Uptrace 集成 Redis Enterprise
要收集、查看和监控来自数据库及其他集群组件的指标数据,您可以使用 OpenTelemetry Collector 将 Uptrace 连接到您的 Redis Enterprise 集群。
Uptrace 是一个开源 APM 工具,支持分布式追踪、指标和日志。您可以使用它来监控应用程序并设置自动警报以接收通知。
Uptrace 使用 OpenTelemetry 收集和导出来自 Redis 等软件应用的遥测数据。OpenTelemetry 是一个开源可观测性框架,旨在为所有类型的可观测性信号(如追踪、指标和日志)提供单一标准。
使用 OpenTelemetry Collector,您可以接收、处理遥测数据并将其导出到任何OpenTelemetry 后端。您还可以使用 Collector 抓取 Redis 提供的 Prometheus 指标,然后将这些指标导出到 Uptrace。
您可以使用 Uptrace 来
- 收集并显示在管理员控制台中不可用的数据指标。
- 使用 Uptrace 社区维护的预构建仪表盘模板。
- 设置自动警报,并通过电子邮件、Slack、Telegram 等接收通知。
- 使用OpenTelemetry tracing监控您的应用性能和日志。
安装 Collector 和 Uptrace
由于安装 OpenTelemetry Collector 和 Uptrace 可能需要一些时间,您可以使用随 Redis Enterprise 集群提供的docker-compose示例。
下载 Docker 示例后,在启动 Docker 容器之前,您可以编辑 uptrace/example/redis-enterprise 目录中的以下配置文件
otel-collector.yaml- 配置 OpenTelemetry Collector 容器中的/etc/otelcol-contrib/config.yaml文件。uptrace.yml- 配置 Uptrace 容器中的/etc/uptrace/uptrace.yml文件。
您也可以使用以下指南从头开始安装 OpenTelemetry 和 Uptrace
安装 Uptrace 后,您可以通过 https://:14318/ 访问 Uptrace UI。
抓取 Prometheus 指标
Redis Enterprise 集群在 https://:8070/ 上暴露了一个 Prometheus 抓取端点。您可以通过向 OpenTelemetry Collector 配置添加以下行来抓取该端点
# /etc/otelcol-contrib/config.yaml
prometheus_simple/cluster1:
collection_interval: 10s
endpoint: "localhost:8070" # Redis Cluster endpoint
metrics_path: "/"
tls:
insecure: false
insecure_skip_verify: true
min_version: "1.0"
接下来,您可以使用 OpenTelemetry protocol (OTLP) 将收集到的指标导出到 Uptrace
# /etc/otelcol-contrib/config.yaml
receivers:
otlp:
protocols:
grpc:
http:
exporters:
otlp/uptrace:
# Uptrace is accepting metrics on this port
endpoint: localhost:14317
headers: { "uptrace-dsn": "http://project1_secret_token@localhost:14317/1" }
tls: { insecure: true }
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/uptrace]
metrics:
receivers: [otlp, prometheus_simple/cluster1]
processors: [batch]
exporters: [otlp/uptrace]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlp/uptrace]
不要忘记重启 Collector,然后检查日志是否有任何错误
docker-compose logs otel-collector
# or
sudo journalctl -u otelcol-contrib -f
您也可以在这里查看完整的 OpenTelemetry Collector 配置。
查看指标
当指标开始送达 Uptrace 时,您应该会在“Metrics”(指标)选项卡中看到几个仪表盘。总共有 3 个 Uptrace 仪表盘用于显示 Redis Enterprise 指标
-
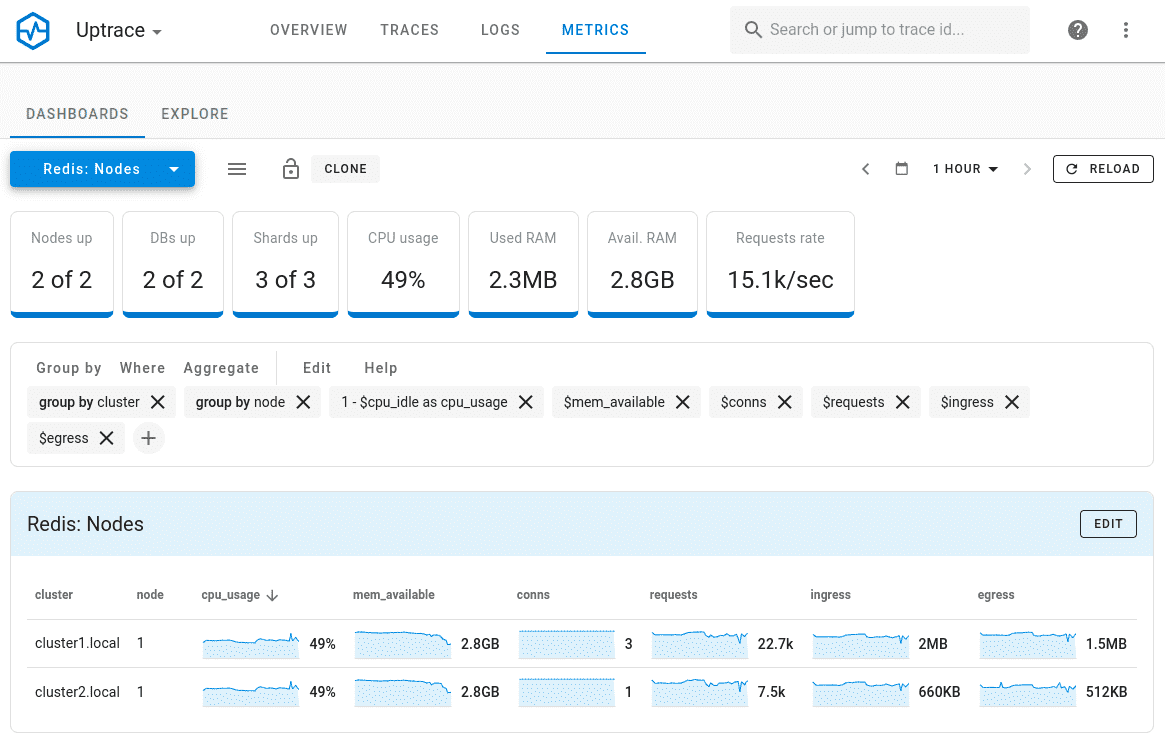
“Redis: Nodes”(Redis:节点)仪表盘显示集群节点列表。您可以选择一个节点来查看其指标。
-
“Redis: Databases”(Redis:数据库)显示所有集群节点中的 Redis 数据库列表。要查找特定数据库,您可以使用过滤器或按列对表进行排序。
-
“Redis: Shards”(Redis:分片)包含所有集群节点中的分片列表。您可以过滤或对分片进行排序,并选择一个分片查看更多详细信息。
监控指标
要开始监控指标,您需要使用 Uptrace UI 创建指标监控器
- 打开“Alerts”(警报)->“Monitors”(监控器)。
- 点击“Create monitor”(创建监控器)->“Create metrics monitor”(创建指标监控器)。
例如,以下监控器使用按节点分组的表达式来创建警报,当单个 Redis 分片发生故障时触发
monitors:
- name: Redis shard is down
metrics:
- redis_up as $redis_up
query:
- group by cluster # monitor each cluster,
- group by bdb # each database,
- group by node # and each shard
- $redis_up
min_allowed_value: 1
# shard should be down for 5 minutes to trigger an alert
for_duration: 5m
您还可以创建包含更复杂表达式的查询。
例如,以下监控器会在键空间命中率低于 75% 或内存碎片率过高时创建警报
monitors:
- name: Redis read hit rate < 75%
metrics:
- redis_keyspace_read_hits as $hits
- redis_keyspace_read_misses as $misses
query:
- group by cluster
- group by bdb
- group by node
- $hits / ($hits + $misses) as hit_rate
min_allowed_value: 0.75
for_duration: 5m
- name: Memory fragmentation is too high
metrics:
- redis_used_memory as $mem_used
- redis_mem_fragmentation_ratio as $fragmentation
query:
- group by cluster
- group by bdb
- group by node
- where $mem_used > 32mb
- $fragmentation
max_allowed_value: 3
for_duration: 5m
您可以在这里了解有关查询语言的更多信息。