配置 Redis Enterprise 中 Redis 查询引擎的查询性能因子
配置 Redis Enterprise 中 Redis 查询引擎的查询性能因子以提高查询性能。
查询性能因子旨在提高查询性能,包括向量搜索。启用后,通过为每个分片分配更多虚拟 CPU,可以增加数据库的计算容量和查询吞吐量。这与通过增加分片进行水平扩展(从而实现更高的键值操作吞吐量)相辅相成。本文档介绍如何配置查询性能因子。
前提条件
Redis 查询引擎需要运行 Redis Enterprise Software 版本 7.4.2-54 或更高版本的集群。
如果您没有支持 Redis 查询引擎的集群,请在新集群上安装 Redis Enterprise Software 版本 7.4.2-54 或更高版本,或升级现有集群。
容量规划
-
计算 Redis 数据库的硬件要求
-
确定您想要的查询性能因子和所需的 CPU 数量。除 Redis 所需的 20% 外,未使用的 CPU 可用于可扩展的 Redis 查询引擎。
-
创建一个新的 Redis 数据库,并配置查询性能因子所需的 CPU 数量。
计算查询性能因子
查询性能因子所需的 CPU
Redis 查询引擎的垂直扩展是通过为 RediSearch 模块提供额外的 CPU 来实现的。至少 20% 的可用 CPU 必须保留用于 Redis 内部处理。使用以下公式定义可分配给搜索的最大 CPU 数量。
| 变量 | 值 |
|---|---|
| 每个节点的 CPU | x |
| Redis 内部处理 | 20% |
| Redis 查询引擎的可用 CPU | floor(0.8 * x) |
查询性能因子与 CPU 的关系
下表显示了每个性能因子所需的 CPU 数量。此计算取决于搜索索引和查询的定义方式。某些场景可能产生的吞吐量低于下表中的比率。
| 扩展因子 | Redis 查询引擎所需的最小 CPU 数 |
|---|---|
| 无(默认) | 1 |
| 2 | 3 |
| 4 | 6 |
| 6 | 9 |
| 8 | 12 |
| 10 | 15 |
| 12 | 18 |
| 14 | 21 |
| 16 | 24 |
查询性能因子计算示例
| 变量 | 值 |
|---|---|
| 每个节点的 CPU | 8 |
| 可用 CPU | floor(0.8 * 8)=6 |
| 扩展因子 | 4x |
| 扩展因子所需的最小 CPU 数 | 6 |
手动配置查询性能因子
在 Redis Enterprise Software 中手动配置查询性能因子的步骤
-
在Cluster Manager UI 中创建新数据库或编辑现有数据库配置时配置查询性能因子参数。
-
如果为现有数据库配置查询性能因子,还需要重启分片。新创建的数据库可以跳过此步骤。
在 Cluster Manager UI 中配置查询性能因子参数
您可以使用 Cluster Manager UI 在创建新数据库或编辑已启用搜索的现有数据库时配置查询性能因子。
-
在数据库配置屏幕的“功能 (Capabilities)”部分,单击“参数 (Parameters)”。
-
如果要创建新数据库,请选择“搜索与查询 (Search and query)”。
-
调整 RediSearch 参数以包含
WORKERS <线程数>请参阅计算查询性能因子,以确定用于
<线程数>所需的最小 CPU 数。 -
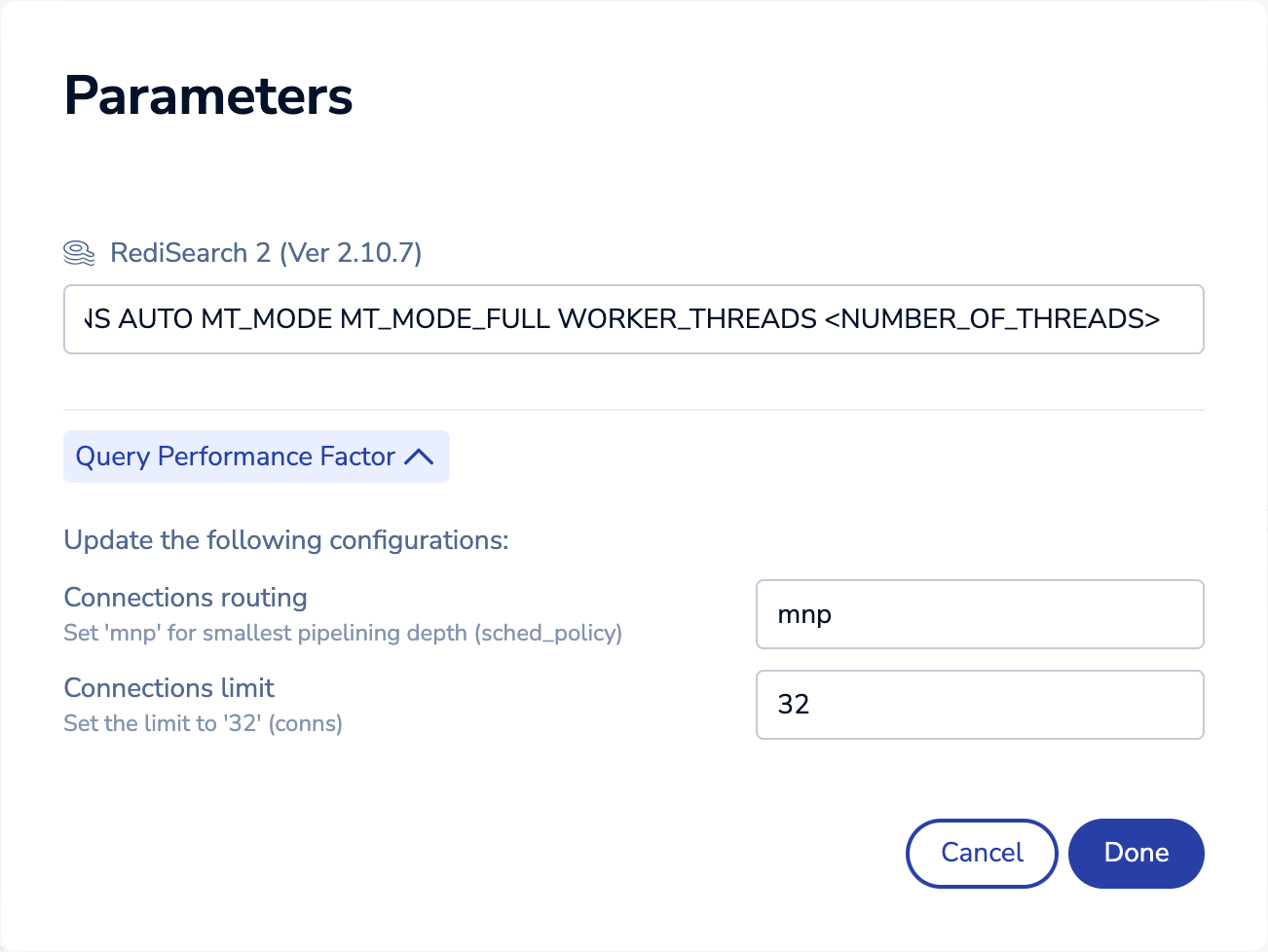
展开“查询性能因子 (Query Performance Factor)”部分并输入以下值
-
连接路由 (Connections routing) 的
mnp -
连接限制 (Connections limit) 的
32
-
-
单击“完成 (Done)”关闭参数编辑器。
-
单击“创建 (Create)”或“保存 (Save)”。
重启分片
为现有数据库更新查询性能因子后,重启所有分片以应用新设置。您可以迁移分片来重启它们。新创建的数据库可以跳过此步骤。
-
使用
rladmin status shards db <数据库名称>列出数据库的所有分片rladmin status shards db db-name示例输出
SHARDS: DB:ID NAME ID NODE ROLE SLOTS USED_MEMORY STATUS db:2 db-name redis:1 node:1 master 0-16383 1.95MB OK db:2 db-name redis:2 node:2 slave 0-16383 1.95MB OK请注意以下字段以便进行后续步骤
ID: Redis 分片的 ID。NODE: 分片当前所在的节点。ROLE:master是主分片;slave是副本分片。
-
对于每个副本分片,使用
rladmin migrate shard将其迁移到不同的节点并重启rladmin migrate shard <shard_id> target_node <node_id> -
迁移副本分片后,迁移原始主分片。
-
重新运行
rladmin status shards db <数据库名称>以验证分片是否已迁移到不同的节点rladmin status shards db db-name示例输出
SHARDS: DB:ID NAME ID NODE ROLE SLOTS USED_MEMORY STATUS db:2 db-name redis:1 node:2 master 0-16383 1.95MB OK db:2 db-name redis:2 node:1 slave 0-16383 1.95MB OK
使用 REST API 配置查询性能因子
您可以使用 Redis Enterprise Software REST API 在创建新数据库或更新现有数据库时配置查询性能因子。
使用 REST API 创建新数据库
要创建数据库并配置查询性能因子,请使用create database REST API 端点和包含以下参数的BDB 对象
{
"sched_policy": "mnp",
"conns": 32,
"module_list": [{
"module_name": "search",
"module_args": "MT_MODE MT_MODE_FULL WORKER_THREADS <NUMBER_OF_CPUS>"
}]
}
请参阅计算性能因子,以确定用于 <CPU 数量> 的值。
新数据库的 REST API 请求示例
以下 JSON 是用于创建配置了 4x 查询性能因子的新数据库的请求体示例
{
"name": "scalable-search-db",
"type": "redis",
"memory_size": 10000000,
"port": 13000,
"authentication_redis_pass": "<your default db pwd>",
"proxy_policy": "all-master-shards",
"sched_policy": "mnp",
"conns": 32,
"sharding": true,
"shards_count": 3,
"shards_placement": "sparse",
"shard_key_regex": [{"regex": ".*\\{(?<tag>.*)\\}.*"}, {"regex": "(?<tag>.*)"}],
"replication": false,
"module_list": [{
"module_name": "search",
"module_args": "MT_MODE MT_MODE_FULL WORKER_THREADS 6"
}]
}
以下 cURL 请求根据 JSON 示例创建新数据库
curl -k -u "<user>:<password>" https://<host>:9443/v1/bdbs -H "Content-Type:application/json" -d @scalable-search-db.json
使用 REST API 更新现有数据库
要配置现有数据库的查询性能因子,请使用以下 REST API 请求
- 由于此过程还会重启数据库分片,因此应在维护期间执行此操作。
- 此过程会覆盖任何现有的模块配置参数。
以下示例脚本使用这两个端点配置 4x 查询性能因子
#!/bin/bash
export DB_ID=1
export CPU=6
export MODULE_ID=`curl -s -k -u "<user>:<password>" https://<host>:9443/v1/bdbs/$DB_ID | jq '.module_list[] | select(.module_name=="search").module_id' | tr -d '"'`
curl -o /dev/null -s -k -u "<user>:<password>" -X PUT https://<host>:9443/v1/bdbs/$DB_ID -H "Content-Type:application/json" -d '{
"sched_policy": "mnp",
"conns": 32
}'
sleep 1
curl -o /dev/null -s -k -u "<user>:<password>" https://<host>:9443/v1/bdbs/$DB_ID/modules/upgrade -H "Content-Type:application/json" -d '{
"modules": [
{
"module_name": "search",
"new_module_args": "MT_MODE MT_MODE_FULL WORKER_THREADS '$CPU'",
"current_module": "'$MODULE_ID'",
"new_module": "'$MODULE_ID'"
}
]
}'
监控 Redis 查询引擎
监控配置了查询性能因子的数据库的步骤
-
将 Redis Enterprise 部署与 Prometheus 集成。有关说明,请参阅Prometheus 和 Grafana 与 Redis Enterprise。
-
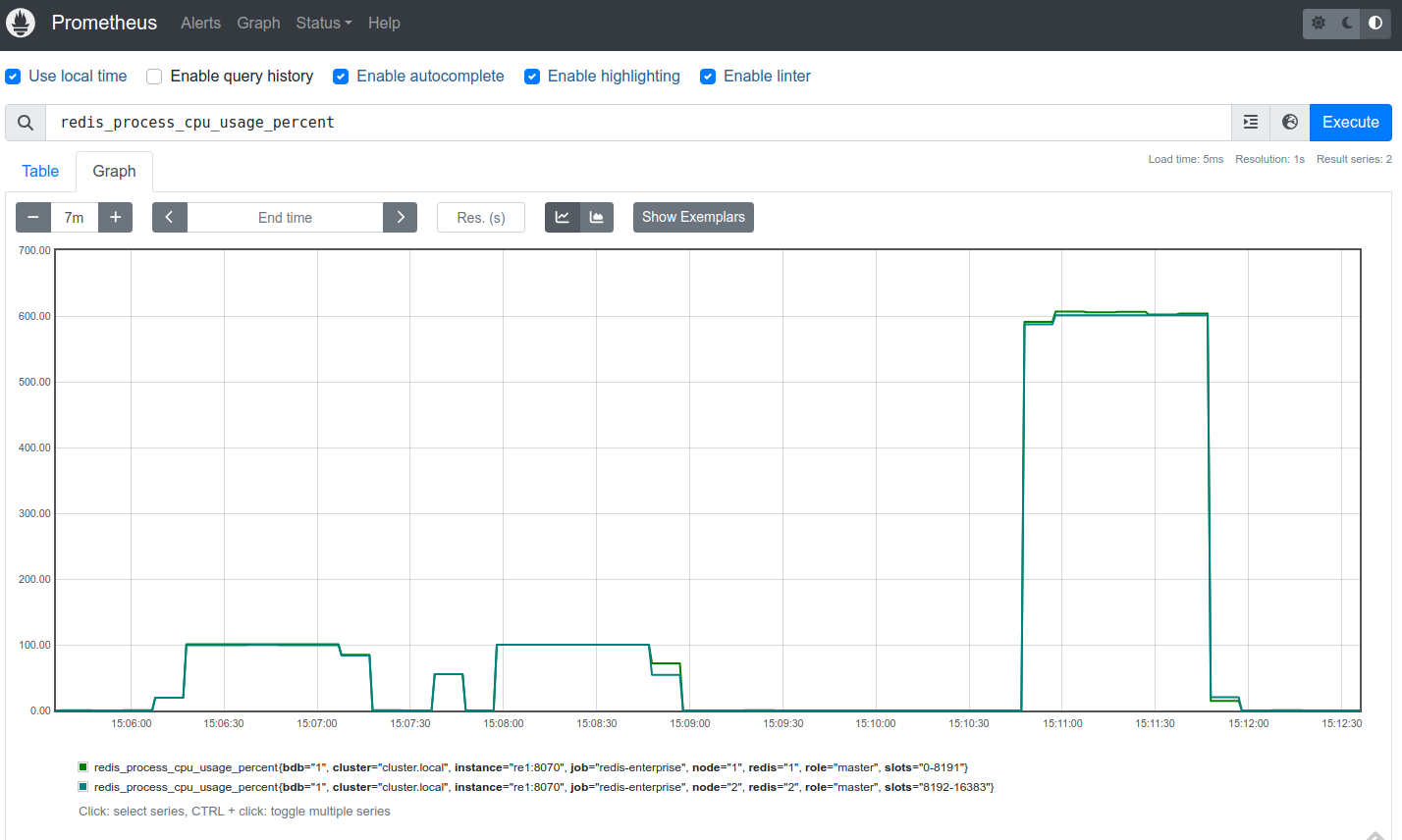
监控
redis_process_cpu_usage_percent分片指标。以下 Prometheus UI 截图显示了包含两个分片的数据库的
redis_process_cpu_usage_percent峰值-
第一个 100% 峰值:默认状态下(没有额外 CPU 用于搜索)运行
memtier_benchmark搜索测试。 -
第二个 100% 峰值:配置 4x 查询性能因子并重启分片。
-
第三个 600% 峰值:在 4x 查询性能因子下(每个分片 6 个 CPU)运行
memtier_benchmark多线程搜索测试。
-