 Redis 8 已发布——它是开源的
Redis 8 已发布——它是开源的
了解更多

我们看到检索增强生成 (RAG) 正成为需要访问私有数据的生成式 AI 应用事实上的标准架构。然而,有些人可能会想知道为什么实时访问这些数据很重要。答案很简单:您不希望在向堆栈中添加 AI 时,应用会变慢。
那么,什么是快速应用?Paul Buchheit(Gmail 的创建者)提出了100 毫秒规则。它规定每次交互都应该快于 100 毫秒。为什么?100 毫秒是“交互感觉即时”的阈值。
让我们检查一下典型的基于 RAG 的架构是什么样的,以及每个组件当前的延迟边界以及预期的端到端延迟。
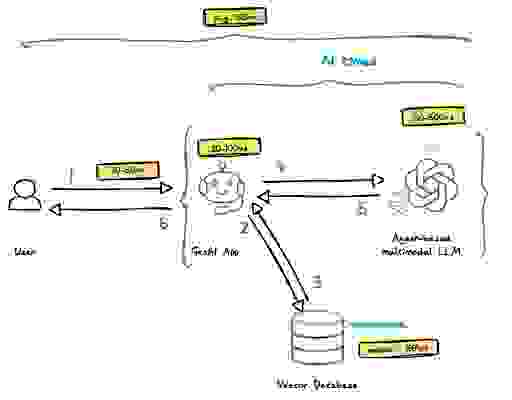
基于此分析,使用上述架构构建的生成式 AI 应用预计端到端响应时间平均为 1,513 毫秒(或 1.5 秒)。这意味着您很可能会在几次交互后失去终端用户的兴趣。
要构建一个更接近 100 毫秒规则体验的实时生成式 AI 应用,您需要重新思考您的数据架构。
为了应对上述挑战,Redis 为 AI 提供了三个主要的数据存储功能,这将使实时 RAG 成为可能。
即使在“生成式 AI”一词被创造之前,Redis 就已经支持向量数据类型和向量搜索功能。Redis 向量搜索算法使用高效的内存数据结构和专用搜索引擎,从而使搜索速度提高多达 50 倍(我们将很快发布全面的基准测试结果),并且文档检索速度提高两个数量级。本文稍后将展示实时向量搜索如何显著改善端到端用户体验。
Redis(以及通常的)传统缓存技术使用关键字匹配,这难以捕捉 LLM 服务相似查询之间的语义相似性,导致命中率非常低。使用现有缓存,我们无法检测到“给我推荐一部喜剧电影”和“推荐一部有趣的电影”之间的语义相似性,导致缓存未命中。语义缓存超越了精确匹配:它使用智能算法来理解查询的含义。即使措辞不同,缓存也能识别它是否在上下文上与之前的查询相似,并返回相应的响应(如果存在)。根据最近的一项研究,31% 的 LLM 查询可以被缓存(换句话说,31% 的查询是上下文可重复的),这可以在 dramatic地降低 LLM 成本的同时,显著改善基于 RAG 架构运行的生成式 AI 应用的响应时间。
您可以将语义缓存视为 LLM 的新缓存。利用向量搜索,语义缓存可以在性能和部署成本方面带来显著优势,我们将在以下章节中解释。
LLM 记忆是 LLM 与特定用户之间所有先前交互的记录;可以将其视为 LLM 的会话存储,只不过它也可以记录跨不同用户会话的信息。使用现有 Redis 数据结构和向量搜索实现,LLM 记忆由于多种原因而具有令人难以置信的价值。
没有 LLM 记忆
用户:“我计划去意大利旅行。有哪些有趣的地方可以参观?”
LLM:“意大利有很多美丽的城市!以下是一些热门旅游目的地:罗马、佛罗伦萨、威尼斯……”
有了 LLM 记忆
用户:“我计划去意大利旅行。我对艺术和历史感兴趣,不太喜欢拥挤的地方。”(假设这是对话的第一回合)
LLM:“既然您对艺术和历史感兴趣,那去佛罗伦萨怎么样?它以文艺复兴时期的艺术和建筑闻名。”(LLM 利用对话历史来识别用户偏好并建议相关地点)
用户:“听起来不错!有没有什么博物馆不容错过?”
LLM(引用对话历史):“对于佛罗伦萨的艺术爱好者来说,乌菲齐美术馆和学院美术馆是必去之地。”(LLM 利用对话历史来理解用户在旅行背景下的特定兴趣)
在此示例中,LLM 记忆(或对话历史)允许 LLM 根据用户的初始陈述个性化其响应。它避免了通用推荐,并根据用户表达的兴趣定制其建议,从而带来更有帮助和更具吸引力的用户体验。
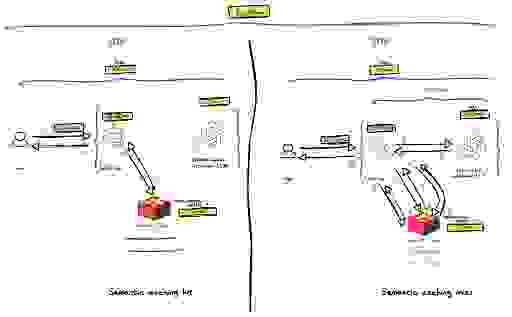
要解释使用 Redis 的 AI 功能实现的实时 RAG,没有什么比图表和简短解释更好的了。
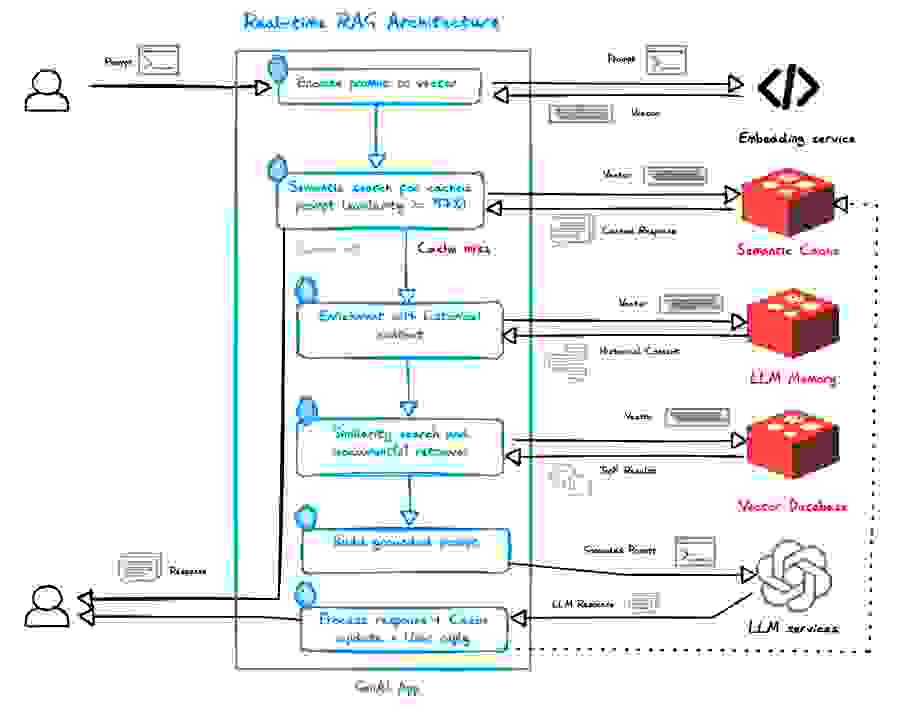
我们应该考虑两种情况:
为了了解实时 RAG 应用的端到端性能,让我们分析每种情况。
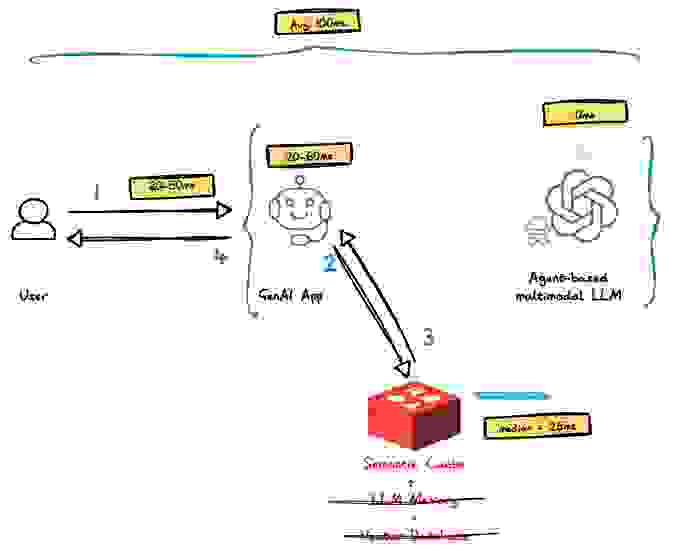
如上图所示,在这种情况下实际只涉及两个组件:
基于 Redis 的 RAG 架构的平均端到端响应时间为 389 毫秒,比非实时 RAG 架构快约 3.2 倍,并且更接近 Paul Buchheit 的 100 毫秒规则。这使得现有和新的应用可以在其堆栈中运行 LLM 组件,而性能影响最小,甚至没有影响。
除了确保您的快速应用保持快速外,基于 Redis 的实时 RAG 架构还提供其他优势:
这篇博客分析了基于 RAG 架构的响应时间,并解释了 Redis 如何在复杂、快速变化的 LLM 环境中提供实时终端用户体验。如果您想尝试此处讨论的所有内容,我们推荐 Redis Vector Library (RedisVL),一个基于 Python 的 AI 应用客户端,它利用 Redis 的功能实现实时 RAG(语义缓存、LLM 记忆和向量数据库)。RedisVL 可与您的 Redis Cloud 实例或您自行部署的 Redis Stack 一起使用。
在本附录中,您将找到我们如何计算 RAG(实时和非实时)端到端响应时间的详细信息。它基于我们进行并将很快发布的全面基准测试,该测试跨越了四种类型的向量数据集:
一旦基准测试发布,将提供更多关于这些数据集的信息。
对于非实时 RAG,我们平均了所有基于磁盘的数据库(专用和通用)的结果。由于数据严重倾斜,我们取了四组不同测试和所有被测试供应商的归一化中位数。
| 组件 | 延迟 |
| 网络往返 | (20+50)/2 = 35ms |
| LLM | (50+500)/2 = 275ms |
| 生成式 AI 应用 *假设未调用其他服务时为 20ms,否则为 100ms | (20+100)/2=60ms |
| 向量数据库 *假设一次向量/混合搜索 + 10 个文档 | 一次向量搜索查询(我们取了低负载和高负载下的中位数) – 63ms;10x 文档检索 – 10x50ms = 500ms;总计 – 563ms |
| 基于代理的架构假设 1/3 的 LLM 调用触发代理处理,这将触发 LLM 的应用调用以及数据检索和 LLM 调用的另一次迭代。 | 33% x (LLM + 应用 + 向量数据库) |
| 总计 | 35 + {275+60+563}⅔ + {275+60+563}2*⅓ = 1232 |
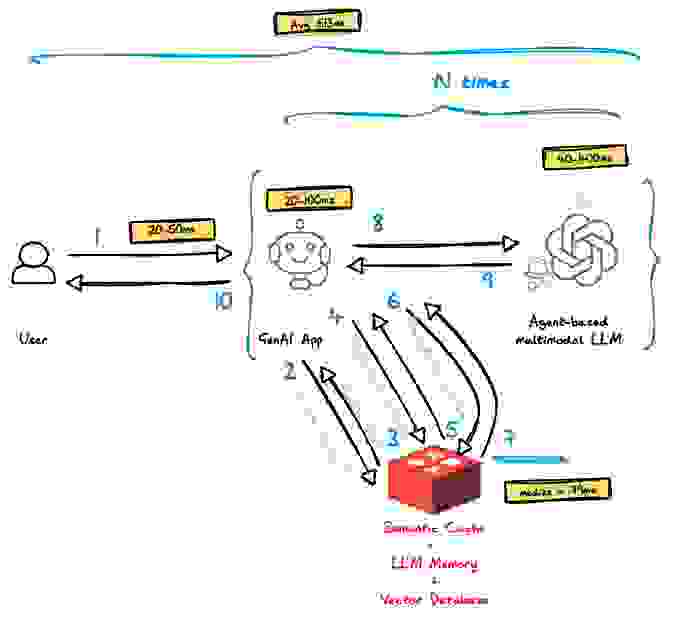
对于实时 RAG,我们考察了两种情况:缓存命中(使用语义缓存)和缓存未命中。根据这项研究,我们计算了加权平均值,假设 30% 的查询会命中缓存(70% 未命中)。我们取了基准测试中所有被测试数据集的 Redis 中位数延迟。
| 组件 | 延迟 |
| 最佳情况 | |
| 网络往返 | (20+50)/2 = 35ms |
| 生成式 AI 应用 *假设缓存命中将导致应用处理时间减少 33% | 40ms |
| Redis 语义缓存 | 一次向量搜索查询(我们取了低负载和高负载下的中位数) – 24.6ms;1x 文档检索 – 1×0.5ms;总计 – 25ms |
| 总计 | 35+40+25 = 100ms |
| 组件 | 延迟 |
| 最佳情况 | |
| 网络往返 | 35ms |
| LLM *基于历史上下文,我们假设由于更短、更准确、更相关的提示(少得多 token),LLM 处理将提高 25% | (40+400)/2 =220ms |
| 生成式 AI 应用 *假设未调用其他服务时为 20ms,否则为 100ms | (20+100)/2=60ms |
| Redis | 语义缓存未命中 – 24.6ms;LLM 记忆搜索 (24.6ms) + 5 次上下文检索 (5x 0.5ms ) = 27.1ms;向量搜索 (24.6ms) + 5 次上下文检索 (5x 0.5ms ) = 27.1ms;总计 – 24.6+27.1+27.1 = 79ms |
| 基于代理的架构假设 1/3 的 LLM 调用触发代理处理,这将触发 LLM 的应用调用以及数据检索和 LLM 调用的另一次迭代。 | 33% x (LLM + 应用 + Redis) |
| 总计 | 35 + {220+60+79}⅔ + {220+60+79}2*⅓ = 513ms |
缓存命中和未命中的加权平均值计算如下:30% * 100ms + 70% * 513ms = 389ms

