查询语法
学习如何使用查询语法
基本语法
您可以使用以下规则为复杂查询使用简单语法
-
精确短语用引号括起来,例如,
"hello world"。 -
多词短语是词元列表,例如,
foo bar baz,表示词元的交集 (AND)。 -
OR 联合用竖线 (
|) 表示,例如,hello|hallo|shalom|hola。注意事项:
考虑示例
hello world | "goodbye" moon中解析器行为的差异- 在 DIALECT 1 中,此查询被解释为搜索
(hello world | "goodbye") moon。 - 在 DIALECT 2 或更高版本中,此查询被解释为搜索
hello world或"goodbye" moon。
- 在 DIALECT 1 中,此查询被解释为搜索
-
NOT 否定表达式或子查询用减号 (
-) 表示,例如,hello -world。也支持纯否定查询,例如-foo和-@title:(foo|bar)。注意事项:
考虑一个带有否定符的简单查询
-hello world- 在 DIALECT 1 中,此查询被解释为“查找任何不包含
hello和 不包含world的字段中的值”。等价的查询是-(hello world)或-hello -world。 - 在 DIALECT 2 或更高版本中,此查询被解释为
-hello和world(仅hello被否定)。 - 在 DIALECT 2 或更高版本中,为了实现 DIALECT 1 的默认行为,请将您的查询更新为
-(hello world)。
- 在 DIALECT 1 中,此查询被解释为“查找任何不包含
-
前缀/中缀/后缀匹配(以某个词元开头/包含/结尾的所有词元)用星号
*表示。出于性能原因,强制要求最小词元长度。默认为 2,但可配置。 -
在 DIALECT 2 或更高版本中,通配符模式匹配表示为
"w'foo*bar?'"。请注意使用双引号包含w模式。 -
一个特殊的通配符查询,返回索引中的所有结果,就是星号
*。这不能与其他选项结合使用。 -
从 v2.6.1 开始,DIALECT 3 从多值属性返回 JSON 而非标量。
-
使用语法
hello @field:world选择特定字段。 -
对数字字段使用语法
@field:[{min} {max}]进行数字范围匹配。 -
对地理字段使用语法
@field:[{lon} {lat} {radius} {m|km|mi|ft}]进行地理半径匹配。 -
从 2.6 开始,对向量字段使用语法
@field:[VECTOR_RANGE {radius} $query_vec]进行范围查询,其中query_vec作为查询参数给出。 -
从 v2.4 开始,对向量字段进行 k 最近邻 (KNN) 查询,带或不带预过滤,使用语法
{filter_query}=>[KNN {num} @field $query_vec]。 -
使用语法
@field:{tag | tag | ...}的标签字段过滤器。请参阅标签的完整文档。 -
可选词元或子句:
foo ~bar表示bar是可选的,但包含bar的文档排名更高。 -
词元上的模糊匹配:
%hello%表示与其 Levenshtein 距离为 1 的所有词元。使用多对 '%' 括号,最多三对,以增加 Levenshtein 距离。 -
查询中的表达式可以用括号括起来以消除歧义,例如,
(hello|hella) (world|werld)。 -
查询属性可以应用于单个子句,例如,
(foo bar) => { $weight: 2.0; $slop: 1; $inorder: false; }。 -
上述组合可以一起使用,例如,
hello (world|foo) "bar baz" bbbb。
纯否定查询
从 v0.19.3 开始,可以只使用一个否定表达式进行查询。例如 -hello 或 -(@title:(foo|bar))。结果是所有不包含查询词元的文档。
字段修饰符
您可以在查询中指定字段修饰符,而不仅仅是使用全局关键字 INFIELDS。
要指定查询匹配的字段,请在每个表达式或子表达式前面加上 @ 符号、字段名和 :(冒号)符号。
如果字段修饰符位于多个单词或表达式之前,在 DIALECT 1 中它仅应用于相邻的表达式。在 DIALECT 2 或更高版本中,它会扩展查询到其他字段。
考虑这个简单查询:@name:James Brown。这里的字段修饰符 @name 后面跟着两个单词:James 和 Brown。
- 在 DIALECT 1 中,此查询将被解释为“在
@name字段中查找James Brown”。 - 在 DIALECT 2 或更高版本中,此查询将被解释为“在
@name字段中查找James和 在任何文本字段中查找Brown”。换句话说,它将被解释为(@name:James) Brown。 - 在 DIALECT 2 或更高版本中,为了实现 DIALECT 1 的默认行为,请将您的查询更新为
@name:(James Brown)。
如果字段修饰符位于括号中的表达式之前,它仅适用于括号内的表达式。该表达式对于指定的字段应该是有效的,否则将被跳过。
要在多个字段上创建复杂的过滤,您可以组合多个修饰符。例如,如果您有一个汽车型号索引,包含车辆类别、原产国和发动机类型,您可以使用以下查询搜索在韩国制造的、配备混合动力或柴油发动机的 SUV
FT.SEARCH cars "@country:korea @engine:(diesel|hybrid) @class:suv"
您可以将多个修饰符应用于同一个词元或分组词元
FT.SEARCH idx "@title|body:(hello world) @url|image:mydomain"
现在,您可以搜索在正文或标题中包含 "hello" 和 "world",并且在 url 或 image 字段中包含词元 mydomain 的文档。
查询中的数字过滤器
如果架构中的字段被定义为 NUMERIC,可以使用 Redis 请求中的 FILTER 参数或通过在查询中指定过滤规则来过滤。语法是 @field:[{min} {max}],例如,@price:[100 200]。
关于数字谓词的几点注意事项
-
可以将数字谓词指定为整个查询,而使用
FILTER参数则无法实现。 -
可以在同一个查询中对多个数字过滤器进行交集或并集操作,无论是针对同一个字段还是不同的字段。
-
-inf、inf和+inf是范围中可接受的数字。因此,“大于 100” 表示为[(100 inf]。 -
数字过滤器是包含性的。独占性最小值或最大值用
(加在数字前面表示,例如,[(100 (200]。 -
可以通过在过滤器前面加上
-符号来否定数字过滤器。例如,返回价格不等于 100 的结果表示为:@title:foo -@price:[100 100]。
标签过滤器
从 v0.91 开始,您可以使用一种特殊的字段类型,称为标签字段,它在索引中有更简单的分词和编码。您不能使用通用的无字段搜索来访问这些字段中的值。相反,您使用特殊语法
@field:{ tag | tag | ...}
示例
@cities:{ New York | Los Angeles | Barcelona }
标签可以有多个单词或包含字段分隔符(默认为 ,)以外的其他标点符号。标签中的以下字符应该用反斜杠 (\) 转义:$、{、}、\ 和 |。
"to\\ be\\ or\\ not\\ to\\ be"。为了保险起见,您也可以转义标签内的所有空格。从 RediSearch 2.4 开始,使用DIALECT 2 或更高版本,您可以在标签查询中使用空格,即使包含停用词。请注意,同一子句中的多个标签会创建包含任一标签的文档的联合。要创建包含所有标签的文档的交集,您应该多次重复标签过滤器。例如
# Return all documents containing all three cities as tags
@cities:{ New York } @cities:{Los Angeles} @cities:{ Barcelona }
# Now, return all documents containing either city
@cities:{ New York | Los Angeles | Barcelona }
标签子句可以组合到任何子句中,用作否定表达式、可选表达式等。
地理过滤器
从 v0.21 开始,可以直接使用语法 @field:[{lon} {lat} {radius} {m|km|mi|ft}] 将地理半径查询添加到查询语言中。这将结果过滤到距离一个经纬度点指定半径范围内的区域,半径单位可以是米、千米、英里或英尺。有关详细信息,请参阅 Redis 自己的GEORADIUS 命令。
半径过滤器可以像数字过滤器一样添加到查询中。例如,在商家数据库中,查找旧金山附近(半径 5 公里以内)的中餐馆可以表示为:chinese restaurant @location:[-122.41 37.77 5 km]。
多边形搜索
地理空间数据库对于管理和分析各种行业中的基于位置的数据至关重要。它们帮助组织做出数据驱动的决策,优化运营,并更有效地实现其战略目标。多边形搜索扩展了 Redis 的地理空间搜索功能,使其能够针对 GEOSHAPE 属性中的值进行查询。此值必须遵循几何的“[已知文本表示法](https://en.wikipedia.org/wiki/Well-known_text_representation_of_geometry)”(WKT)。支持以下两种几何形状
- POINT,例如
POINT(2 4)。 - POLYGON,例如
POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))。
有一个新的架构字段类型叫做 GEOSHAPE,可以指定为
FLAT用于笛卡尔 X Y 坐标SPHERICAL用于地理经纬度坐标。这是默认的坐标系统。
最后,有新的FT.SEARCH 语法,允许您查询包含给定地理形状或位于给定地理形状内的多边形。
@field:[{WITHIN|CONTAINS} $geometry] PARAMS 2 geometry {geometry}
这是一个使用两个堆叠多边形的示例,它们代表一个房子内包含一个盒子。
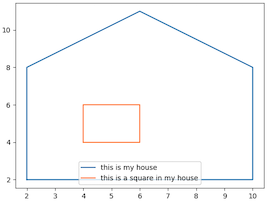
首先,使用 FLAT GEOSHAPE 创建索引,表示一个二维 X Y 坐标系。
FT.CREATE polygon_idx PREFIX 1 shape: SCHEMA g GEOSHAPE FLAT t TEXT
接下来,创建表示图片中几何形状的数据结构。
HSET shape:1 t "this is my house" g "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
HSET shape:2 t "this is a square in my house" g "POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))"
最后,使用FT.SEARCH 查询几何形状。请注意使用必需的 DIALECT 3。这里有一些示例。
搜索包含指定点的多边形
FT.SEARCH polygon_idx "@g:[CONTAINS $point]" PARAMS 2 point 'POINT(8 8)' DIALECT 3
1) (integer) 1
2) "shape:1"
3) 1) "t"
2) "this is my house"
3) "g"
4) "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
搜索包含在指定多边形内的几何形状
FT.SEARCH polygon_idx "@g:[WITHIN $poly]" PARAMS 2 poly 'POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))' DIALECT 3
1) (integer) 2
2) "shape:2"
3) 1) "t"
2) "this is a square in my house"
3) "g"
4) "POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))"
4) "shape:1"
5) 1) "t"
2) "this is my house"
3) "g"
4) "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
搜索未包含在索引几何形状中的多边形
FT.SEARCH polygon_idx "@g:[CONTAINS $poly]" PARAMS 2 poly 'POLYGON((14 4, 14 6, 16 6, 16 4, 14 4))' DIALECT 3
1) (integer) 0
搜索已知包含在几何形状内(盒子)的多边形
FT.SEARCH polygon_idx "@g:[CONTAINS $poly]" PARAMS 2 poly 'POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))' DIALECT 3
1) (integer) 2
2) "shape:1"
3) 1) "t"
2) "this is my house"
3) "g"
4) "POLYGON((2 2, 2 8, 6 11, 10 8, 10 2, 2 2))"
4) "shape:2"
5) 1) "t"
2) "this is a square in my house"
3) "g"
4) "POLYGON((4 4, 4 6, 6 6, 6 4, 4 4))"
请注意,房屋和盒子形状都被返回了。
更多示例,请参阅FT.CREATE 和FT.SEARCH 命令页面。
向量搜索
您可以通过以下方式将向量相似度查询直接添加到查询语言中
-
使用语法
@vector:[VECTOR_RANGE {radius} $query_vec]的范围查询,该查询将结果过滤到距离给定查询向量指定半径范围内。距离度量标准源自索引架构中@vector字段的定义,例如余弦或 L2(从 v2.6.1 开始)。 -
对
@vector字段运行 k 最近邻 (KNN) 查询。基本语法是"*=>[ KNN {num|$num} @vector $query_vec ]"。也可以在过滤结果上运行混合查询。混合查询允许用户指定所有 KNN 查询结果必须满足的过滤条件。过滤条件可以包括任何类型的字段(即,在向量和其他值(如 TEXT、PHONETIC、NUMERIC、GEO 等)上创建的索引)。混合查询的一般语法是{some filter query}=>[ KNN {num|$num} @vector $query_vec],其中=>将过滤查询与向量 KNN 查询分开。
示例
-
返回 10 个最近邻实体,其中
query_vec最接近存储在@vector_field中的向量*=>[KNN 10 @vector_field $query_vec] -
在 2020 年到 2022 年之间发布的实体中,返回 10 个最近邻实体,其中
query_vec最接近存储在@vector_field中的向量@published_year:[2020 2022]=>[KNN 10 @vector_field $query_vec] -
返回所有实体,其中存储在其
@vector_field下的向量与query_vec之间的距离最大为 0.5,根据@vector_field距离度量标准@vector_field:[VECTOR_RANGE 0.5 $query_vec]
从 v2.4 开始,KNN 向量搜索在查询中最多只能使用一次,而从 v2.6 开始,向量范围过滤器可以在查询中使用多次。有关向量相似度语法的更多信息,请参阅查询向量字段和向量搜索示例部分。
前缀匹配
更新索引时,Redis 会维护索引中所有词元的字典。这可用于匹配以给定前缀开头的所有词元。选择前缀匹配是通过将 * 附加到前缀词元来完成的。例如
hel* world
将被扩展以覆盖 (hello|help|helm|...) world。
关于前缀搜索的几点注意事项
-
由于前缀可以扩展为许多词元,因此请谨慎使用。扩展将创建所有后缀的联合操作。
-
作为一种保护措施,为了避免选择过多的词元,从而阻塞单线程的 Redis,前缀匹配有两个限制
-
前缀限制为 2 个或更多字母。您可以通过在模块命令行上使用
MINPREFIX设置来更改此数字。 -
进行词干提取的最小单词长度是 4 个或更多字母。您可以通过在模块命令行上使用
MINSTEMLEN设置来更改此数字。 -
扩展限制为 200 个或更少词元。您可以通过在模块命令行上使用
MAXEXPANSIONS设置来更改此数字。
-
前缀匹配完全支持 Unicode 且不区分大小写。
-
目前,没有基于后缀流行度的排序或偏好设置。
中缀/后缀匹配
从 v2.6.0 开始,字典可用于中缀(包含)或后缀查询,方法是将 * 附加到词元。例如
*sun* *ing
这些查询是 CPU 密集型的,因为它们需要遍历整个字典。
使用后缀树
后缀树维护与后缀匹配的词元列表。如果您使用 WITHSUFFIXTRIE 关键字向字段添加后缀树,您可以创建更有效的中缀和后缀查询,因为它消除了遍历整个字典的需要。但是,联合的迭代不会改变。
后缀查询创建来自后缀词元节点的词元列表的联合。中缀查询使用后缀词元作为树的前缀,并创建来自所有匹配节点的所有词元的联合。
通配符匹配
从 v2.6.0 开始,您可以使用字典进行通配符匹配查询,参数如下。
?- 匹配任意单个字符*- 匹配任意字符重复零次或多次\- 用于转义;其他特殊字符将被忽略
语法示例为 "w'foo*bar?'"。
使用后缀树
后缀树维护与后缀匹配的词元列表。如果您使用 WITHSUFFIXTRIE 关键字向字段添加后缀树,您可以创建更有效的通配符匹配查询,因为它消除了遍历整个字典的需要。但是,联合的迭代不会改变。
使用后缀树,通配符模式在每个 * 字符处分解为词元。使用启发式方法选择词元最少的词元,并将每个词元与通配符模式进行匹配。
模糊匹配
从 v1.2.0 开始,索引中所有词元的字典也可用于执行模糊匹配。模糊匹配基于 Levenshtein 距离 (LD) 执行。通过在词元周围加上 '%' 来执行词元上的模糊匹配,例如
%hello% world
这会针对所有 LD 为 1 的词元执行 hello 的模糊匹配。
从 v1.4.0 开始,可以通过围绕词元的 '%' 字符数量来设置模糊匹配的 LD,因此 %%hello%% 将针对所有 LD 为 2 的词元执行 'hello' 的模糊匹配。
模糊匹配的最大 LD 为 3。
通配符查询
从 v1.1.0 开始,您可以使用一个特殊查询来检索索引中的所有文档。这主要用于聚合引擎。您可以通过仅将单个星号作为查询字符串来调用它,换句话说,FT.SEARCH myIndex *。
您不能将其与查询内的任何其他过滤器、字段修饰符或任何内容组合。从技术上讲,可以在查询字符串之外结合通配符使用已弃用的 FILTER 和 GEOFILTER 请求参数,但这会使通配符失去意义,并且只会损害性能。
查询属性
从 v1.2.0 开始,您可以将特定的查询修改属性应用于查询的特定子句。
语法是 (foo bar) => { $attribute: value; $attribute:value; ...}
(foo bar) => { $weight: 2.0; $slop: 1; $inorder: true; }
~(bar baz) => { $weight: 0.5; }
支持的属性有
- $weight:确定子查询或词元在结果整体排名中的权重(默认值:1.0)。
- $slop:确定查询子句中允许的最大 Slop 值(词元之间的间隙)(默认值:0)。
- $inorder:查询子句中的词元是否必须按照查询中的顺序出现。通常与
$slop一起设置(默认值:false)。 - $phonetic:是否执行语音匹配(默认值:true)。注意:对于未创建为 PHONETIC 的字段,将此属性设置为 true 将产生错误。
从 v2.6.1 开始,查询属性语法支持以下附加属性
- $yield_distance_as:指定距离字段名称,用于稍后的排序和/或返回,适用于产生某种距离度量的子句。目前仅支持向量查询(KNN 和范围)。
- vector query params:以键值对格式传递向量查询的可选参数。请参阅查询向量字段。
一些查询示例
-
简单短语查询 -
hello与worldhello world -
精确短语查询 -
hello后跟world"hello world" -
联合 - 包含
hello或world的文档hello|world -
非 - 包含
hello但不是world的文档hello -world -
联合的交集
(hello|halo) (world|werld) -
联合的否定
hello -(world|werld) -
短语内的联合
(barack|barrack) obama -
可选词元,包含更多匹配项的优先级更高
obama ~barack ~michelle -
一个字段中的精确短语,另一个字段中的一个单词
@title:"barack obama" @job:president -
组合的 AND、OR 和字段指定符
@title:"hello world" @body:(foo bar) @category:(articles|biographies) -
前缀/中缀/后缀查询
hello worl* hel* *worl hello -*worl* -
通配符匹配查询
"w'foo??bar??baz'" "w'???????'" "w'hello*world'" -
数字过滤 - 价格范围在 200 到 500 之间的名为
tv的产品@name:tv @price:[200 500] -
数字过滤 - 年龄大于 18 的用户
@age:[(18 +inf]
将常见 SQL 谓词映射到 Redis 查询引擎
| SQL 条件 | Redis 查询引擎等效 | 注释 |
|---|---|---|
| WHERE x='foo' AND y='bar' | @x:foo @y:bar | 为减少歧义,请使用 (@x:foo) (@y:bar) |
| WHERE x='foo' AND y!='bar' | @x:foo -@y:bar | |
| WHERE x='foo' OR y='bar' | (@x:foo)|(@y:bar) | |
| WHERE x IN ('foo', 'bar','hello world') | @x:(foo|bar|"hello world") | 引号表示精确短语 |
| WHERE y='foo' AND x NOT IN ('foo','bar') | @y:foo (-@x:foo) (-@x:bar) | |
| WHERE x NOT IN ('foo','bar') | -@x:(foo|bar) | |
| WHERE num BETWEEN 10 AND 20 | @num:[10 20] | |
| WHERE num >= 10 | @num:[10 +inf] | |
| WHERE num > 10 | @num:[(10 +inf] | |
| WHERE num < 10 | @num:[-inf (10] | |
| WHERE num <= 10 | @num:[-inf 10] | |
| WHERE num < 10 OR num > 20 | @num:[-inf (10] | @num:[(20 +inf] | |
| WHERE name LIKE 'john%' | @name:john* |
技术说明
查询解析器使用 Lemon Parser Generator 和基于 Ragel 的词法分析器构建。您可以在此 Git 仓库查看 DIALECT 2 语法定义。
您还可以查看search-default-dialect 配置参数。