 Redis 8 已到来——并且它是开源的
Redis 8 已到来——并且它是开源的
了解更多

今天,我们很高兴宣布 RedisTimeSeries v1.0 正式发布 (GA)。RedisTimeSeries 是 Redis 开发的一个模块,旨在增强您使用 Redis 管理时间序列数据的体验。我们在六个多月前发布了 RedisTimeSeries 的预览/测试版本,非常感谢社区和客户在与我们一起开发这个首个 GA 版本期间提供的所有宝贵反馈和建议。为了纪念本次发布,我们进行了一项基准测试,与 Redis 中的其他时间序列方法相比,RedisTimeSeries 达到了每秒 12.5 万次查询。跳到完整结果,或者先花点时间了解一下是什么促使我们构建了这个新模块。
许多 Redis 用户使用 Redis 处理时间序列数据已近十年,并且一直感到满意并取得成功。正如我们稍后将解释的,这些开发者正在使用 Redis 通用的原生数据结构。因此,让我们先退一步,解释一下为什么我们决定构建一个具有专用时间序列数据结构的模块。
在下面的 DB-engines 趋势图中,您可以看到时间序列数据库最近人气增长最快。除了不断增长的数据量和自动驾驶汽车、算法交易、智能家居、在线零售等新的时间序列用例之外,我们认为这一趋势有两个主要的技术原因。
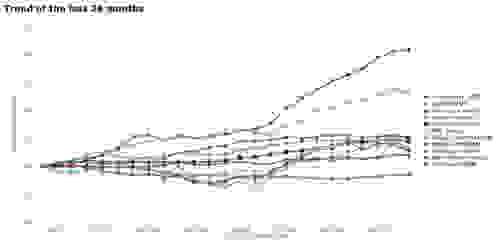
第一个原因是,时间序列数据的查询模式和规模与现有数据库技术的构建目的不同。虽然大多数数据库设计为服务更多的读操作而不是写操作,但时间序列用例具有高吞吐量的大量数据写入速率,而读查询的数量较少。在根因分析用例中,读取是零星的,仅触及数据集的随机部分。在训练 AI 模型(例如,用于传感器数据中的异常检测)的用例中,读取通常会跨越数据集的较大部分,但发生频率仍远低于写入。由于 Redis 的可伸缩架构能够以低延迟实现高写吞吐量,因此 Redis 非常适合当前的时间序列查询模式。
这一趋势的第二个原因是,处理时间序列所需的工具集在传统数据库技术中并不存在。有效利用资源需要进行一些结构性改变,例如对历史时间序列数据进行自动降采样和双增量编码,以及直观地查询和聚合时间序列数据的功能。传统数据库技术需要应用程序方面付出大量精力来处理保留、降采样和聚合等功能。
在 Redis,我们坚信“自己动手,丰衣足食”(吃自己的狗粮)。对于我们的云产品(管理着运行在数千个 Redis Enterprise 集群上的 100 多万个 Redis 数据库),我们在内部 Redis 数据库中收集每个集群的指标。在增强我们自身基础设施指标的内部项目中,我们亲身体验了使用核心 Redis 数据结构处理时间序列用例的局限性和开发工作量。我们认为肯定有更好、更有效的方法。除了上述针对工具集的特定功能外,我们还希望提供开箱即用的二级索引,以便我们可以有效地查询时间序列集合。
在 Redis 中,有两种方法可以在重用现有数据结构的同时使用时间序列:有序集合 (Sorted Sets) 和流 (Streams)。许多文章解释了如何使用 Redis 核心数据结构对时间序列进行建模。下面是我们将在后面的基准测试中用到的一些关键原则。
有序集合存储 值 ,通过它们的 分数 。在时间序列数据的情况下,分数是观察到事件的时间戳。值 重复时间戳,后跟分隔符和实际测量值,例如“<timestamp>:<measurement>”。这样做是因为每个 值 在有序集合中都应该是唯一的。另外,值 持有唯一键的名称,该键存储一个哈希,可以在其中保存给定 时间戳 的更多数据或测量值。
这种方法的缺点
Redis Streams 是最近添加的数据结构(因此目前较少用于时间序列),它比有序集合消耗更少的内存,并且使用 Rax(Radix 树的独立实现)实现。总的来说,与有序集合相比,Redis Streams 提高了插入和读取的性能,但由于它被设计为通用数据结构,仍然缺少时间序列特有的工具集。
这种方法的缺点
在 RedisTimeSeries 中,我们引入了一种新的数据类型,它使用固定大小的内存块存储时间序列样本,并使用与 Redis Streams 相同的 Radix Tree 实现进行索引。使用 Streams,您可以创建一个 capped stream,有效地按数量限制消息数量。在 RedisTimeSeries 中,您可以应用以毫秒为单位的保留策略。这对于时间序列用例更好,因为它们通常只关心给定时间窗口内的数据,而不是固定数量的样本。
如果您想无限期地保留所有原始数据点,您的数据集将随时间线性增长。但是,如果您的用例允许您保留时间上更远的回溯数据时,数据粒度可以更粗,则可以应用降采样。这允许您通过使用给定的聚合函数对给定时间窗口内的原始数据进行聚合来保留更少的历史数据点。RedisTimeSeries 支持使用以下聚合进行降采样:avg(平均值)、sum(总和)、min(最小值)、max(最大值)、range(范围)、count(计数)、first(第一个)和 last(最后一个)。
使用 Redis 的核心数据结构时,您只能通过知道持有时间序列的确切键来检索时间序列。不幸的是,对于许多时间序列用例(例如根因分析或监控),您的应用程序不会知道它正在寻找的确切键。这些用例通常希望查询一组在多个维度上相互关联的时间序列,以提取您所需的见解。您可以使用核心 Redis 数据结构创建自己的二级索引来帮助解决此问题,但这会带来高昂的开发成本,并且需要您管理边缘情况以确保索引的正确性。
RedisTimeSeries 基于您可以添加到每个时间序列的 `字段值` 对(也称为标签)为您执行此索引操作,并可在查询时用于过滤(完整的过滤器列表可在我们的文档中找到)。以下是创建一个带有两个标签(sensor_id 和 area_id 分别是值为 2 和 32 的字段)以及保留窗口为 60,000 毫秒的时间序列的示例
TS.CREATE temperature RETENTION 60000 LABELS sensor_id 2 area_id 32
当您需要查询时间序列时,如果您只关心给定时间间隔内的平均值等信息,流式传输所有原始数据点会非常繁琐。RedisTimeSeries 遵循 Redis 的理念,只传输最低限度所需的数据,以确保最低延迟。下面是使用聚合函数对 5,000 毫秒时间桶进行聚合查询的示例
127.0.0.1:6379> TS.RANGE temperature:3:32 1548149180000 1548149210000 AGGREGATION avg 5000
1) 1) (integer) 1548149180000
2) "26.199999999999999"
2) 1) (integer) 1548149185000
2) "27.399999999999999"
3) 1) (integer) 1548149190000
2) "24.800000000000001"
4) 1) (integer) 1548149195000
2) "23.199999999999999"
5) 1) (integer) 1548149200000
2) "25.199999999999999"
6) 1) (integer) 1548149205000
2) "28"
7) 1) (integer) 1548149210000
2) "20"
RedisTimeSeries 提供了与现有时间序列工具的多项集成。其中一项集成是我们的 Prometheus RedisTimeSeries 适配器,它将您的所有监控指标保存在 RedisTimeSeries 中,同时充分利用整个 Prometheus 生态系统。
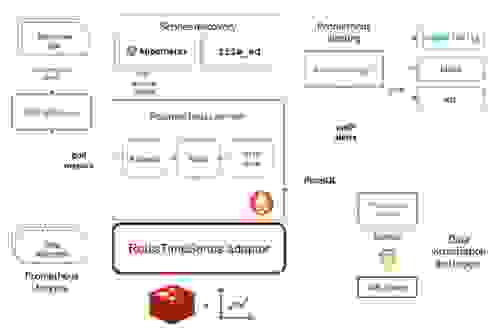
此外,我们还为 Grafana 和 Telegraph 创建了直接集成。此仓库包含 RedisTimeSeries、其远程写入适配器、Prometheus 和 Grafana 的 docker-compose 配置。它还附带了一组数据生成器和预构建的 Grafana 仪表板。
为了展示我们新发布的 GA 版本 RedisTimeSeries 模块的全部功能,我们将其与三种处理时间序列数据的常用技术进行了基准测试。我们使用了客户端-服务器设置,采用两台独立的机器,以比较有序集合、流和 RedisTimeSeries 在数据摄取、查询时间和内存消耗方面的性能。
具体来说,我们的设置包括
Redis Streams 允许您在给定时间戳的一条消息中添加多个字段值对。对于每个设备,我们收集了 10 个指标,这些指标被建模为单个流消息中的 10 个独立字段。
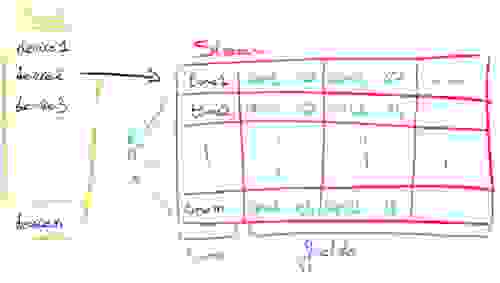
对于有序集合,我们以两种不同的方式建模数据。对于“每个设备一个有序集合”,我们将指标连接起来并用冒号分隔,例如“<timestamp>:<metric1>:<metric2>: … :<metric10>”。
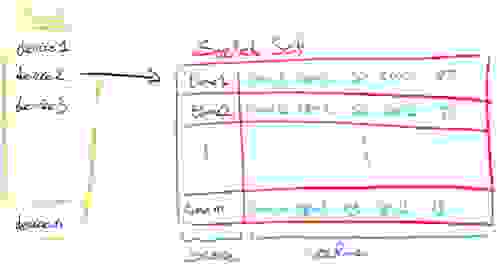
当然,这种方法消耗的内存较少,但在读取时需要更多的 CPU 周期才能获得正确的指标。这也意味着改变每个设备的指标数量并不简单,这也是我们对第二种有序集合方法进行基准测试的原因。在“每个指标一个有序集合”中,我们将每个指标保存在其自己的有序集合中,每个设备有 10 个有序集合。我们以“<timestamp>:<metric>”的格式记录值。
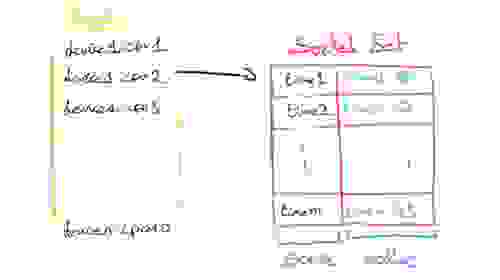
另一种替代方法是创建一个具有唯一键的哈希来跟踪给定时间戳下给定设备的所有测量值,从而对数据进行规范化。然后,该键将成为有序集合中的值。然而,读取时间序列时必须访问许多哈希表会带来巨大的开销,因此我们放弃了这条路径。
在 RedisTimeSeries 中,每个时间序列都包含一个指标。我们选择这种设计是为了保持 Redis 的原则,即大量小键优于少量大键。
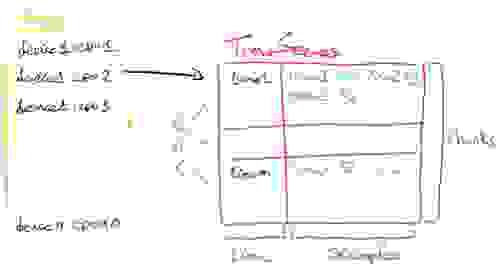
值得注意的是,我们的基准测试没有利用 RedisTimeSeries 开箱即用的二级索引功能。该模块在每个分片中保留一个部分二级索引,并且由于索引继承了其所索引键的相同哈希槽,因此它始终托管在同一分片上。这种方法会使得原生数据结构的建模设置更加复杂,因此为了简单起见,我们决定不在我们的基准测试中包含它。此外,虽然 Redis Enterprise 可以使用代理将 TS.MGET 和 TS.MRANGE 等命令的请求扇出到所有分片并聚合结果,但在基准测试中,我们也没有利用这一优势。
在基准测试的数据摄取部分,我们通过测量每秒可以摄取多少设备的数据来比较这四种方法。我们的客户端有 8 个工作线程,每个线程有 50 个连接,每个请求有一个 50 个命令的管道。
| Redis Streams | RedisTimeSeries | 有序集合 按设备 |
有序集合 按指标 |
|
| 命令 | XADD | TS.MADD | ZADD | ZADD |
| 管道 | 50 | 50 | 50 | 50 |
| 每个请求的指标数 | 5000 | 5000 | 5000 | 500 |
| 键数量 | 4000 | 40000 | 4000 | 40000 |
表 1:每种方法的摄取详情
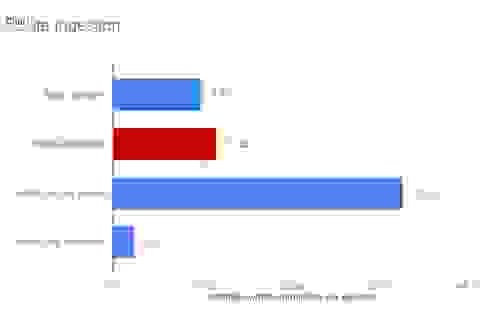
我们所有的摄取操作都在亚毫秒延迟下执行,尽管两者都使用了相同的 Rax 数据结构,但 RedisTimeSeries 方法的吞吐量略高于 Redis Streams。
可以看出,使用有序集合的两种方法产生了截然不同的吞吐量。这表明了针对特定用例始终进行方法原型设计的重要性。正如我们将在查询性能部分看到的那样,每个设备一个有序集合的方法带来了更高的写入吞吐量,但牺牲了查询性能。这取决于您的用例在摄取、查询性能和灵活性(记住我们之前的数据建模说明)之间的权衡。
我们在此基准测试中使用的读取查询查询了单个时间序列,并通过保留每个桶中观察到的最大 CPU 百分比,将其按一小时时间桶进行聚合。我们在查询中考虑的时间范围恰好是一小时,因此返回了一个最大值。对于 RedisTimeSeries,这是开箱即用的功能(如前所述)。
TS.RANGE cpu_usage_user{1340993056} 1451606390000 1451609990000 AGGREGATION max 3600000
对于 Redis Streams 和有序集合方法,我们创建了以下 LUA 脚本。客户端再次有 8 个线程,每个线程 50 个连接。由于我们执行相同的查询,因此只命中了一个分片,并且在所有四种情况下,该分片都达到了 100% 的 CPU 使用率上限。

这就是您可以看到为特定用例拥有专用数据结构以及随之运行的工具箱的真正威力所在。RedisTimeSeries 轻松超越所有其他方法,是唯一实现亚毫秒响应时间的方案。
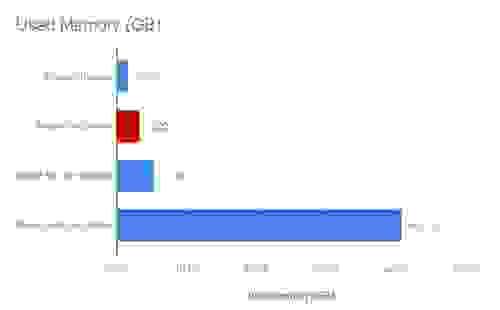
在 Redis Streams 和有序集合方法中,样本都作为字符串存储,而在 RedisTimeSeries 中,它是一个双精度浮点数。在此特定数据集中,我们选择的 CPU 测量值为 0-100 之间的四舍五入整数,因此作为字符串存储时消耗两个字节的内存。然而,在 RedisTimeSeries 中,每个指标都有 64 位精度。
与两种有序集合方法相比,可以看出 RedisTimeSeries 显著降低了内存消耗。考虑到时间序列数据是无界限的,这通常是评估的关键标准——需要保留在内存中的总体数据集大小。Redis Streams 进一步降低了内存消耗,但在需要更高精度(更多位数)时,其内存消耗将等于或高于 RedisTimeSeries。
在选择方法时,您需要了解时间序列用例的摄取速率、查询工作负载、总体数据集大小和内存占用。如我们所见,在 Redis 中有几种对时间序列数据进行建模的方法,每种方法都具有不同的特点。RedisTimeSeries 提供了一种新方法,将时间视为一等公民,并附带了如前所述的开箱即用的时间序列工具包。它将高效的内存使用与卓越的查询性能结合在一起,在数据摄取过程中仅产生很小的开销。这将对时间序列数据进行实时分析的愿望变成了现实。
我们对 RedisTimeSeries 1.0 GA 版本取得的成果感到满意,但这仅仅是个开始。我们非常乐意听取您的反馈,以便将其纳入我们的发展路线图。与此同时,以下是我们接下来计划做的事情清单
我们坚信,所有具有时间序列用例的 Redis 用户都将受益于使用 RedisTimeSeries。如果您仍然不确定并想亲自试用,这里有一个快速入门指南。

