 Redis 8 来了——它是开源的
Redis 8 来了——它是开源的
了解更多

人工智能 (AI) 的繁荣始于人们意识到可以利用 GPU 技术比等待通用 CPU 花费数天完成一个模型训练周期更快地训练深度学习模型。(有关更多详细信息,请查看这篇Quora 上的信息丰富帖文。)
自 2016 年 NVIDIA、英特尔等 GPU 制造商创造出首批 AI 优化型 GPU 以来,大多数 AI 开发都与如何训练模型使其尽可能准确和具有预测性有关。2017 年末,许多企业和初创公司开始思考如何将机器学习/深度学习 (ML/DL) 投入生产。像 MLFlow 和 Kubeflow 这样成功的开源项目旨在通过管理整个 AI 生命周期,将 AI 从研究和科学阶段推进到解决现实世界问题。他们引入了类似的方法来管理机器学习管道生命周期,如下图所示,该图取自 Semi Koen 的 Not yet another article on Machine Learning! 博客):
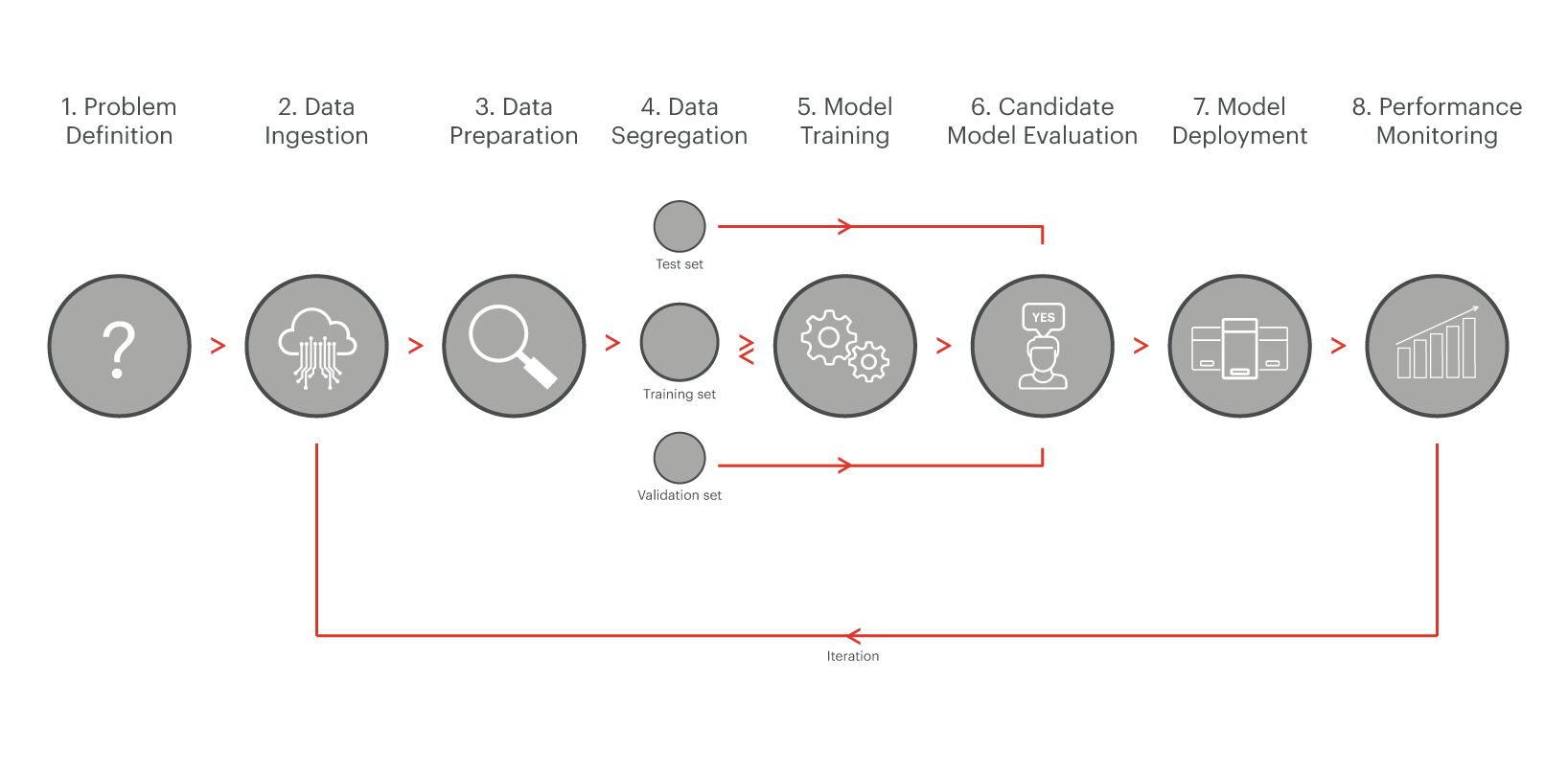
从宏观上看,任何 ML 管道中最关键的步骤之一称为 AI 服务,这项任务通常由 AI 推理引擎执行。AI 推理引擎负责上图中的模型部署和性能监控步骤,代表了一个全新的领域,最终将决定应用程序能否利用 AI 技术提高运营效率并解决实际业务问题。
我们一直与 Redis Enterprise 客户合作,以更好地了解他们在将 AI 投入生产中面临的挑战,更具体地说,是他们对 AI 推理引擎的架构要求。经过与许多客户的多次互动,我们整理出了这份列表
Redis 的首要使命是帮助我们的客户和用户以毫秒级的速度解决复杂问题。因此,让我们来看看列表中的第一个挑战——快速的端到端推理/服务——并看看在将 AI 添加到生产部署技术栈时如何实现该目标。
1. 新的 AI 推理芯片组可以提供帮助,但只解决了部分问题
已经有很多报道(例如这里和这里)关于芯片组供应商正努力在 2021 年前提供高度优化的推理芯片组。这些芯片组旨在通过增加处理的并行度和内存带宽来加速视频、音频、增强现实/虚拟现实等推理处理。但仅加速事务链中的 AI 处理部分可能只会带来有限的收益,因为在许多情况下,AI 平台应该用分散在多个数据源中的参考数据进行丰富。检索参考数据并用其丰富 AI 的过程可能比 AI 处理本身慢几个数量级,如下面的事务评分示例所示:
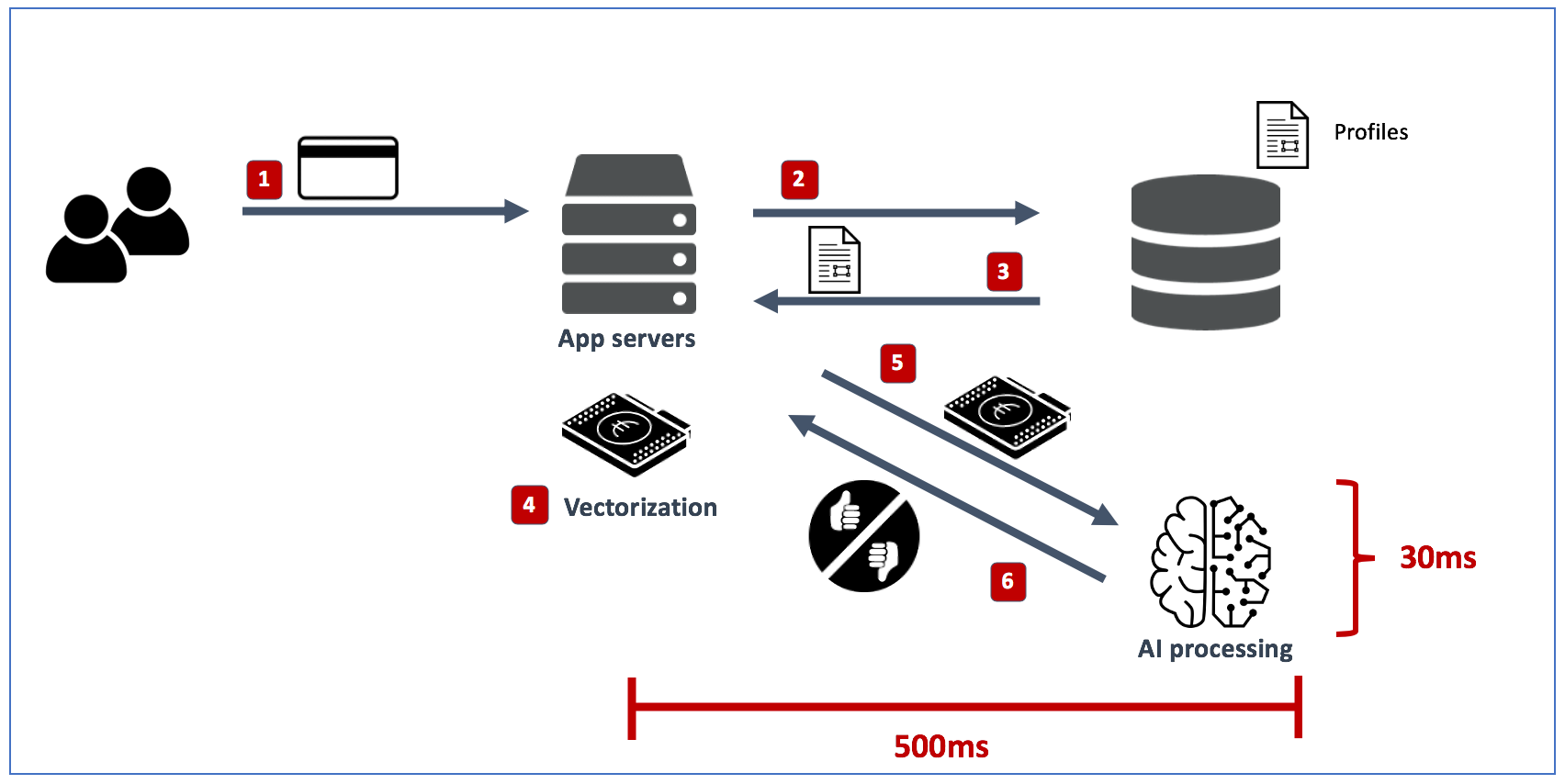
让我们看看这里发生了什么
如上所示,即使我们将 AI 处理速度提高一个数量级(从 30ms 到 3ms),数据中心内部的端到端交易时间仍约为 500ms,因为 AI 处理占总交易时间的比例不到 10%。
因此,对于事务评分、推荐引擎、广告竞价、在线定价、欺诈检测等许多用例,AI 推理时间主要与将参考数据带入并准备送至 AI 处理引擎有关,新的推理芯片组只能轻微改善端到端交易时间。
2. 在数据所在之处运行您的 AI 推理平台
由于延迟敏感应用的参考数据大多存储在数据库中,因此在数据所在之处(即数据库中)运行 AI 推理引擎是有意义的。话虽如此,这种方法也存在一些挑战:
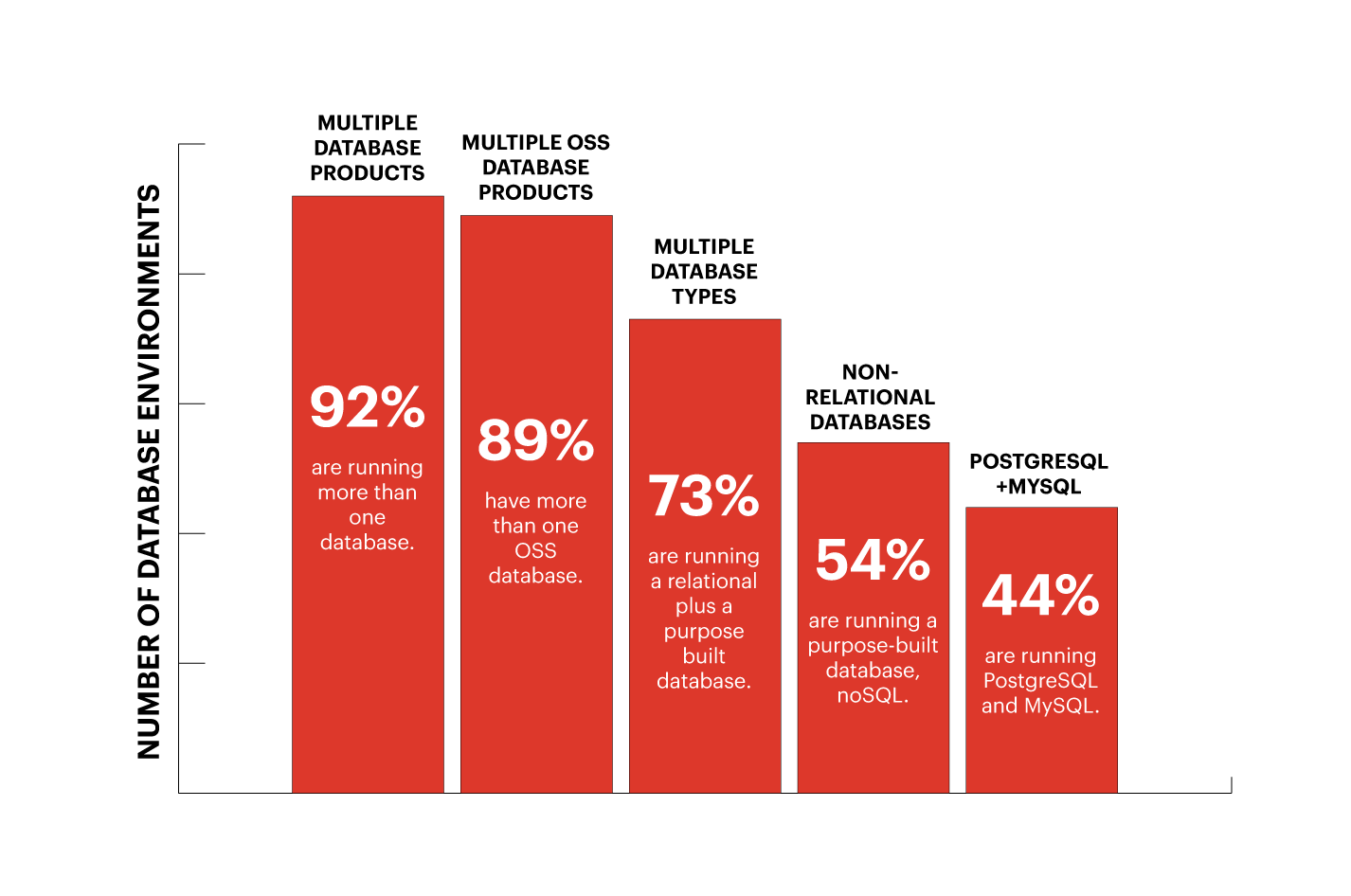
1. 在应用数据分散在多个数据库中的情况下,AI 推理引擎应该在哪个数据库上运行?即使我们忽略部署的复杂性并决定在每个数据库上运行 AI 推理引擎的副本,如何处理单个应用事务需要从多个数据库获取参考数据的情况?最近来自 Percona 的一项调查很好地展示了多个数据库如何代表大多数应用的部署架构
2. 为满足低延迟 AI 推理的要求,参考数据应存储在内存中。许多人认为,在现有数据库之上添加一个缓存层可以轻松解决这个问题。但缓存有其自身的局限性。例如,当应用在缓存中找不到数据,被迫从基于磁盘的数据库中查询数据,然后用最新数据更新缓存时,会发生什么(即缓存未命中事件)?在这种情况下,违反端到端响应时间 SLA 的可能性非常高。如何确保数据库更新与缓存同步并免受一致性问题的影响?最后,如何确保缓存系统具有与数据库相同的弹性水平?否则,您的应用正常运行时间和 SLA 将由链中最薄弱的环节——您的缓存系统决定。
为了克服维护单独缓存层的需要,我们认为部署 AI 推理引擎的正确架构选择是内存数据库。这避免了缓存未命中事件期间的问题,并克服了数据同步问题。内存数据库应该能够支持多种数据模型,使 AI 推理引擎尽可能接近每种类型的参考数据,并避免需要在多个数据库和缓存系统之间构建高弹性。
3. 使用专用的数据库内无服务器平台
很容易想象,延迟敏感的应用如何通过在具有多种数据模型的内存数据库中运行 AI 推理引擎来解决这些性能挑战。 但这个难题仍缺少一环:即使所有内容都位于同一个集群中,并且可以快速访问共享内存,谁将负责从多个数据源收集参考数据、处理它,并将其提供给 AI 推理引擎,同时最大限度地减少端到端延迟?
无服务器平台,例如AWS Lambda,通常用于处理来自多个数据源的数据。通用无服务器平台用于 AI 推理的问题在于,用户无法控制代码实际执行的位置。这导致了一个关键的设计缺陷:您的 AI 推理引擎部署在尽可能靠近您的数据所在之处,即您的数据库内部,但为 AI 推理准备数据的无服务器平台却在数据库外部运行。这打破了将 AI 服务更靠近数据的概念,并导致了之前讨论的将 AI 推理引擎部署在数据库外部时遇到的相同延迟问题。
解决这个问题只有一个办法:一个专用的无服务器平台,它是数据库架构的一部分,并在存储您的数据和 AI 推理引擎的同一共享集群内存中运行。
回到事务评分示例,如果我们应用这些原则,解决方案可以看起来如此快速(和简单):

将 AI 投入生产会带来训练阶段不存在的新挑战。解决这些问题需要许多架构决策,特别是当延迟敏感的应用需要在每个事务流中集成 AI 功能时。在与已经在生产环境中运行 AI 的 Redis 客户的交流中,我们发现,在许多情况下,大部分事务时间花费在将参考数据引入并准备送至 AI 推理引擎上,而不是在 AI 处理本身。
因此,我们提出了一种新的 AI 推理引擎架构,旨在通过在内置支持多种数据模型的内存数据库中运行系统来解决此问题,并使用专用的、低延迟的数据库内无服务器平台来查询、准备数据,然后将其送至 AI 推理引擎。一旦具备了这些要素,延迟敏感的应用就可以受益于在专用推理芯片组上运行 AI,因为 AI 处理占用了整个事务时间中更重要的部分。
最后,将 AI 添加到您的生产部署技术栈中应该非常谨慎。我们认为,依赖延迟敏感应用的企业应遵循这些建议,以防止 AI 推理引擎的缓慢导致用户体验下降。在 AI 的早期阶段,通用 CPU 的缓慢性能给训练阶段的开发者和研究人员带来了阻碍。随着我们着手将更多 AI 应用部署到生产环境,构建一个强大的 AI 推理引擎最终将决定在即将到来的 AI 繁荣中谁是赢家,谁是输家。

