 Redis 8 已推出——并且它是开源的
Redis 8 已推出——并且它是开源的
了解更多



The Room 的使命是将世界顶尖人才与有意义的机会连接起来。The Room 被设想为一个技术驱动、社区中心化的平台,旨在帮助组织大规模快速找到高质量、经过验证的人才,其系统将托管数千万会员,并在全球拥有业务。
技术挑战的核心是一个在数学上困难的实体匹配问题。系统中的每个实体——个人、组织、机会和内容——都必须以高准确性、相关性、上下文敏感性和及时性与其他实体进行匹配。应用程序存在此问题的多个实例。
经过实验,The Room 的 ML 团队确定了一种方法,即使用描述实体的原始文本数据的向量空间嵌入,并结合向量相似度匹配和不断演变的业务逻辑来呈现相似实体。在测试实现时,发现核心向量相似度计算是算法的计算和内存需求的主要驱动因素。使用 Redis 基于最近邻向量查找的高性能键检索功能,团队能够在核心相似度计算循环中实现超过 15 倍的性能提升,且没有内存开销。反过来,这为增加算法的复杂性并将其实时交付创造了空间。
数据总体流如图 1 所示。虽然相当标准,但关键挑战是在团队规模小、时间紧迫且需要灵活性的情况下建立整个生产系统。
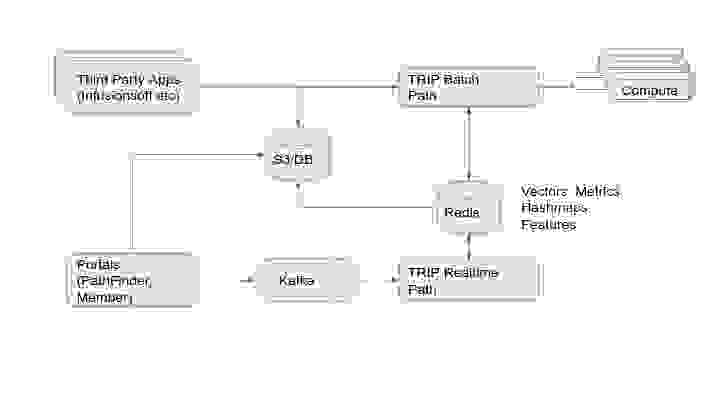
Scribble Data 的 Enrich 特征商店及其应用程序为 The Room 智能平台(负责实体匹配)的实现提供了总体框架。Enrich 处理了与大约 15 个数据源的集成、数据质量、批量和流式特征工程(包括向量化),以及与 Redis 等内存数据库后端的集成、目录和合规性。Enrich 的管道和编排也用于建模,未来版本的实现将使用独立的模型数据库,如 MLFlow。
The Room 实体匹配引擎早期版本匹配代码的性能分析表明,超过 95% 的时间和 90% 的内存消耗花在了向量相似度计算上。这种资源密集性暗示需要计算分布和繁琐的优化。三个主要挑战是:
此外,必须针对以下关键约束进行优化:
Redis 提供了一个向量相似度功能的私有预览版本,并利用 RedisGears 来支持使用高性能向量相似度查找进行键检索,以展示其功能。接口非常简单,包括使用相似度匹配进行存储和查找,并且集成直观。支持余弦相似度和欧几里得距离度量,以在给定查询向量的情况下查找存储在 Redis 中的 k 个最近邻 (k-NN) 向量。独立的测试表明,top-k 最接近匹配的检索时间在毫秒级以下,并且在大范围的向量数量下,持续时间几乎恒定。当前的测试实现有一些限制,例如只支持固定长度的向量,以及匹配存储在 Redis 中的所有向量的能力。预计生产版本将解决这些问题。
The Room 的实体匹配问题被建模为表示实体的向量的 k 最近邻 (k-NN) 检索。候选向量 (N) 的数量很大,预计会快速增长。每个向量的维度在几千量级。测试只关注应用程序中核心相似度计算部分,报告的加速是基于此。
测试了三种方法
对于上述方法 (1) 和 (2),对得分进行了键排序,以获取 top-k 相似候选向量的索引。测试了各种 N 和 k 值。所有三种方法都使用了相同的数据集。结果如表 1 所示。
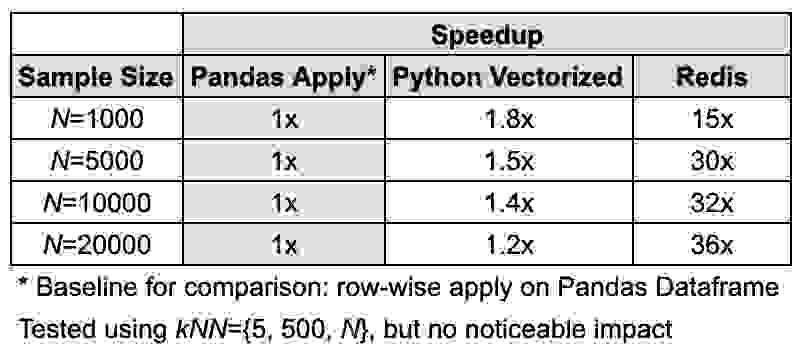
我们看到了 top-k 向量检索性能持续的 15 倍加速。数据量越大,加速效果越明显。我们的假设是,这种加速是由于消除了 Python 和 Pandas 在计算和内存方面的开销,并且这种加速在生产中可以持续获得。
在 The Room 使用 Redis 功能有很多价值主张
Redis 的低延迟和高性能向量相似度计算与 Scribble Data 的 Enrich 特征商店集成,正被扩展以解决其他问题。除了作为服务在线特征的数据存储,Redis Enterprise 还在评估两个近期问题,包括使用图谱识别机会和使用流处理实时事件。随着 The Room 开发最先进的低延迟数据应用程序以服务其会员和内部员工,其自身的数据智能平台也受益于这种集成。
The Room
Peter Swaniker,The Room 首席技术官
Scribble Data
Achint Thomas,Scribble Data 数据架构师
The Room 正在招聘数据科学家和数据工程师!更多信息请访问https://www.theroom.com/careers/
了解更多关于 Enrich 特征商店的信息,请访问www.scribbledata.io/product,开始使用 Redis 进行开发,请访问/learn/,包括使用 RedisAI 进行实时服务,请访问/modules/redis-ai/。

