 Redis 8 来了——而且是开源的
Redis 8 来了——而且是开源的
了解更多

上周,我们发布了 RedisGraph 1.2.0。如果您一直在使用 RedisGraph 或考虑试用该模块,那么现在是了解我们一直在做什么的好时机,因为我们将继续增强其图形处理能力。让我们回顾一下新版本中的一些更值得注意的补充

在此版本之前,将节点 A 通过 R 类型的边连接到节点 B,然后在两者之间形成相同类型的另一个连接是不可能的。由于连接过去在 RedisGraph 中的表示方式,后者会覆盖前者。
对于每种关系类型,例如 `friend`、`works_at` 或 `owns`,RedisGraph 维护一个映射矩阵 M,其中 M[I,J] = EdgeID,其中 I 和 J 分别是源节点和目标节点 ID。在 A 和 B 之间形成第一个 R 类型的连接会将 M[I,J] 设置为 X,而在两者之间引入第二个 R 类型的边会将 M[I,J] 覆盖为 Y。
在 1.2.0 版本中,RedisGraph 现在支持相同类型的多个边。我们的映射矩阵 M 可以保存指向边 ID 数组的指针,M[I,J] = [ID0, ID1, … IDn],指定连接 I 和 J 的 R 类型的每个边。
为了避免高内存碎片,请考虑一个包含 5 亿条边的图,其中没有边共享源节点或目标节点,即任意两个节点之间没有相同类型的多个边。一种简单的方法是分配 5 亿个长度为 1 的数组,从而显着增加我们的内存消耗。为了应对这种情况,我们的映射矩阵条目类型保持不变 (UINT64)。 从一个空图开始 – M[I,J] 为空 – 当形成第一个边 E 时,将 I 连接到 J,M[I,J] = ID(E) 是一个简单的常量,不会分配额外的内存。在某个时候,I 再次通过与 E 相同类型的边 X 连接到 J,M[I,J] = [ID(E), ID(X)],分配一个数组,并在 M[I,J] 中放置一个指针。
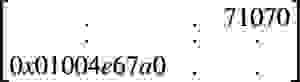
每当创建图形实体(节点、边)时,都会为其分配一个内部唯一 ID。此 ID 在实体的整个生命周期内都是不可变的,您可以使用 ID 函数检索实体 ID:MATCH (N) RETURN N, ID(N) LIMIT 10。 类似地,通过 ID 查找节点:“MATCH (N) WHERE ID(N) = 9 RETURN N” 过去执行的是完整扫描,检查图形中的每个节点。
我们的最新版本 RedisGraph 引入了一种优化,它将这些完整扫描和过滤操作替换为单个“按 ID 查找节点”操作,该操作以恒定时间运行。


在 RedisGraph 中,遍历是通过矩阵乘法执行的。例如,考虑搜索模式:(A)-[X]->(B)-[Y]->(c)。 要查找所有连接到目标节点 (C) 的源节点 (A),我们只需将矩阵 [X] 乘以矩阵 [Y],X*Y=Z,而 Z 的行和列分别表示 A 和 C。
如果我们只对少数 C 节点感兴趣,我们将避免执行 X*Y, 因为这些可能是非常大的矩阵。 因此,我们将附加一个小过滤器矩阵 F,(F*X)*Y。 通过首先乘以 F*X,我们减少了任何中间矩阵计算的维度,从而显着减少了计算时间。
根据 F*X*Y 的结果,我们可能会发现自己计算了不同的过滤器矩阵 F 并重新评估此表达式以获得额外的 C 节点。 在我们获得足够的数据之前,此过程可能会重复多次。 现在,每当搜索模式包含从左到右和从右到左的边时:(A)-[X]->(B)<-[Y]-(C), 我们将必须转置 Y,(F*X)*Transpose(Y) = Z。

以前版本的 RedisGraph 在每次评估此表达式时都会转置 Y,这成本很高。 现在,从 1.2.0 版本开始,我们只会在第一次评估时转置一次。 尽管这会导致每个查询的内存消耗更高,但延迟的提升绝对值得。
总的来说,RedisGraph 1.2.0 既包含过期的功能,也包含一些有趣的优化, 不妨试一试 让我们知道您的想法!

