 Redis 8 来了——并且是开源的
Redis 8 来了——并且是开源的
了解更多

TLDR:我们一直在开发一种将查询转换为线性代数问题的图数据库,其结果是一种可以在亚秒级时间内对数百万个元素执行许多标准操作的架构。
经过近两年的开发,我们今天发布了 RedisGraph v1.0,这是一个重要的里程碑。RedisGraph 是一种图数据库架构,实现为 Redis 模块,使用 GraphBLAS 稀疏矩阵进行内部数据表示和线性代数进行查询执行。它纯粹用 C 实现,并在 Linux 和 OS X 发行版上进行了测试。我们正在使用 Cypher 作为我们的查询语言,并期待与图数据库社区一起努力实现 GQL!
在本博客中,我们将快速概述 RedisGraph 如何使用矩阵表示来解决传统的图形问题,分享一些性能基准,并讨论下一步如何使我们的架构尽可能高效和通用。
矩阵是图形数据的经典编码格式,从令人愉悦的直观邻接矩阵开始:一个正方形表格,每个轴上都有所有节点,并且每个连接的对都有一个值。朴素地实现,这种方法对于模拟现实世界问题的图来说扩展性非常差,因为这些图往往非常稀疏。矩阵的空间和时间复杂度由其维度决定(对于正方形矩阵,为 O(n²)),这使得像邻接表这样的替代方案对于大多数具有扩展要求的实际应用更具吸引力。
对于 RedisGraph,我们采用了 GraphBLAS 库,以获得矩阵表示的优势,同时针对稀疏数据集进行优化。(特别感谢 Tim Davis,他与我们密切合作,尽可能有效地整合他的工作!)
GraphBLAS 以压缩稀疏列 (CSC) 形式编码矩阵,其成本由包含的非零元素的数量决定。总的来说,矩阵的空间复杂度是
(列数 + 1)+ (2 * 非零元素数)
对于密集图,这仍然受 O(n2) 的限制,但对于完整的对角线(单位矩阵),它只有 3n + 1。
这种编码非常节省空间,并且还允许我们将图矩阵视为数学操作数。因此,数据库操作可以作为代数表达式执行,而无需首先将数据从一种形式(如一系列邻接表)中转换出来。
GraphBLAS 接口允许我们的大部分库调用都是直接的数学运算,例如矩阵乘法和转置。这些调用会被延迟评估并在后台进行优化。
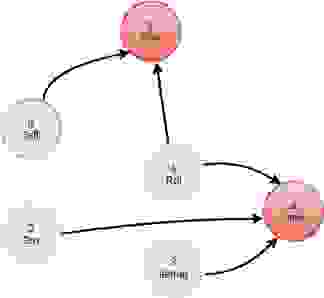
例如,让我们假设一个简单的图,它有 6 个节点,其中 4 个节点的标签是 Person,2 个节点的标签是 Country
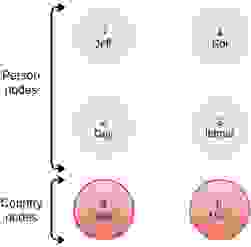
我们将运行的 Cypher 查询是
MATCH (:person {name: 'Jeff'})-[:friend]->(:person)-[:visited]->(:country)
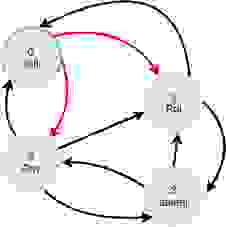
这将找出我的朋友去过哪些国家。该查询将有一个过滤器操作,仅选择具有匹配的 `name` 属性的 `person` 节点,并且我们将不得不遍历两个邻接矩阵,friend 和 visited。
由于 CSC 编码中值的影响最小,我们的邻接矩阵始终代表所有节点 ID。这与用人作为行,国家作为列来表示像 visited 这样的矩阵形成对比。无论在哪种情况下,都会显示相同的关系,但 CSC 方法允许所有矩阵具有相同的维度,其行/列索引描述相同的实体。因此,我们可以将这些矩阵中的任何一个组合在代数表达式中,而无需首先将它们转换为可比较的形式。
此查询的起点将是 `friend` 邻接矩阵
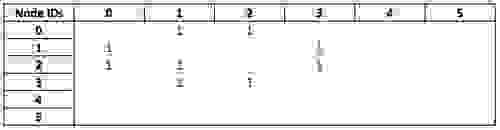
我的节点 ID 为 0,因此该矩阵第一行中的条目表示与我成为朋友的个人的 ID。目前,过滤器是逐个节点应用的,但我们目前正在开发的一种优化是在此阶段将它们应用于矩阵。这将产生一个修改后的邻接矩阵,其中仅表示我的朋友
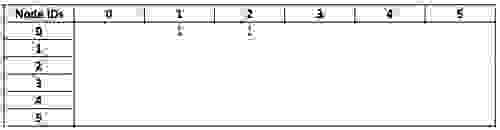
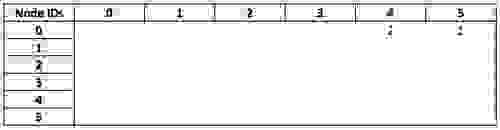
现在我们采用 `visited` 矩阵,它具有相同的维度并以相同的顺序描述所有节点
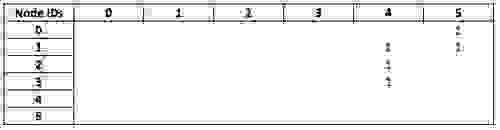
通过将过滤后的 `friend` 矩阵与 `visited` 相乘,我们获得了一个矩阵,该矩阵将我的节点(作为一行)连接到我的朋友访问过的国家/地区(作为列)
(为了空间优化,我们实际上在这里使用布尔矩阵,因此实际上两个条目都将为 1。)
在真实数据集和更复杂的问题上测试数据库的性能已产生可喜的结果。
以下所有值都是在 2016 Macbook Pro (2 GHz i5, 16gb RAM) 上使用 Wikipedia top categories 数据集构建的。生成的图包含 1,791,489 个节点和 28,511,807 条边。
以下是我们取得的性能结果
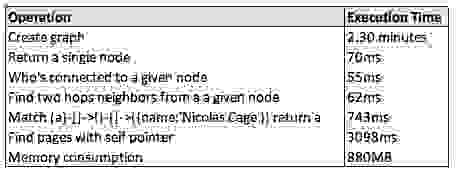
一些注意事项
我们在 RedisGraph 上的开发仍然非常活跃,摆在我们面前的最重要的任务是
顺便说一句,这非常像一个愿望清单! 本着 Redis 的精神,RedisGraph 是一个开源项目,我们随时欢迎贡献者。 如果您有任何意见,或者您有兴趣参与,请随时在 GitHub 上与我们联系。

