
{'timezone': 'Europe/Madrid', 'num_mobile_users': 45}
{'timezone': 'America/New_York', 'num_mobile_users': 37}
{'timezone': 'Europe/Berlin', 'num_mobile_users': 29}
{'timezone': 'Africa/Lubumbashi', 'num_mobile_users': 6}
...
我们管道的完整图现在稍微复杂一些
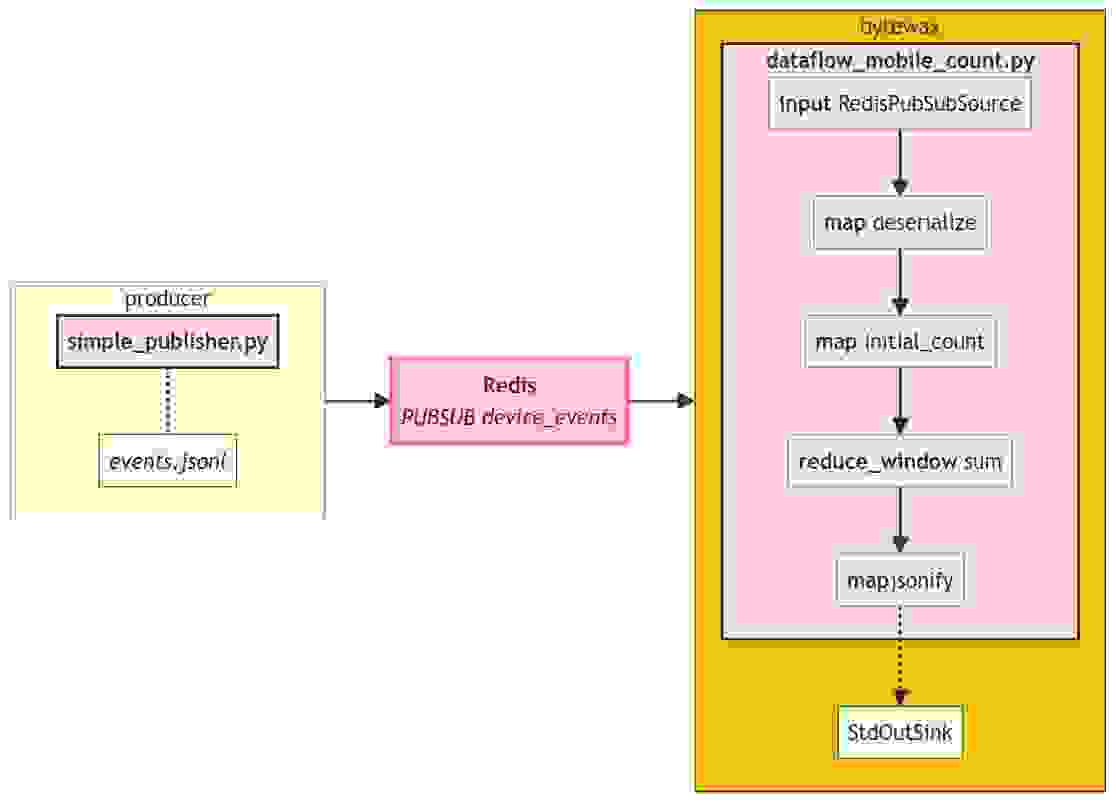
每个步骤都执行其特定的功能,并且足够独立,易于测试和调试。如果您想了解 reduce_window 如何工作,请参阅我们的 文档,因为这不是本文的主要重点。那么,您可能会问,主要重点是什么?很高兴您问到了!主要重点在于强调现在整体管道看起来是多么 符合 Python 风格和精简!每个步骤都易于阅读和修改;本质上,只有几行代码就能高效地将数据流入组织成一组计数,例如,随时可提交到外部 BI 平台。
但这不仅仅是我们的一面之词,我们鼓励您亲自探索和实验!您可以在 专门的仓库中获取完整的代码。随意添加更多步骤、调整管道逻辑,甚至考虑重写 RedisPubSubSource 类——无论您选择哪条路径,bytewax 都能满足您的需求。
在本文中,我们概述了如何以 Redis PubSub 通道为例编写自己的 bytewax Input。我们从一个简单的 echo 示例到窗口计算。该示例可以很容易地扩展到其他系统。
一些要点
希望这篇文章能激励您编写自己的输入源并解开这个过程的神秘面纱。如果您有任何意见或建议,请在社区频道中提出或在 bytewax/example-redis 仓库中提交问题。

