 Redis 8 已发布 — 并且是开源的
Redis 8 已发布 — 并且是开源的



视频
高可用性架构揭秘
了解更多
在 Redis Enterprise 集群的幕后发生了很多事情。代理将所有这些活动对数据库客户端屏蔽起来。
大多数开发者在构建应用时都从小处着手,使用简单的 Redis 开源 (Redis OSS) 数据库,即使他们知道该软件将成为复杂系统的一部分。一开始,使用数据库相当直接。它有一个单一的端点,应用连接到该端点并开始发送请求。仅此而已。
当 Redis 应用需要更多功能(例如扩展和高可用性)时,挑战就开始了。您可以为此目的使用Redis OSS 集群和Redis Sentinel。然而,这需要开发者维护数据库拓扑并处理扩展的实际问题。换句话说,您必须 编写更多代码。在企业层面,这很快就会变得复杂。
Redis Enterprise 通过减少额外工作来解决这些复杂性问题。无论您是在企业级别开始还是从 Redis OSS 迁移,我们都将其设计为在大规模环境中表现出色,同时使应用能够简单地使用数据库。
在这篇文章中,我们重点介绍 Redis Enterprise 代理。我们展示了常见的 Redis 集群场景示例,演示了代理如何缓解拓扑变化。最后,我们分享了基准测试数据,展示了代理的效率。
Redis Enterprise 代理是一个具有可忽略延迟的实体,它在应用和数据库之间进行中介。它向数据库客户端暴露数据库端点,同时屏蔽 Redis Enterprise 集群在幕后执行的活动。这使得开发者可以专注于应用如何使用数据,而不是担心数据库拓扑的频繁变化。
代理采用多线程架构。它可以通过使用更多可用核心轻松扩展。它被设计用于通过多路复用和管道化来应对高流量。当数千个客户端同时连接到 Redis Enterprise 时,代理会将所有传入请求整合到一组内部管道中,并将其分发到相关的数据库分片。最终结果:请求处理速度大大加快,从而实现高吞吐量和低延迟。
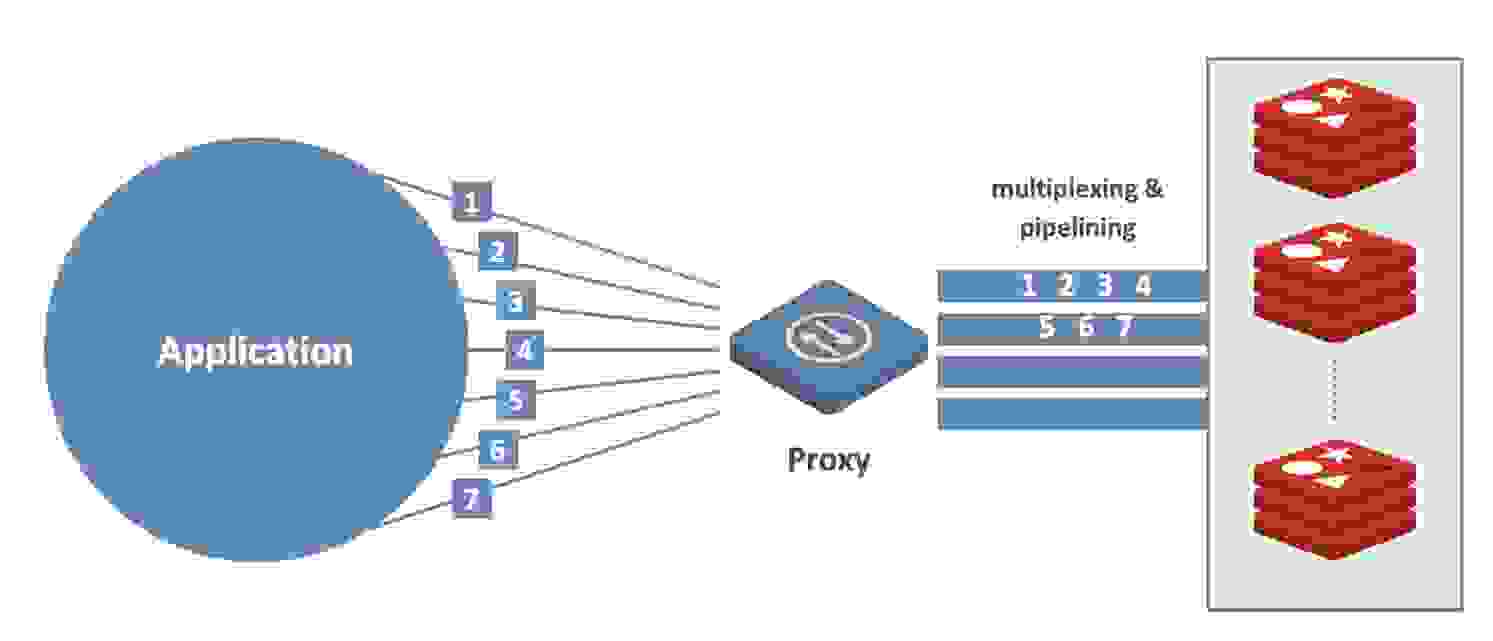
所有这些实际意义是什么?让我们看几个导致拓扑变化的常见集群级别场景。我们展示了这些变化如何隐藏在代理后面,代理继续像以前一样向用户暴露相同的数据库端点。从开发者(即您)的角度来看,这意味着更少的编码以及从 Redis OSS 到 Redis Enterprise 的平滑迁移。
每当数据库分片达到某个(预定义的)大小时,Redis Enterprise 就可以对其进行扩展。扩展是通过启动新的 Redis 实例并将一半的哈希槽从原始分片移动到新分片来实现的。这使得数据库的吞吐量和性能线性增加。
在 Redis Enterprise 中,有两种扩展数据库的方式
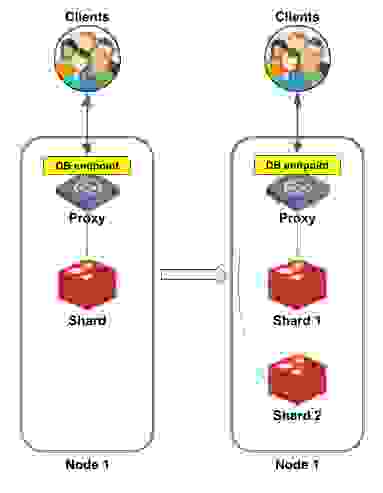
图 2 显示了将单分片数据库横向扩展到双分片数据库的示例。左侧(扩展前)可以看到包含单个分片的单个节点。右侧(扩展完成后),数据库被重新分片。现在分片 1 和分片 2 位于同一节点中,每个分片持有哈希槽的一半。
横向扩展是否改变了客户端连接数据库的方式? 不,没有。客户端继续像以前一样向相同的数据库端点发送请求,让代理负责将每个请求转发到适当的分片。
请注意,这与 Redis OSS 集群不同,在 Redis OSS 集群中,客户端分别连接到每个分片,因此必须了解集群拓扑。
相比之下,考虑在使用多代理策略时纵向扩展数据库会发生什么。在这种情况下,我们在同一端点后运行多个代理。
(请注意,使用 Redis Enterprise,您在使用OSS 集群 API 时也可以纵向扩展数据库。然而,在这种情况下,每个代理都有自己的端点。)
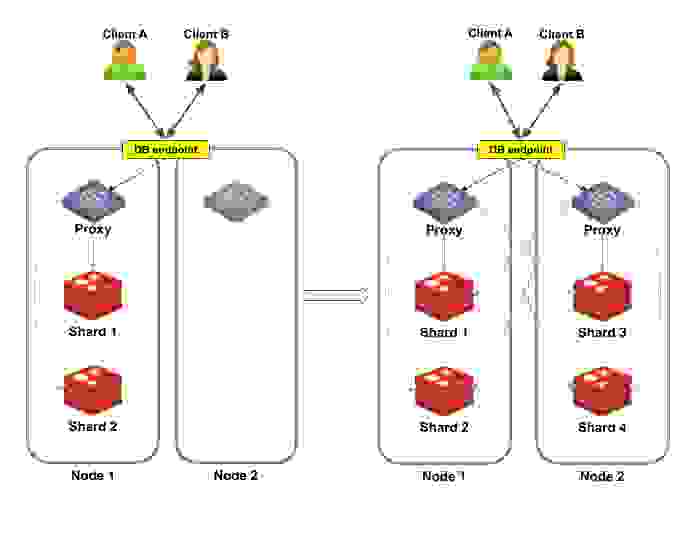
图 3 显示了将双分片数据库纵向扩展到四分片数据库的示例。左侧在集群中添加了一个新节点,其中包含一个尚未激活的代理。纵向扩展完成后,分片 1 和分片 2 位于节点 1,分片 3 和分片 4 位于节点 2。两个节点现在都包含活动代理。
然而,纵向扩展不会改变客户端连接数据库的方式,因为这些变化对客户端是完全透明的。数据库继续像以前一样向相同的数据库端点发送请求。处理每个请求的代理会将这些请求转发到相关的分片。
Redis Enterprise 高可用性的一个关键方面是自动故障转移,它依赖于数据复制。当 Redis Enterprise 集群中检测到故障时——无论是数据库分片中断还是整个节点故障——集群都设计为能在几秒钟内自愈。
修复过程由集群管理器执行,通常需要集群内部进行数据库拓扑更改。代理会收到通知并根据新的拓扑进行调整。
从数据库客户端的角度来看,没有任何变化。由于拓扑更改是内部的,并且隐藏在代理后面,客户端继续像以前一样使用相同的数据库端点。
让我们看两个故障转移示例。
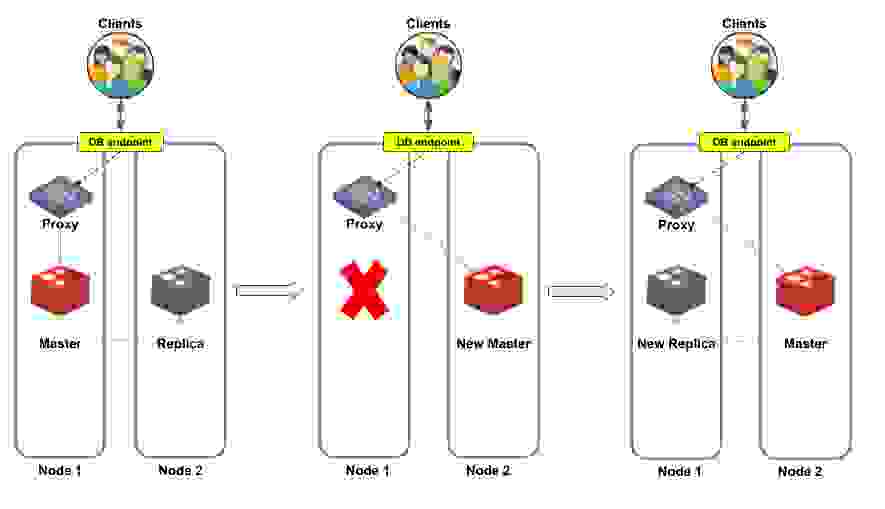
图 4 的左侧是节点 1 中的主分片,其副本位于节点 2。代理将所有客户端请求发送到主分片,主分片不断地与副本同步数据更改。到目前为止一切顺利。但是当出现问题时会发生什么?
如果主分片发生故障,Redis Enterprise 集群管理器将副本分片提升为主分片。代理现在将传入请求重定向到新的主分片,使客户端可以照常继续。最后一步是创建新的副本分片(如图 4 右侧所示)。
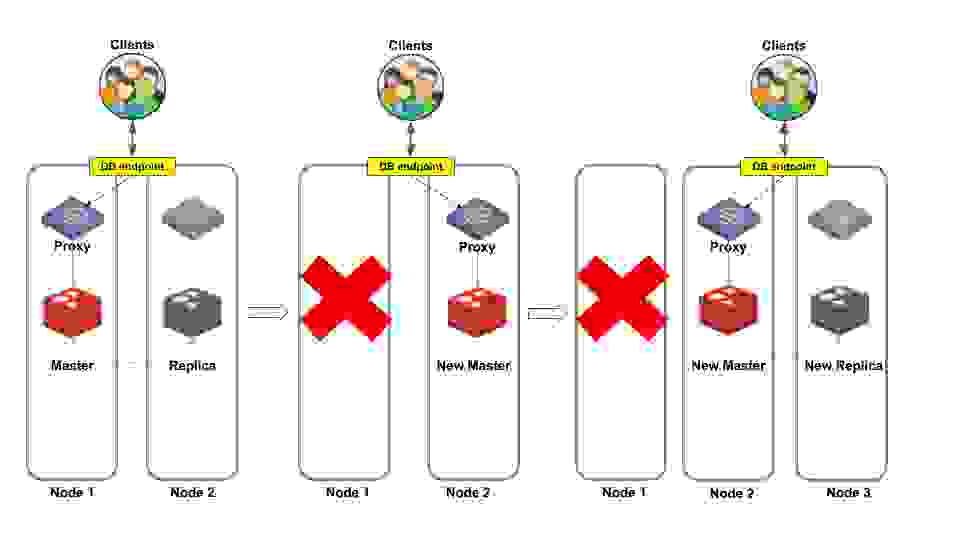
在此示例中,整个节点发生故障,包括主分片和代理。数据库客户端断开连接。
然而,一旦 Redis Enterprise 集群管理器完成故障转移过程,客户端会重新连接到与之前相同的数据库端点并照常继续。从开发者和运维的角度来看,无需进行任何更改,因为集群故障转移机制将相同的端点分配给不同的代理。
图 5 说明了节点 1 发生故障时的过程。节点 2 的代理变为活动状态,Redis Enterprise 将副本提升为主分片。数据库现在再次可用,因此客户端可以重新连接而无需知晓此拓扑更改。集群管理器还找到一个健康的节点(节点 3),Redis Enterprise 在其中创建一个新的副本分片。
代理无疑简化了数据库客户端的操作。但是它有多快呢?为了检验其效率,让我们看看一些基准测试数据。
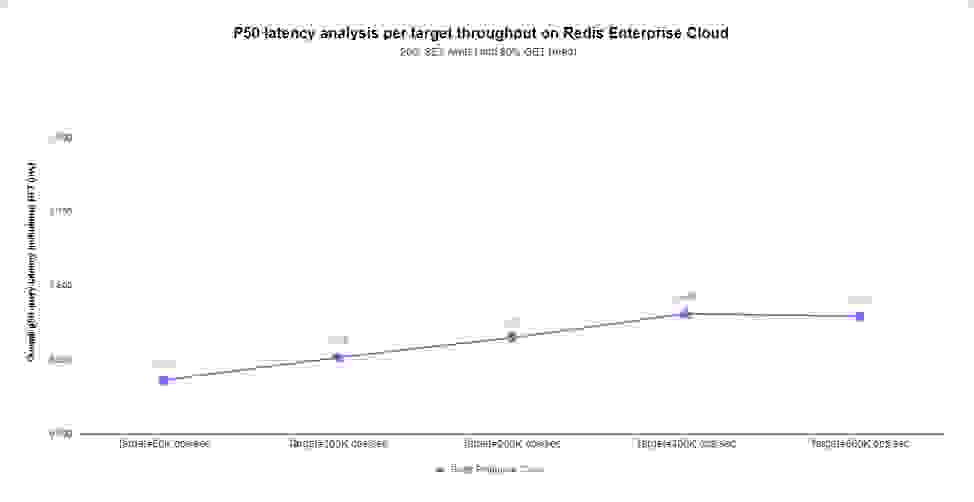
为了对延迟进行基准测试,我们使用了单端点 Redis Enterprise Cloud 集群。我们执行了一个常见场景,包含 20% 的 SET (写入) 命令和 80% 的 GET (读取) 命令混合。
我们创建了一个内存限制为 5GB 的数据库,并选择了五个吞吐量目标:50K、100K、200K、400K 和 800K ops/sec (每秒操作数)。对于每种配置,Redis Enterprise Cloud 选择要使用的适当云实例,确保集群拥有足够的资源且成本最低。
以下结果展示了 Redis Enterprise 的速度之快。该基准测试在所有目标吞吐量下均保持亚毫秒级中位数 (p50) 延迟。在某些情况下,它甚至实现了亚毫秒级 p99 延迟。
| 目标吞吐量 (ops/sec) | 客户端连接数 | 分片数 | 每连接 p50 延迟 (毫秒) | 每连接 p99 延迟 (毫秒) |
| 50,000 | 2000 | 2 | 0.182 | 0.317 |
| 100,000 | 2000 | 4 | 0.258 | 0.588 |
| 200,000 | 2000 | 8 | 0.325 | 1.184 |
| 400,000 | 2000 | 16 | 0.406 | 2.791 |
| 800,000 | 2000 | 32 | 0.398 | 2.907 |
Redis 的我们相信简单性的力量。这就是为什么我们将 Redis Enterprise 设计为从 Redis OSS 迁移到企业级别的最佳选择。
试用Redis Enterprise Cloud或下载最新的Redis Enterprise Software以开始免费试用。

