 Redis 8 已发布——并且是开源的
Redis 8 已发布——并且是开源的
了解更多

与只存储数据而无上下文的传统缓存不同,语义缓存理解用户查询背后的含义。它使数据访问更快、系统响应更智能,这对于 GenAI 应用至关重要。
语义缓存解释并存储用户查询的语义含义,使系统能够根据意图而非仅字面匹配来检索信息。这种方法支持更细致的数据交互,缓存提供的响应比传统缓存更具相关性,且比大型语言模型 (LLM) 的典型响应更快。
把语义缓存想象成一位精明的图书管理员。他们不仅知道每本书在哪里,还理解每个请求的上下文。他们不是仅凭书名分发书籍,而是考虑读者的意图、过去的阅读记录以及与查询最相关的内容。就像这位图书管理员一样,语义缓存能够动态地检索和提供与当前查询最相关的数据,确保每个响应都符合用户的需求。
使用 RedisVL 加快您的应用数据处理速度,提升性能并降低成本。通过 Redis 语义缓存用户指南开启您更智能的数据处理之旅。
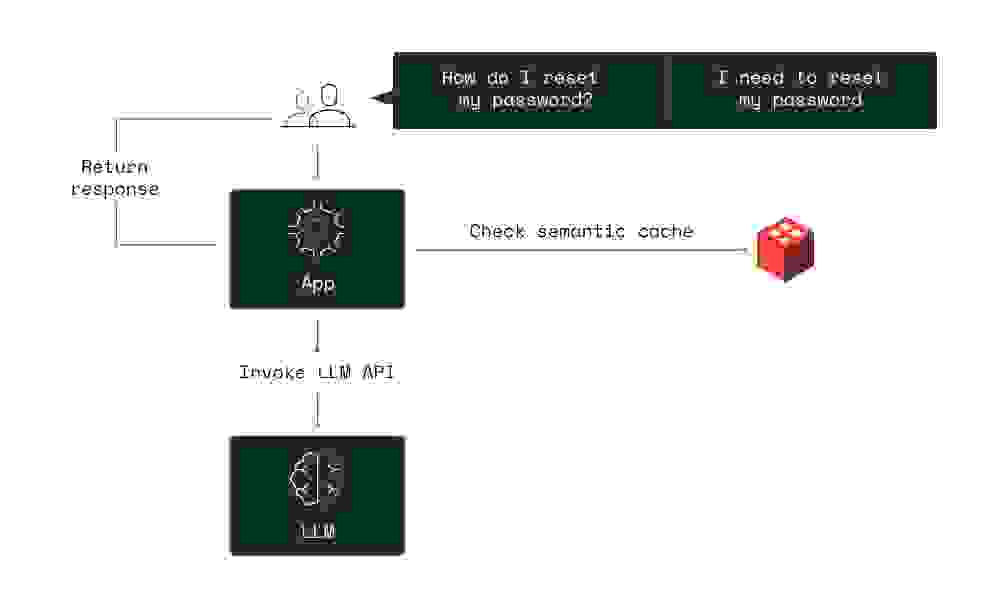
传统缓存侧重于临时存储数据以加快频繁访问信息的加载时间,但忽略了被查询数据的含义和上下文。这就是语义缓存的用武之地。它利用一个智能层来理解每个查询的意图,确保只存储和检索最相关的数据。语义缓存使用 AI 嵌入模型为数据片段添加含义,从而使检索更快、更相关。这种方法减少了不必要的数据处理,提高了系统效率。
这些组件通过更快、更具上下文感知能力的响应来提升应用性能。将这些元素集成到 LLM 中改变了模型与大型数据集交互的方式,使语义缓存成为现代 AI 系统的重要组成部分。
语义缓存是 LLM 驱动应用的可靠选择。LLM 处理范围广泛的查询,需要快速、准确且具有上下文感知能力的响应。语义缓存通过有效管理数据、减少计算需求并提供更快响应时间来提高性能。
一个例子是使用语义缓存检索常见问题。在这个聊天机器人示例中,用户询问有关 IRS 申报文件等内部源文件的问题,并且可以获得快 15 倍的回复。
鉴于上下文感知数据是重中之重,语义缓存帮助 AI 系统不仅提供更快的响应,还提供更相关的响应。这对于从自动化客户服务到研究中复杂分析的应用至关重要。
在 LLM 应用中,向量搜索在语义缓存框架中起着至关重要的作用。它使 LLM 能够快速筛选大量数据,通过比较用户查询和缓存响应的向量来找到最相关的信息。
语义缓存极大地提升了 AI 应用的性能。以下是一些展示其强大功能的用例
有效实现语义缓存始于选择合适的基础设施。一些关键考虑因素包括
为确保您的语义缓存系统能够处理不断增长的负载并保持高性能,请考虑以下策略
在动态环境中,数据和用户交互不断演变,保持响应的准确性和一致性至关重要。
要将这些实践整合成一个连贯的实现策略,您可以遵循以下步骤
通过遵循这些最佳实践,组织可以充分发挥语义缓存的潜力,从而提升性能、改善用户体验并提高运营效率。
语义缓存代表着一个巨大的飞跃,提升了 LLM 的性能,并全面加速了 AI 应用。通过智能管理数据的存储、访问和重用方式,语义缓存减少了计算需求,实现了实时响应,并确保输出既准确又具有上下文感知能力。在数据密集型环境中,快速且相关的响应至关重要。
展望未来,语义缓存的作用将变得更加关键。查询变得越来越复杂,对实时数据处理日益增长的需求需要更精密的缓存策略。GenAI 处理和后处理变得更加复杂和耗时,需要加速响应的策略。随着模型变得更强大,使用最优模型的计算成本上升,公司将持续优化支出。语义缓存已准备好迎接这些挑战,使数据检索更快、更智能。
要充分利用语义缓存,您需要强大且多功能的工具。Redis 作为世界上最快的数据平台,能将您的语义缓存策略提升至实时水平。凭借高性能的数据处理和对多种数据结构的支持,Redis 优化了响应性和效率,让您的 GenAI 应用快速运行。

