 Redis 8 已发布,它是开源的
Redis 8 已发布,它是开源的

视频

使用 Google Cloud 上的 Redis Enterprise 构建特征存储
了解更多


Google 和 Redis 正在合作,以确保在新 CPU 架构上实现最佳服务器性能。一个很好的例子是:我们的基准测试显示,T2D 比老一代的 Rome Google Cloud 机器具有高达 75% 的性价比提升。
Google Cloud 的虚拟机 (VM) 系列 T2D Tau VM 基于第三代 AMD EPYCTM 处理器。它为客户在向外扩展工作负载方面提供了令人印象深刻的性价比,并且无需将基于 x86 的应用程序移植到新的处理器架构。
对系统性能进行基准测试有助于我们提供最佳价值和体验。否则我们如何衡量我们想要实现的目标呢?在这篇博客文章中,我们将探讨 T2D Tau VM 如何为 Redis Enterprise 软件工作负载带来最佳性价比。
在这两种工作负载上,与老一代的 Rome Google Cloud 机器相比,T2D 的性价比(每美元吞吐量)提高了高达 75%。基准测试还显示,与同代的 Milan Google Cloud 机器相比,性价比提高了高达 40%。
为了准确地对此工作负载进行性能基准测试,我们使用了开源工具 PerfKit Benchmarker (PKB),该工具提供有助于比较云产品的数据。PKB 将数百个行业标准基准测试工具封装在一个易于使用且可扩展的包中。这包括 Redis 自带的 memtier benchmark,我们使用它来生成 Redis Enterprise 版的工作负载。PKB 处理基准测试所需的所有云资源预置、软件包安装、工作负载执行和清理。
整体基准测试流程如下:
收集的指标包括:
我们使用两种配置进行了测试:
第一种设置是单虚拟机性能。为了全面覆盖各种 NUMA 配置下的性能,我们使用了以下 vCPU 计数:2、4、8、16、30/32。
第二种设置类似于一般 Redis Enterprise 客户会使用的配置。不同之处在于,它在单个集群上引入了具有复制功能的多个数据库。对于这种设置,我们特别关注由三台 16 vCPU 服务器组成的集群。
| 节点 1(16 vCPU | 64GB RAM) | 节点 2(16 vCPU | 64GB RAM) | 节点 3(16 vCPU | 64GB RAM) |
| 代理(所有主分片策略) | 代理(所有主分片策略) | 代理(所有主分片策略) |
| DB-1 主分片(7.5GB) | DB-3 主分片(7.5GB) | DB-5 主分片(7.5GB) |
| DB-2 主分片(7.5GB) | DB-4 主分片(7.5GB) | DB-6 主分片(7.5GB) |
| DB-3 复制分片(7.5GB) | DB-5 复制分片(7.5GB) | DB-1 复制分片(7.5GB) |
| DB-4 复制分片(7.5GB) | DB-6 复制分片(7.5GB) | DB-2 复制分片(7.5GB) |
| 已利用 30/64GB(47% 利用率) | 已利用 30/64GB(47% 利用率) | 已利用 30/64GB(47% 利用率) |
此基准测试并非易事。服务器配置和工作负载配置有很多参数需要调整。我们的目标是确保最终结果稳定一致,并报告每种机器类型的最佳可实现吞吐量。本节介绍了本次实验的基准测试原则。
目标是避免客户端成为瓶颈,因此我们选择的客户端明显大于服务器。例如,对于一台 16 vCPU 的服务器,我们预置两台 32 vCPU 的客户端。
我们在 GCP AMD 机器上进行测试:T2D (Milan), N2D (Rome/Milan), E2 (Rome)
访客操作系统的选择极大地影响服务器性能。为了便于比较,这些服务器运行 CentOS 7,这在 Redis Enterprise 用户中很流行。
所有测试均在运行 CentOS 7 的服务器上安装和运行 Redis Enterprise Software 版本 6.2.4-54。
我们没有为基准测试启用透明大页,因为使用它们会导致 Redis 出现延迟损失。
访客安全缓解措施在一定程度上会影响性能。然而,为了便于比较,我们让所有 GCP 机器都保持默认的缓解措施。打开和关闭它们对结果没有明显的影响。
放置组影响虚拟机的物理放置紧密度;它们根据配置设置影响延迟。对于这些实验,我们使用了集群放置组策略。
我们根据不同的分片数量(在单虚拟机情况下)、代理线程和客户端线程为服务器提供了优化的配置。每种机器类型都有一个最佳数量,基准测试会对此进行优化以找到最佳吞吐量。
以下示例数据库创建命令允许我们更改服务器上运行的 Redis 分片数量。
curl -v -k -u [email protected]:a9a204bb13 https://:9443/v1/bdbs -H
'Content-type: application/json' -d
'{"name": "redisdb",
"memory_size": 10000000000,
"type": "redis",
"proxy_policy": "all-master-shards",
"port": 12006, "sharding": true,
"shards_count": {_SHARD_COUNT.value},
"shards_placement": "sparse",
"oss_cluster": true,
"shard_key_regex": [{"regex": ".*\\{(?<tag>.*)\\}.*"}, {"regex"
"(?<tag>.*)"}]}'}
以下是我们进行基准测试的方法。
负载生成和基准测试使用 memtier benchmark (v1.2.15) 完成,该工具预装在 Redis Enterprise 中。这个行业标准基准测试也用于对托管/非托管的 Redis 和 Memcached 进行基准测试。
我们预加载集群:
memtier_benchmark -s localhost -a a9a204bb13 -p 12006 -t 1 -c 1 --ratio 1:0 --pipeline 100 -d 100 --key-pattern S:S --key-minimum 1 --key-maximum 1000000 -n allkeys --cluster-mode |
这将在服务器上预加载约 100MB 的数据,以在测试开始前最大限度地减少缓存的影响。在我们的实验中,将初始数据大小提高到约 8GB 的规模并没有影响结果。
为了运行基准测试,我们逐渐增加 memtier 线程的数量,直到平均延迟高于 1ms 的延迟上限。达到此阈值后,我们记录服务器可以维持的最大吞吐量 (ops/sec)。此指标可以视为实际吞吐量的指示。
memtier_benchmark -s 10.240.6.184 -a a9a204bb13 -p 12006 -t 4 --ratio 1:1 |
此命令在每个客户端虚拟机上运行。结果被记录、测量和聚合。
有关如何设置 PKB 的说明,请参阅入门页面。
对于单虚拟机配置,我们运行:
./pkb.py --cloud=GCP --benchmarks=redis_enterprise --config_override='redis_enterprise.vm_groups.clients.vm_spec.GCP.machine_type='"'" |
对于代表性集群配置,我们运行:
./pkb.py -cloud=GCP --benchmarks=redis_enterprise |
以下是每种机器类型在分片数量、代理线程和客户端线程方面的优化结果。在单虚拟机每 vCPU 比较中,T2D 在吞吐量和性价比方面通常接近领先或处于领先地位。在代表性集群配置中,T2D 也具有卓越的性价比。
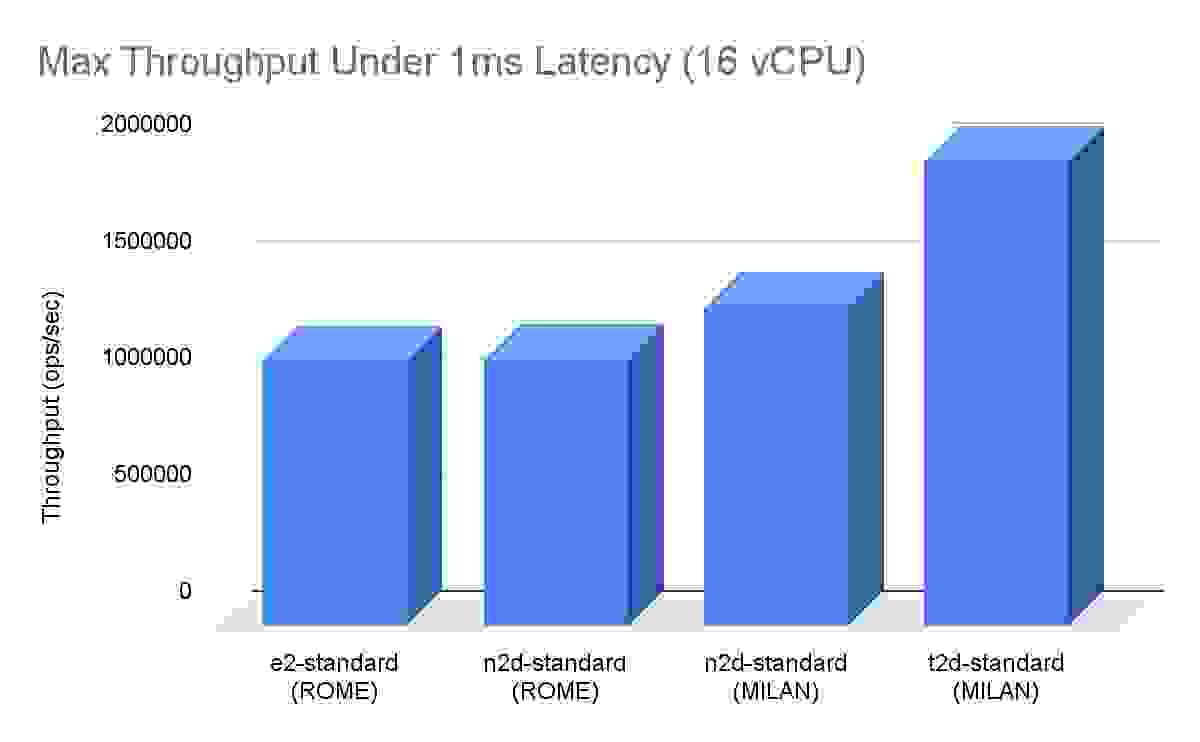
在单虚拟机 16 vCPU 吞吐量比较中,T2D 比 N2D Milan 机器高出约 50%,比上一代 N2D Rome 高出约 75%。
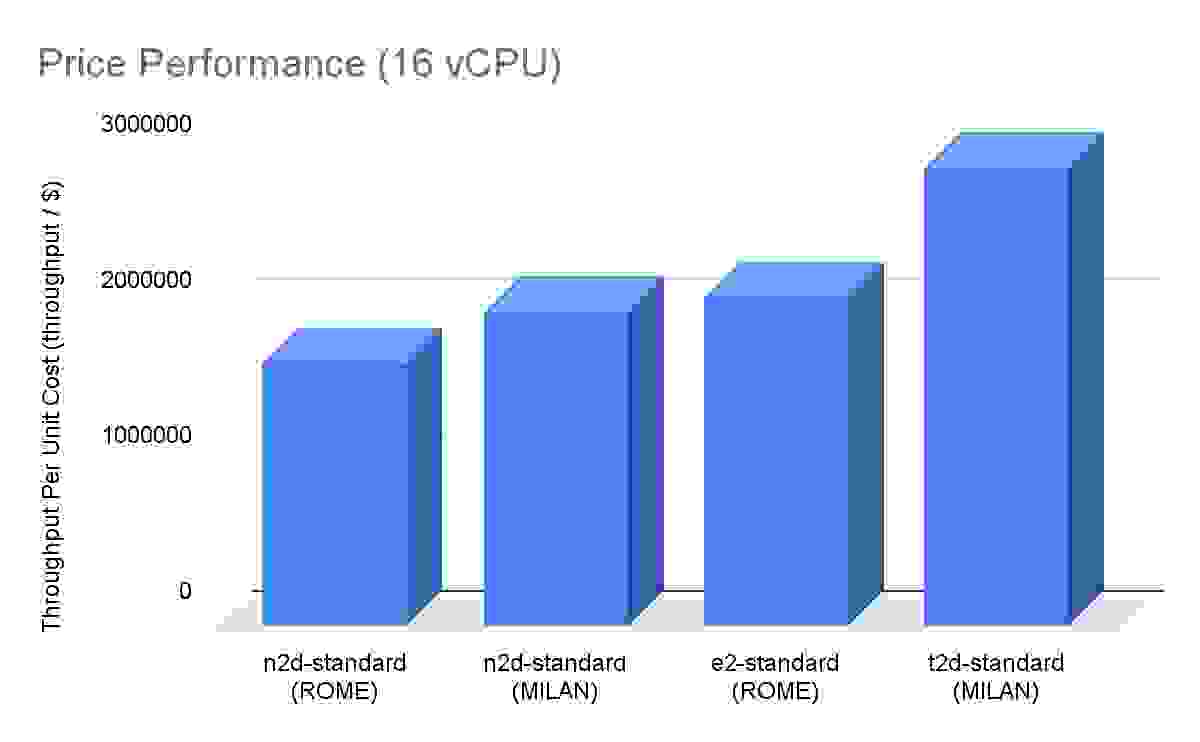
在单虚拟机 16 vCPU 性价比比较中,T2D 比上一代 E2 Rome 机器高出约 40%,比 N2D Rome/Milan 高出约 75%。
在代表性集群配置中,我们在 T2D-standard-16 上实现了在 1ms 延迟下的吞吐量超过 390 万次操作/秒。这意味着在 T2D 上每美元查询次数/秒约为 580 万(基于每小时成本),比其他 AMD 机器类型提高了 40% 以上。它是性价比赢家。
Google Cloud 的 T2D 在此工作负载上具有卓越的吞吐量和性价比,是性能最佳的 GCP AMD 机器。
我们对 Google Cloud 和 Redis Inc. 在跟踪新 CPU 架构性能方面的合作感到兴奋。这使我们能够提供最有益的改进,并为客户带来最佳的用户体验。使用 PKB 进行基准测试使我们能够在重要指标上合作,并确保结果对客户而言是可重现的。
我们期待继续合作。Redis 将继续利用 Google Cloud 推向市场的最新、最优质的虚拟机类型挑战现状 – 共同为客户提供最具成本效益的实时数据库解决方案。

