 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多

在整个组织中管理大型的、预训练的预测模型,并确保生产中使用的是相同的版本,这在 AI/机器学习领域快速变化的节奏下可能是一个挑战。 在这里,我们有一种方法,演示如何自动构建、存储和部署来自托管在 Redis 上的远程机器学习数据存储的预测模型。 这种方法侧重于展示如何使用 DevOps CI/CD 工件管道,使用 Jupyter IPython 笔记本、配套的命令行自动化版本和管理工具来构建和管理机器学习模型工件,以帮助管理团队中的工件。 通过为机器学习构建工作流程利用 DevOps,您可以轻松地管理智能环境中的模型部署。
一般来说,机器学习工作流程共享以下创建预测模型的常见步骤
1. 定义数据集
2. 将数据集切分成训练集和测试集
3. 构建你的机器学习算法模型
4. 训练模型
5. 测试模型
我们想分享如何在 服务器 API 下自动化机器学习管道中的这些常见步骤,该 API 在完成后创建模型工件。 工件是包含模型分析、准确性、预测和二进制模型对象的字典。 一旦创建了工件,它就可以压缩为 pickle 序列化对象,并上传到可配置的 S3 位置或另一个持久存储位置。 这篇文章也是一个演示,展示如何使用 伪工厂设计机器学习 API,以抽象每个步骤的工作方式和底层机器学习模型实现。 这种方法使团队可以专注于提高模型的预测准确性、改进数据集的特征、在整个组织中共享模型、帮助进行模型评估,并将预训练模型部署到新环境中,以实现自动化和实时智能服务层,这些服务层需要进行实时预测或预报。
以下是使用由 Redis 和 S3 工件骨干支持的机器学习数据存储的工作流程
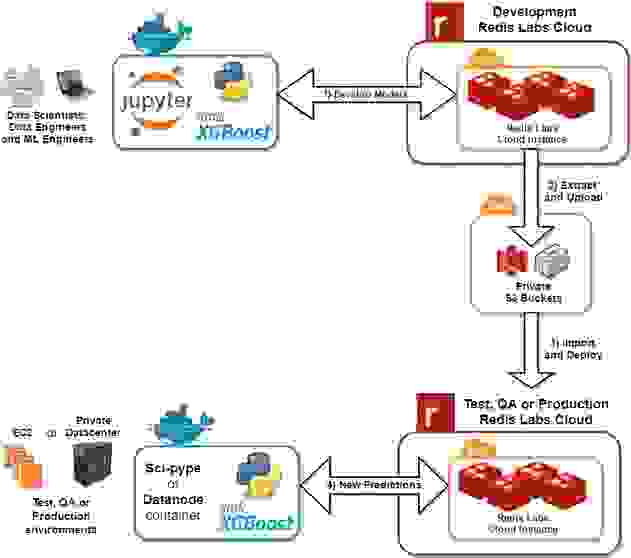
此工作流程旨在帮助找到高度预测性的模型,因为它使用一个 API,该 API 可以扩展昂贵的任务(例如构建、学习、训练和测试模型),并使用 Redis 缓存和 S3 骨干(用于存档)原生管理机器学习模型。 正如企业软件领域的 DevOps 一样,自动化构建工作流程使您的组织能够专注于重要的事情,例如:找到最具预测性的模型、定义高质量的数据集和测试新设计的特征。
要继续阅读 Jay Johnson 的完整博客,请访问 Levvel 网站。

