Redis 8 来了—而且是开源的
Redis 8 来了—而且是开源的
了解更多

作为 Redis Cloud 的提供商,我们一直在测试 Redis 和 AWS 的不同配置和选项,以帮助 Redis 社区获得最佳性能。 本周,我们决定找出 fork 时间如何影响各种 AWS 平台和 Redis 数据集大小。 Redis 使用 Linux fork 和 COW(写时复制) 来生成时间点快照,或使用后台保存进程重写仅追加文件 (AOF)。 Fork 在大多数类 Unix 系统中是一项昂贵的操作,因为它涉及分配和复制大量内存对象(请参阅 此处 获取更多详细信息)。 此外,Xen 平台上 fork 操作的延迟似乎比其他虚拟化平台耗时得多(如 此处 所讨论的)。 由于 fork 操作在主 Redis 线程上运行(并且 Redis 架构是单线程的),因此 fork 操作花费的时间越长,其他 Redis 操作延迟的时间就越长。 如果考虑到即使在适度的机器上,Redis 每秒也可以处理 5 万到 10 万个操作,那么几秒钟的延迟可能意味着减慢了数十万个操作,这可能会对您的应用程序造成严重的稳定性问题。 对于 AWS 上的 Redis 用户来说,这个问题是一个现实生活中的限制,因为大多数 AWS 实例都基于 Xen。 我们的测试场景简而言之如下 — 我们在以下平台上运行了 Redis(版本 2.4.17)
可以在本文末尾找到测试设置的更详细描述。 以下是我们发现的关于 Fork 时间的信息:
| 实例类型 | 内存限制 | 已用内存 | 内存使用率 (%) | Fork 时间 |
| m1.small | 1.7 GB | 1.22 GB | 71.76% | 0.76 秒 |
| m1.large | 7.5 GB | 5.75 GB | 76.67% | 1.98 秒 |
| m1.xlarge | 15 GB | 11.46 GB | 76.40% | 3.46 秒 |
| m2.xlarge | 34 GB | 24.8 GB | 72.94% | 5.67 秒 |
| cc1.4xlarge | 23. GB | 18.4 GB | 80.00% | 0.22 秒 |
每 GB 内存的 Fork 时间
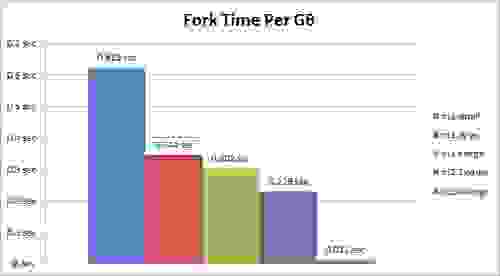
正如您所见,实例处理能力与 fork 操作的执行时间之间存在很强的相关性。 此外,Xen HVM 实例实现了比常规 Xen 虚拟机监控程序实例低得多的延迟。 那么,AWS 上的 Redis 用户是否应该将其数据集迁移到集群计算实例? 不一定。 原因如下
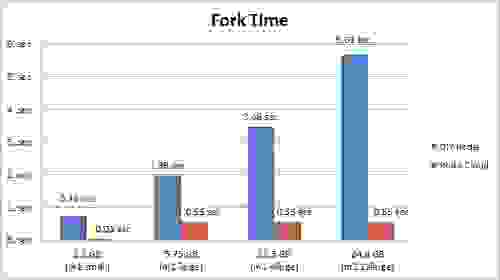
Fork 时间和 Redis Cloud 我们在 Redis Cloud 上以类似的场景测试了 fork 时间,并将结果与自行构建 (DIY) 方法中的相应实例的结果进行了比较。 这是我们发现的
每 GB 内存的 Fork 时间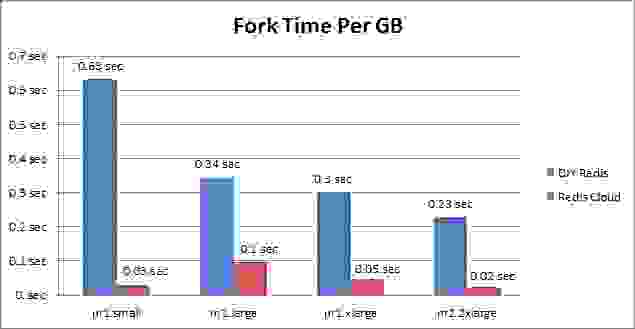
您可以在此处看到,Redis Cloud 的 fork 时间明显低于常规 Xen 虚拟机监控程序平台。 此外,当数据集大小增长时,每 GB 的 fork 时间会下降。 Redis Cloud 上的 Fork 时间略高于 Xen HVM(cc1.4xlarge 实例)的 fork 时间 - 对于大约 1GB 的小型数据集,它是 0.03 秒,而 Xen HVM 的 fork 时间是 0.008 秒。 但是,由于数据集的大小与您的应用程序访问 Redis 的速率可能存在相关性,因此使用 Redis Cloud 时延迟的请求数量应该很小。 对于更大的数据集,Redis Cloud 的 fork 时间为每 GB 0.03 秒,而 Xen HVM 的 fork 时间为每 GB 0.01 秒。 尽管如此,我们仍然更喜欢在 Redis Cloud 中使用 m2.2xlarge 和 m2.4xlarge 实例,而不是 cc1.4xlarge 和 cc2.8xlarge 实例,原因如下
Redis Cloud 如何最大限度地减少 fork 时间? Redis Cloud 应用多种机制和技术来保持高性能
结论 我们在此测试中验证了 AWS 标准 Xen 虚拟机监控程序实例上的 fork 进程会导致 Redis 操作(以及因此您的应用程序性能)的显着延迟。 每 GB 的 Fork 时间在更强大的实例上有所改善,但在我们看来仍然是不可接受的。 虽然在使用 AWS 集群计算实例时实际上消除了 fork 时间,但这些实例非常昂贵,并且没有针对 Redis 操作进行优化。 Redis Cloud 以经济实惠的基础设施价格提供最短的 fork 时间,并且当数据集大小增长时,我们的 fork 时间会进一步下降。 基准测试设置 对于那些想了解更多关于我们的基准测试的人,这里有一些关于我们使用的资源的详细信息
这是我们生成负载的设置