 Redis 8 已发布,并且它是开源的
Redis 8 已发布,并且它是开源的
了解更多

高效地存储和访问数据是一个日益突出的问题。向量数据库已成为数据管理和人工智能应用领域的关键技术,在现代计算中发挥着重要作用。与传统的关系型数据库不同,向量数据库旨在高效处理和检索图像、视频和音频等复杂数据类型的向量嵌入。这使得它们特别适用于高级搜索功能和人工智能驱动的数据分析。但是,什么是向量嵌入?它们为何如此有用?以及何时应该使用向量数据库?
传统上,当人们想到“数据”时,会想到电子表格和图表。这就是我们现在所说的结构化数据,而它仅占我们如今可访问数据的一小部分。这类数据非常适合传统数据库。但是,像图像和博客文章这样的所有非结构化数据,没有整洁的表格列和行,如何才能最好地存储它们?
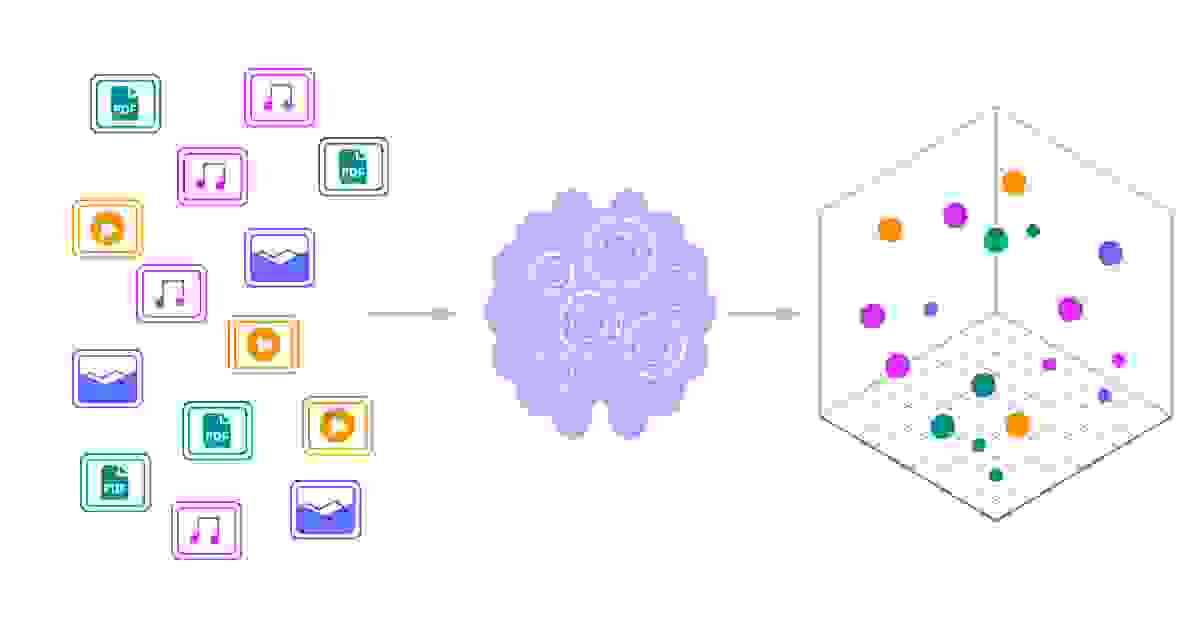
向量数据库正是为此目的而设计的一种数据库:它不仅存储图像和博客文章等非结构化数据,还存储这些项的向量嵌入。通过称为向量化的过程,我们可以将复杂的高维非结构化数据转换为低维的数值形式,捕获数据的本质,然后存储每个向量。这些向量嵌入捕获了它们所代表的任何数据的大量信息。向量化过程还会规范化您的数据,这意味着您存储的每个向量都将具有相同的维度。
它们处理大规模数据集、提供快速准确的向量搜索以及与现有技术集成的能力,使其成为旨在利用 AI 力量的企业和研究人员的基石。
向量数据库旨在存储向量数据。但是向量数据不是可以随意捏造的,它是通过机器学习生成的。有许多机器学习模型可以将非结构化数据转换为向量嵌入;有些是用于处理描述和博客文章等文本的大型语言模型,而另一些则是用于为图像和视频创建向量嵌入的视觉模型。
向量数据库经过优化,可存储这些向量,并允许用户以传统数据库无法实现的方式高效地组织、搜索和分析这些复杂信息。这些数据库使用嵌入来查找向量之间的相似性,进而对存储的向量进行相似性搜索。我们可以通过不同的方式计算这种相似性,例如欧几里得距离和余弦相似度。每种衡量相似性的方法捕捉到的信息略有不同,哪种方法最适合特定问题取决于所使用的模型和嵌入。
例如,图像的向量嵌入可能包含有关使用的颜色、图像中是否存在柔和或硬朗的线条、是否存在明显的形状或人物,以及这些人物正在做什么的上下文信息。嵌入捕获的这种上下文信息是所使用的模型及其训练数据类型的结果。这种上下文极大地改善了用户的搜索体验。想象一下,使用一张两个人在跳舞的图片进行搜索,然后得到一张两只鱼游在一起的图片作为热门结果,仅仅因为像素颜色非常接近。这可能不是最理想的搜索结果。而使用向量搜索可以检索一张两个人在跳舞的图片,尽管单个像素可能不太匹配,但整体图像的匹配度要高得多。

在我们入门指南中的每个高维向量都存储了 768 个不同的数字,每个数字代表它们所描述数据的一些信息,在本例中是自行车描述的文本。向量数据库使用不同类型的相似性度量(您可以在此处了解更多信息 {向量相似性 101 即将推出})来确定哪些向量与正在搜索的向量最接近。
查询向量是向量数据库功能中的一个基本概念,是这些系统提供高级搜索功能的基石。查询向量本质上是搜索查询的向量表示,可以从任何形式的非结构化数据派生,例如文本描述、图像或音频片段。该向量以数值形式封装了查询的本质,使数据库能够对存储的向量执行相似性搜索,以找到最相关的结果。
当用户向向量数据库提交查询时,系统首先使用应用于存储数据的相同向量化过程将该查询转换为其向量表示。这确保了查询和数据库内容位于相同的维度空间中,从而可以测量查询向量和数据库向量之间的相似性。然后,数据库利用欧几里得距离或余弦相似度等算法,根据存储向量与查询向量的接近程度来识别和排序存储向量,从而有效地找到与用户查询最匹配的数据片段。
将查询转换为向量并搜索相似项的能力使得向量数据库成为广泛应用的极其强大的工具,从个性化推荐系统到复杂的内容检索和自然语言处理(NLP)任务。查询向量允许这些数据库理解和解释搜索查询的细微之处和上下文,从而获得比传统基于关键词的搜索方法更准确和相关的搜索结果。
向量数据库因其在支持 AI 应用开发和部署中的关键作用而备受关注。随着这些应用变得越来越复杂,对能够处理复杂查询和大量数据的有效数据存储和检索系统的需求变得至关重要。向量数据库凭借其高效存储和管理高维向量数据的能力,正日益被认为是 AI 驱动技术不可或缺的基础设施组件。
向量数据库凭借其高效管理和搜索高维数据的独特能力,在为各行各业的广泛应用提供支持方面发挥着重要作用。
主要用例包括
推荐系统利用向量数据库理解用户偏好和内容特征,在电子商务、流媒体服务和社交媒体平台中提供个性化建议。
图像和视频检索:向量数据库通过比较表示图像或视频帧的向量之间的相似性,实现快速准确的视觉内容搜索,这对于数字图书馆、图库网站和监控系统至关重要。
自然语言处理 (NLP):向量数据库通过存储和搜索表示为向量的文本以捕获上下文相似性,支持 NLP 应用,例如语义搜索、聊天机器人和语言翻译服务。
欺诈检测和安全:通过实时分析行为模式和检测异常,向量数据库有助于识别欺诈交易和潜在的安全漏洞,从而增强在线系统的安全性。
生物特征识别:在人脸识别和指纹识别等生物特征识别系统中使用向量数据库,可以快速准确地匹配生物特征数据,用于安全和身份验证目的。
向量数据库的未来与生成式 AI 的快速发展密切相关,有望在数据管理、搜索和利用方式上带来变革。随着生成式 AI 技术的演进,它们正在产生越来越大量的复杂高维数据,从合成图像到自然语言构造。在此背景下,向量数据库将变得更加关键,成为高效存储和查询这些数据以推动 AI 驱动创新的支柱。向量数据库与生成式 AI 的集成将实现更复杂和细致的应用,范围涵盖实时创建高度个性化的内容,到在医疗保健、娱乐和自主系统等行业开发高级模拟和预测模型。这种协同效应有望突破可能的界限,使数据比以往任何时候都更容易访问、解释和可操作,为 AI 和数据技术的下一波突破奠定基础。
要开始使用向量数据库,请查看我们的入门指南此处,了解存储向量嵌入并对其进行向量搜索是多么容易。




