 Redis 8 已发布——并且是开源的
Redis 8 已发布——并且是开源的

视频
通过 Redis Enterprise 6.0 重新认识 Redis 安全性
了解更多

我们很高兴宣布 RediSearch 2.0 开发的首个里程碑版本发布。RediSearch 是一款实时搜索引擎,可让您查询 Redis 数据以回答各种复杂问题。
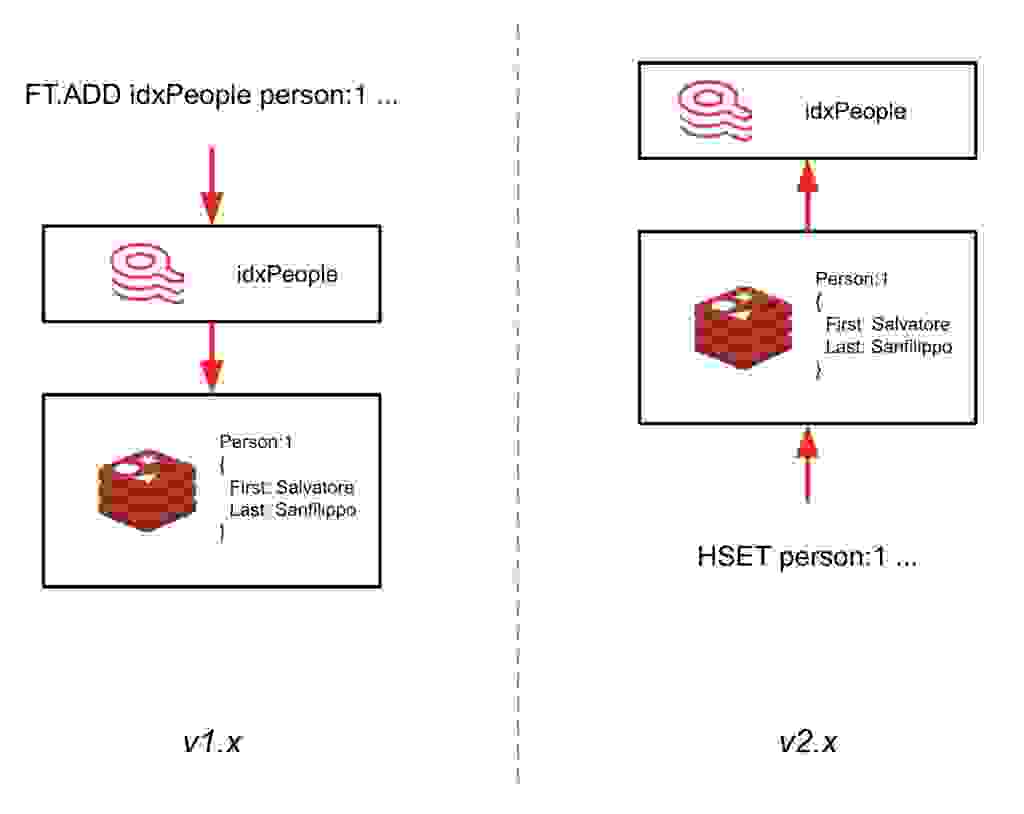
这个里程碑版本,被称为 2.0-M01,标志着索引与数据保持同步方式的重新架构。现在,RediSearch 将不再需要通过索引写入数据(使用 FT.ADD 命令),而是跟随写入 hashes 的数据并自动对其进行索引。
这里最大的优势在于,您现在可以将 RediSearch 添加到现有的 Redis 实例中,并在无需更新应用程序代码的情况下创建辅助索引。这样,您只需加载 RediSearch 模块并定义 schema,就可以立即开始在现有数据上使用 RediSearch。RediSearch 2.0 的正式发布预计在今年秋季。
(注意:这项新功能对API 引入了一些更改(如下所列)。我们尽量保持向后兼容性,但在这种情况下确实不可能。我们计划在收集客户反馈后进行调整和修复。)
如上所述,此 RediSearch 2.0 里程碑版本包含多项 API 变更:
API 的最大更新是索引的创建方式。在 RediSearch 2.0 中,使用命令 FT.CREATE 创建索引。API 的新增内容已在此处用黄色突出显示
FT.CREATE {index}
ON {structure}
[PREFIX {count} {prefix} [{prefix} ..]
[FILTER {filter}]
[LANGUAGE_FIELD {lang_field}]
[LANGUAGE {lang}]
[SCORE_FIELD {score_field}]
[SCORE {score}]
[PAYLOAD_FIELD {payload_field}]
[TEMPORARY {seconds}]
[MAXTEXTFIELDS]
[NOOFFSETS] [NOHL] [NOFIELDS] [NOFREQS]
[STOPWORDS {num} {stopword} ...]
SCHEMA {field} [TEXT [NOSTEM] [WEIGHT {weight}] [PHONETIC {matcher}] | NUMERIC | GEO | TAG [SEPARATOR {sep}] ] [SORTABLE][NOINDEX] ...
让我们深入了解一些细节
RediSearch 2.0-M01 里程碑版本还带来了一些其他更新
FT.ADD idx doc1 1.0 LANGUAGE eng PAYLOAD payload FIELDS f1 v1 f2 v2
映射到
HSET doc1 __score 1.0 __language eng __payload payload f1 v1 f2 v2
这意味着您索引上的 score、language 和 payload 字段必须分别命名为 __score、__language 和 __payload,才能使映射按预期工作。
我们对这些变化感到非常兴奋,因为您现在可以将 RediSearch 加载到现有的 Redis 数据库中,并对存在于 hashes 中的现有数据进行索引,而无需在操作这些文档时更新应用程序逻辑。 您可以通过从 GitHub 获取源代码或使用 1:99:1 的 RedisSarch Docker 镜像来试用这个里程碑版本。此版本尚未达到生产就绪状态,但我们希望现在就与您分享,以收集您的反馈。请在我们的 GitHub 仓库 或在 Redis 社区论坛 分享任何评论或问题。
