 Redis 8 来了—而且是开源的
Redis 8 来了—而且是开源的

视频

如何在 Redis 中管理实时 IoT 传感器数据
了解更多

Redis 拥有 一套多功能的数据结构,从简单的 字符串 一直到强大的抽象概念,例如 Redis Streams。原生数据类型可以满足大部分需求,但某些用例可能需要变通方法。一个例子是在 Redis 中使用二级索引,以便超越基于键的搜索/查找,从而获得更丰富的查询功能。虽然您可以 使用排序集、列表等来完成这项工作,但您需要考虑一些权衡。
隆重推出 RediSearch! RediSearch 可作为 Redis 模块 使用,它通过一流的二级索引引擎提供灵活的搜索功能。它提供了强大的功能,例如全文搜索、自动完成、地理索引等等。
为了演示 RediSearch 的强大功能,这篇博文提供了一个实际示例,说明如何借助 RediSearch Go 客户端,将 RediSearch 与 Azure Cache for Redis 配合使用。它旨在为您提供一组应用程序,让您可以实时提取推文,并使用 RediSearch 灵活地查询它们。
具体来说,您将学习如何:
如前所述,示例服务可让您实时使用推文,并通过 RediSearch 查询它们。
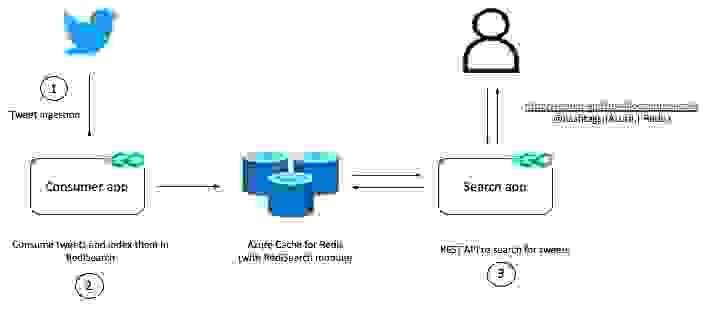
它有两个组件:
现在,我将深入探讨如何启动并运行该解决方案,以便您可以亲眼目睹它的实际效果。但是,如果您有兴趣了解各个组件的工作方式,请参阅下面的“代码演练”部分以及此博客的 GitHub 存储库:https://github.com/abhirockzz/redisearch-tweet-analysis。
先决条件
首先,使用此快速入门教程在 Azure 上 设置 Redis Enterprise 层缓存。完成设置后,请确保手头有 Redis 主机名和访问密钥。

我们服务的两个组件都以 Docker 容器的形式提供:推文索引服务 和 搜索 API 服务。(如果您需要构建自己的 Docker 镜像,请使用 GitHub 存储库上提供的相应 Dockerfile。)
您现在将看到将它们部署到 Azure 容器实例 非常方便,这使您可以在托管的无服务器 Azure 环境中按需运行 Docker 容器。
docker-compose.yml 文件定义了各个组件(tweets-search 和 tweets-indexer)。您所需要做的就是更新它,以替换您的 Azure Redis 实例的值以及您的 Twitter 开发者帐户凭据。这是 完整文件:
version: "2"
services:
tweets-search:
image: abhirockzz/redisearch-tweets-search
ports:
- 80:80
environment:
- REDIS_HOST=<azure redis host name>
- REDIS_PASSWORD=<azure redis access key>
- REDISEARCH_INDEX_NAME=tweets-index
tweets-indexer:
image: abhirockzz/redisearch-tweets-consumer
environment:
- TWITTER_CONSUMER_KEY=<twitter api consumer key>
- TWITTER_CONSUMER_SECRET_KEY=<twitter api consumer secret>
- TWITTER_ACCESS_TOKEN=<twitter api access token>
- TWITTER_ACCESS_SECRET_TOKEN=<twitter api access secret>
- REDIS_HOST=<azure redis host name>
- REDIS_PASSWORD=<azure redis access key>
- REDISEARCH_INDEX_NAME=tweets-index
docker login azure
docker context create aci aci-context
docker context use aci-context
克隆 GitHub 存储库:
git clone https://github.com/abhirockzz/redisearch-tweet-analysis
cd redisearch-tweet-analysis
将两个服务组件部署为 容器组的一部分:
docker compose up -p azure-redisearch-app
(请注意,ACI 上下文中当前可用的 Docker Compose 命令以 docker compose 开头。这与带有连字符的 docker-compose 不同。)
您将看到类似于以下内容的输出:
[+] Running 1/3
⠿ Group azure-redisearch-app Created 8.3s ⠸ tweets-search Creating 6.3s ⠸ tweets-indexer Creating 6.3s
等待服务启动,您还可以查看 Azure 门户。一旦两项服务都启动并运行,您就可以检查它们各自的日志:
docker logs azure-redisearch-app_tweets-indexer
docker logs azure-redisearch-app_tweets-search
如果一切顺利,tweet-consumer 服务应该已经启动。它将读取推文流并将其持久保存到 Redis。
现在是查询推文数据的时候了。为此,您可以使用 IP 地址和完全限定域名 (FQDN) 访问 Azure 容器实例中的 REST API(在 容器访问中阅读更多信息)。要查找 IP,请运行 docker ps 并检查输出中的 PORTS 部分(如下所示)
docker ps
//output
CONTAINER ID IMAGE COMMAND STATUS PORTS azure-redisearch-app_tweets-search abhirockzz/redisearch-tweets-search Running 20.197.96.54:80->80/tcazure-redisearch-app_tweets-indexer abhirockzz/redisearch-tweets-consumer Running
您现在可以运行各种查询!在深入了解之前,这里快速介绍一下您可以在搜索查询中使用的索引属性:
id - this is a the Tweet ID ( TEXT attribute)
user - the is the screen name ( TEXT attribute)
text - tweet contents ( TEXT attribute)
source - tweet source e.g. Twitter for Android, Twitter Web App, Twitter for iPhone ( TEXT attribute)
hashtags - hashtags (if any) in the tweet (available in CSV format as a TAG attribute)
location - tweet location (if available). this is a user defined location (not the exact location per se)
created - timestamp (epoch) of the tweet. this is NUMERIC field and can be used for range queries
coordinates - geographic location (longitude, latitude) if made available by the client ( GEO attribute)
(请注意,我在下面的示例中使用 curl,但强烈推荐 VS Code 的“REST 客户端”)
设置搜索服务 API 的基本 URL:
export REDISEARCH_API_BASE_URL=<for example, http://20.197.96.54:80/search>
从简单开始,查询所有文档(使用 * )
curl -i $REDISEARCH_API_BASE_URL?q=*
您将看到类似于以下内容的输出:
HTTP/1.1 200 OK
Page-Size: 10
Search-Hits: 12
Date: Mon, 25 Jan 2021 13:21:52 GMT
Content-Type: text/plain; charset=utf-8
Transfer-Encoding: chunked
//JSON array of documents (omitted)
请注意标头 Page-Size 和 Search-Hits:这些是从应用程序传递的自定义标头,主要用于演示分页和限制。在响应我们的“获取所有文档”查询时,我们在 Redis 中找到了 12 个结果,但 JSON 正文返回了 10 个条目。这是因为 RediSearch Go API 的默认行为,您可以使用不同的查询参数来更改它,例如
curl -i "$REDISEARCH_API_BASE_URL?q=*&offset_limit=0,100"
offset_limit=0,100 will return up to 100 documents ( limit ) starting with the first one ( offset = 0).
或者,例如,搜索从 iPhone 发送的推文
curl -i "$REDISEARCH_API_BASE_URL?q=@source:iphone"
您可能并不总是想要查询结果中的所有属性。例如,以下是如何仅取回用户(Twitter 屏幕名称)和推文文本
curl -i "$REDISEARCH_API_BASE_URL?q=@location:india&fields=user,text"
如何查询用户名(例如,以 jo 开头)
curl -i "$REDISEARCH_API_BASE_URL?q=@user:jo*"
您也可以在查询中使用属性的组合
bash curl -i $REDISEARCH_API_BASE_URL?q=@location:India @source:android
我们如何查找带有特定主题标签的推文?是否可以使用多个主题标签(用 | 分隔)?
curl -i "$REDISEARCH_API_BASE_URL?q=@hashtags:\{potus|cov*\}"
想知道最近创建了多少带有 biden 主题标签的推文?使用范围查询
curl -i "$REDISEARCH_API_BASE_URL?q=@hashtags:{biden} @created:[1611556920000000000 1711556930000000000]"
如果您幸运地获取了一些关于推文的坐标信息,您可以尝试提取它们,然后在 coordinates 属性上进行查询
curl -i "$REDISEARCH_API_BASE_URL?q=*&fields=coordinates"
curl -i "$REDISEARCH_API_BASE_URL?q=@coordinates:[-122.41 37.77 10 km]"
这些只是一些例子。随意进一步尝试并尝试其他查询。RediSearch 文档中的此部分可能会派上用场!
重要提示: 完成后,不要忘记停止 Azure 容器实例中的服务和相应的容器:
docker compose down -p azure-redisearch-app
使用 Azure 门户 删除您创建的 Azure Redis 实例。
本节概述了各个组件的代码。这应该可以更轻松地浏览 GitHub 存储库中的源代码。
推文使用者/索引器
go-twitter 库已用于与 Twitter 交互。
它验证到 Twitter Streaming API
config := oauth1.NewConfig(GetEnvOrFail(consumerKeyEnvVar), GetEnvOrFail(consumerSecretKeyEnvVar))
token := oauth1.NewToken(GetEnvOrFail(accessTokenEnvVar), GetEnvOrFail(accessSecretEnvVar))
httpClient := config.Client(oauth1.NoContext, token)
client := twitter.NewClient(httpClient)
并且在单独的 goroutine 中监听推文流
demux := twitter.NewSwitchDemux()
demux.Tweet = func(tweet *twitter.Tweet) {
if !tweet.PossiblySensitive {
go index.AddData(tweetToMap(tweet))
time.Sleep(3 * time.Second)
}
}
go func() {
for tweet := range stream.Messages {
demux.Handle(tweet)
}
}()
请注意 go index.AddData(tweetToMap(tweet))— 这就是调用索引组件的地方。 它连接到 Azure Cache for Redis
host := GetEnvOrFail(redisHost)
password := GetEnvOrFail(redisPassword)
indexName = GetEnvOrFail(indexNameEnvVar)
pool = &redis.Pool{Dial: func() (redis.Conn, error) {
return redis.Dial("tcp", host, redis.DialPassword(password), redis.DialUseTLS(true), redis.DialTLSConfig(&tls.Config{MinVersion: tls}
}
然后,它会删除索引(以及现有的文档),然后再重新创建它
rsClient := redisearch.NewClientFromPool(pool, indexName)
err := rsClient.DropIndex(true)
schema := redisearch.NewSchema(redisearch.DefaultOptions).
AddField(redisearch.NewTextFieldOptions("id", redisearch.TextFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("user", redisearch.TextFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("text", redisearch.TextFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("source", redisearch.TextFieldOptions{})).
//tags are comma-separated by default
AddField(redisearch.NewTagFieldOptions("hashtags", redisearch.TagFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("location", redisearch.TextFieldOptions{})).
AddField(redisearch.NewNumericFieldOptions("created", redisearch.NumericFieldOptions{Sortable: true})).
AddField(redisearch.NewGeoFieldOptions("coordinates", redisearch.GeoFieldOptions{}))
indexDefinition := redisearch.NewIndexDefinition().AddPrefix(indexDefinitionHashPrefix)
err = rsClient.CreateIndexWithIndexDefinition(schema, indexDefinition)
删除索引及其关联的文档是为了让您可以从干净的状态开始,这使实验/演示更容易。 如果您愿意,可以选择注释掉此部分。
每条推文的信息都存储在 HASH(命名为 tweet:<tweet ID>)中,使用 HSET 操作:
func AddData(tweetData map[string]interface{}) {
conn := pool.Get()
hashName := fmt.Sprintf("tweet:%s", tweetData["id"])
val := redis.Args{hashName}.AddFlat(tweetData)
_, err := conn.Do("HSET", val...)
}
推文搜索公开了一个 REST API 来查询 RediSearch。 所有选项(包括查询等)都以查询参数的形式传递。 例如,https://:8080/search?q=@source:iphone。 它提取所需的查询参数
qParams, err := url.ParseQuery(req.URL.RawQuery)
if err != nil {
log.Println("invalid query params")
http.Error(rw, err.Error(), http.StatusBadRequest)
return
}
searchQuery := qParams.Get(queryParamQuery)
query := redisearch.NewQuery(searchQuery)
q 参数是强制性的。 但是,您也可以使用以下参数进行搜索:
例如
https://:8080/search?q=@source:Web&fields=user,source&offset_limit=5,100
fields := qParams.Get(queryParamFields)
offsetAndLimit := qParams.Get(queryParamOffsetLimit)
最后,遍历结果并将其作为 JSON(文档数组)传回
docs, total, err := rsClient.Search(query)
response := []map[string]interface{}{}
for _, doc := range docs {
response = append(response, doc.Properties)
}
rw.Header().Add(responseHeaderSearchHits, strconv.Itoa(total))
err = json.NewEncoder(rw).Encode(response)
这就是本节的全部内容!
Redis Enterprise 作为 Azure 上的原生服务提供,以 Azure Cache for Redis 的两种新层 的形式提供,这些层由 Microsoft 和 Redis 运营和支持。 此服务使开发人员可以访问丰富的 Redis Enterprise 功能集,包括 RediSearch 等模块。 有关更多信息,请参见以下资源:
此端到端应用程序演示了如何使用索引,摄取实时数据以创建文档(推文信息),这些文档由 RediSearch 引擎索引,然后使用通用的查询语法提取有关这些推文的见解。
想了解在 Redis 文档中搜索主题时幕后发生的情况吗? 查看此博客文章,了解 Redis 站点如何通过 RediSearch 整合全文搜索! 或者,您是否有兴趣探索如何在无服务器应用程序中使用 RediSearch?
如果您仍在入门,请访问 RediSearch 快速入门页面。
如果您想了解有关 Azure Cache for Redis 中企业功能的更多信息,可以查看以下资源:

