 Redis 8 来了 - 它是开源的
Redis 8 来了 - 它是开源的

视频

Introducing the Redis/Intel Benchmarks Specification for Performance Testing, Profiling, and Analysis
了解更多


英特尔和 Redis 正在合作研究 RedisTimeSeries 压缩/解压缩算法的潜在性能优化。以下是该探索的工作方式。
时间序列数据管理在数据分析中至关重要。许多应用程序需要存储带时间戳的数据,例如股票价格、物联网传感器数据和 CPU 性能指标。根据定义,数据准确性是存储此信息的重要因素,存储和访问的速度也是如此。
RedisTimeSeries 是一个时间序列数据库 (TSDB) 模块,可将大量流数据完全保存在内存中。这使得数据可用于快速处理,这要归功于一种称为 Gorilla 的先进压缩/解压缩算法。 在这篇博文中,我们将回顾 RedisTimeSeries 中 Gorilla 算法的实现,以及进一步优化的潜在思路。虽然目前我们选择保持现有的压缩/解压缩实现不变,但我们希望分享我们在不断改进的共同追求中的探索过程。
Gorilla 算法由 Meta 开发,用于其大规模分布式 TSDB。 Meta 的主要 TSDB 要求之一是至少在内存中维护 26 小时的流数据。它必须可用于快速分析。此外,对于检测事件、异常等,较新的数据通常比旧数据具有更高的价值。这使得压缩率和查询效率至关重要。
Gorilla 专门针对时间序列数据的特征定制了压缩算法。特别是,它的作者认识到顺序数据点在数值上密切相关,并且使用“delta”风格的算法可以以低计算开销实现出色的压缩率。例如,数据点可能会以固定的时间间隔到达——例如,每 30 秒。因此,时间戳之间的增量通常是相同或相似的值。顺序浮点数据值之间的增量预计也密切相关。
作者建议对整数时间戳使用“delta of deltas”算法,对浮点值使用基于 XOR 的 delta 编码。编码的时间戳和数据值一个接一个地插入到内存缓冲区中。有关编码/解码算法的详细信息,请参见 原始论文。
总的来说,Gorilla 算法实现了大约 10 倍的压缩率,其中超过 96% 的时间戳被压缩为单个位,超过 59% 的浮点值被压缩为单个位。
RedisTimeSeries 数据库实现了 Gorilla 算法,用于压缩和解压缩时间序列数据。
它可以更快。(再说一次,当涉及到性能优化时,它总是可以更快!这就是 Redis 的用武之地。)
虽然 Gorilla 实现了出色的压缩率和计算效率,但在某些情况下——例如,在跨时间序列数据库计算过滤操作时——解压缩例程会占用大量时间。例如,在下面的火焰图中,我们看到 decompressChunk 占用了大部分执行时间,在一个实例中高达 85%。
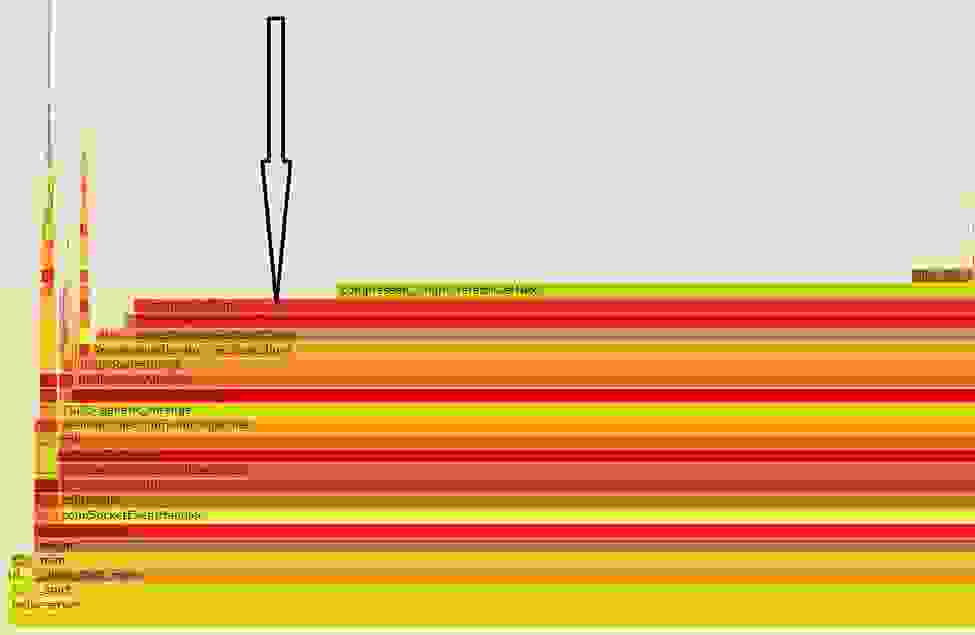
鉴于解压缩占用了大量的 CPU 资源,Redis 与英特尔合作 进行了调查。我们对 RedisTimeSeries 进行了检测,将整数时间戳和浮点值分成两个单独的内存缓冲区。这允许我们独立地研究它们的特征,并独立地对每种数据类型应用潜在的优化。
我们的第一个想法是探索向量化压缩/解压缩计算。 在“加速压缩算法的通用 SIMD 方法”中可以找到关于用于向量化压缩算法的技术的良好概述。 一般来说,为了并发地操作多个元素,必须对用于编码值的位宽施加一些规律性。 这种强加的规律性可能会导致牺牲压缩率。
为了评估,我们测试了在线提供的不同压缩算法的向量化实现,网址为 TurboPFor:最快的整数压缩,使用来自时间序列基准套件 DevOps 用例的输入作为数据。在我们的分析中,我们发现浮点值的解压缩最耗时(整数时间戳的解压缩速度要快得多),因此我们专注于此。我们从数据集中提取了浮点值的跟踪,并使用 TurboPFor 以及我们的 Gorilla 实现对其进行了测试。
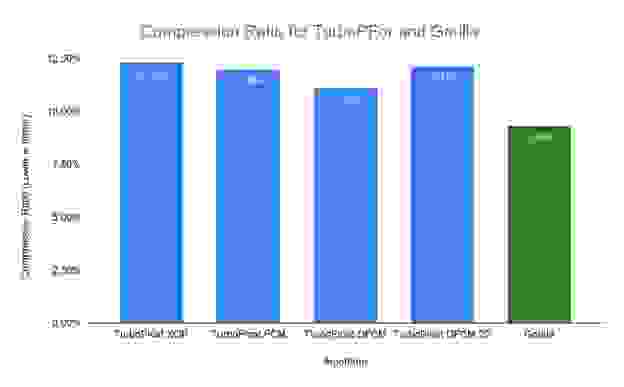
在图 2 中,我们展示了在我们的数据集上,来自 TurboPFor 库的压缩率方面性能最佳的算法。它表明 TurboFloat DFCM 是压缩率方面最好的算法:这些值被压缩到原始值的 11.15%。但是,对于同一数据集,Gorilla 的压缩率仍然明显更好,为 9.3%,即每个 64 位浮点数平均为 6.01 位。
由于 Gorilla 提供的压缩率优于 TurboPFor,因此我们决定保留现有算法,并将注意力转移到进一步微调 Gorilla 实现上。
接下来,我们深入研究数据集中观察到的数据模式,以寻找其他可能的优化的线索。
首先,我们对 RedisTimeSeries 进行了检测,以打印出用于编码 4K 块中每个整数时间戳和浮点值的位数。 大多数时候,整数时间戳被压缩为单个位,这与 Gorilla 论文中的发现一致。 另一方面,用于编码浮点值的位模式更加多样化和不规则。
这些结果使我们得出结论,通过向量化来优化双增量浮点解压缩在性能和代码复杂性方面不会得到回报。基于这种认识,我们决定深入研究其他潜在的优化,这些优化不基于向量化浮点 xor 编码。
我们打印出了测试数据集中的浮点值并分析了它们的特征。 这样做帮助我们发现,在许多情况下(Gorilla 论文中也提到了),浮点值实际上是表示为双精度的整数(例如 72.0、68.0、71.0)。 但是,与时间戳相比,这些整数值不会按顺序增加或减少。
此外,在生成不同值出现频率的直方图后,我们发现只有少量值(少于 128 个)代表了示例数据集中绝大多数观察到的数据点。
基于这些观察,我们认为可以通过结合使用 Gorilla 和字典和/或游程编码来获得更好的性能和/或压缩率。 但是,我们仍然必须使用更广泛的数据集进行进一步分析。
浮点数据可能过度或是一种低效的信息存储方式。 数据通常测量物理量(例如温度),并且传感器具有给定的范围和精度。 即使股票价格的分辨率也为正负一美分。
因此,创建时间序列的另一种方法可能是指示用户指定范围(例如 0-100)和分辨率(例如 0.01)。
外部接口将保持浮点型,但我们可以在内部以最有效的方式(在大小和性能方面)将测量值转换为整数。
根据我们对 Gorilla 和其他快速压缩算法的压缩率的分析,我们的 Gorilla 算法目前是更好的压缩率选择。 我们还探索了典型时间序列数据集的特征,以寻找如何进一步改进 Gorilla 实现的想法。
我们的结论:目前为止,一切顺利。我们决定不更改现有的实现。但是,我们会继续研究不同数据集的特性,并评估增强功能的想法,例如扩展矢量化的使用,以加速 RedisTimeSeries 的数据处理,减少协议的序列化开销,甚至改进我们存储和访问数据结构的方式。
这只是 Redis 正在进行的性能探索的一个例子,这得益于英特尔和 Redis 之间的合作。如果您喜欢我们到目前为止所描述的内容,我们鼓励您查看我们如何扩展 Redis 的能力,以追求核心 Redis 性能回归并提高数据库代码效率,我们在Introducing the Redis/Intel Benchmarks Specification for Performance Testing, Profiling, and Analysis中详细介绍了这一点。

