时序
您可以在 Redis Enterprise 中使用 Redis 开源版管理时序数据。
功能
- 按开始时间和结束时间查询
- 按标签集查询
- 对任意时间桶进行聚合查询(Min、Max、Avg、Sum、Range、Count、First、Last)
- 可配置的最大保留期限
- 压缩/汇总 - 自动更新的聚合时序
- 标签索引 - 每个键都有标签,可用于按标签查询
内存模型
时序是内存块的链表。每个块都有预定义的样本大小。每个样本是一个包含时间和值的 128 位元组,其中 64 位用于时间戳,64 位用于值。
时序功能
Redis 开源版提供了一种新的数据类型,该数据类型使用固定大小的内存块存储时序样本,并使用与 Redis Streams 相同的 Radix Tree 实现进行索引。借助 Streams,您可以创建有上限的流,从而有效地限制消息数量。对于时序,您可以应用以毫秒为单位的保留策略。这更适合时序用例,因为它们通常关注给定时间窗口内的数据,而不是固定数量的样本。
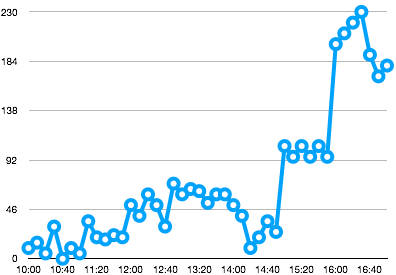
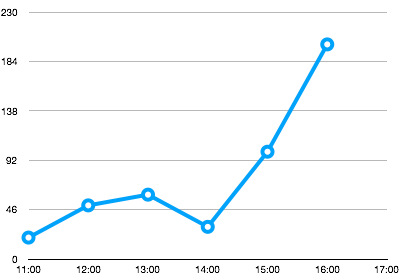
下采样/压缩
| 下采样前 | 下采样后 |
|---|---|
|
|
如果您想无限期地保留所有原始数据点,您的数据集会随时间线性增长。但是,如果您的用例允许您保留时间更久远但粒度较低的数据,则可以应用下采样。这允许您通过使用给定的聚合函数聚合给定时间窗口内的原始数据来保留较少的历史数据点。时序支持下采样,支持的聚合函数包括:avg、sum、min、max、range、count、first 和 last。
二级索引
使用 Redis 核心数据结构时,只能通过知道持有该时序的确切键来检索时序。不幸的是,对于许多时序用例(例如根因分析或监控),您的应用程序不会知道它正在查找的确切键。这些用例通常希望查询一组在多个维度上相互关联的时序,以提取所需的洞察。您可以使用核心 Redis 数据结构创建自己的二级索引来帮助实现此目的,但这会带来高昂的开发成本,并且需要您管理边缘情况以确保索引的正确性。
Redis 会根据称为标签的字段值对为您完成此索引。您可以为每个时序添加标签,并在查询时使用它们进行过滤。
这里是一个创建带有两个标签(sensor_id 和 area_id 分别是值为 2 和 32 的字段)且保留窗口为 60,000 毫秒的时序的示例:
TS.CREATE temperature RETENTION 60000 LABELS sensor_id 2 area_id 32
读取时的聚合
当您需要查询时序时,如果您只对给定时间间隔内的平均值等感兴趣,流式传输所有原始数据点会非常麻烦。时序仅传输最低限度所需的数据以确保最低延迟。
这里是一个对 5,000 毫秒时间桶进行聚合的示例:
127.0.0.1:12543> TS.RANGE temperature:3:32 1548149180000 1548149210000 AGGREGATION avg 5000
1) 1) (integer) 1548149180000
2) "26.199999999999999"
2) 1) (integer) 1548149185000
2) "27.399999999999999"
3) 1) (integer) 1548149190000
2) "24.800000000000001"
4) 1) (integer) 1548149195000
2) "23.199999999999999"
5) 1) (integer) 1548149200000
2) "25.199999999999999"
6) 1) (integer) 1548149205000
2) "28"
7) 1) (integer) 1548149210000
2) "20"
集成
Redis 开源版集成了现有的多个时序工具。其中一个集成是我们的 RedisTimeSeries 适配器,用于 Prometheus,它将您所有的监控指标保存在时序中,同时利用整个 Prometheus 生态系统。
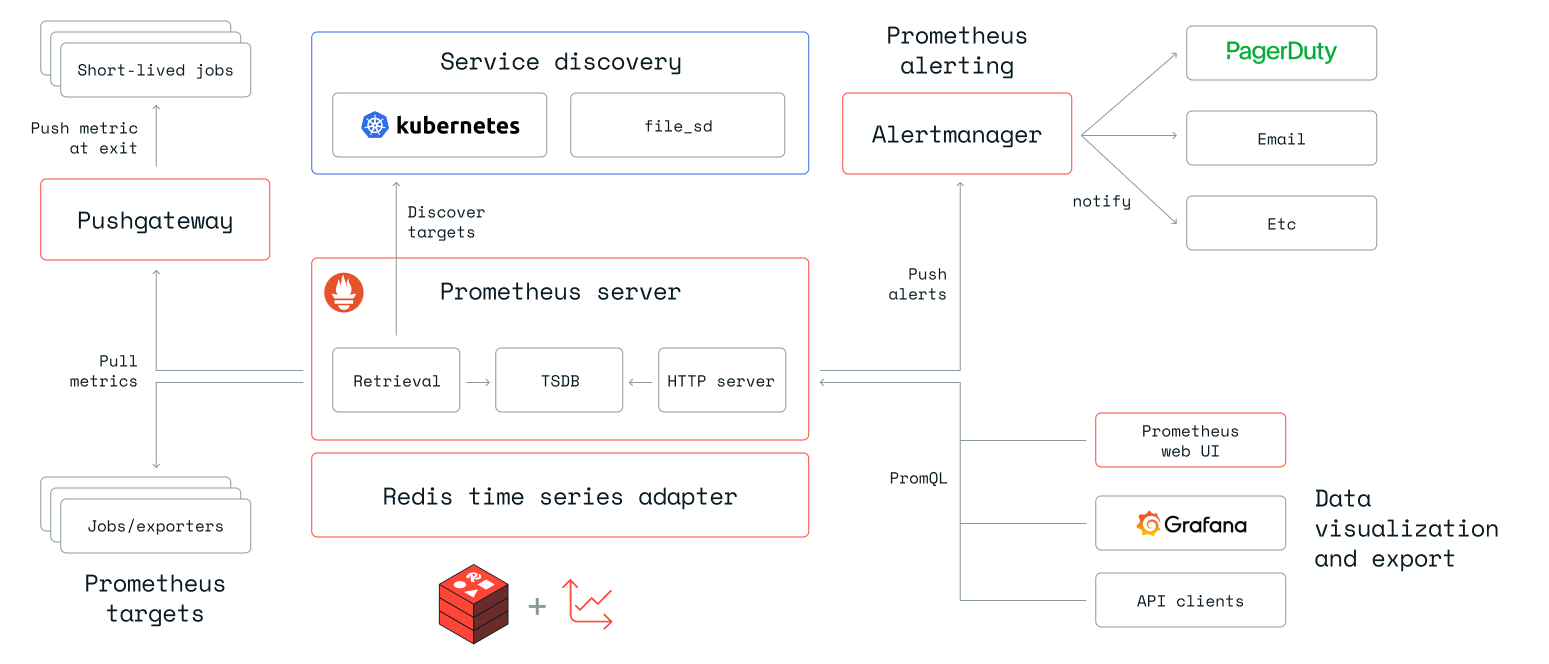
此外,我们还为 Grafana 创建了直接集成。此仓库包含 RedisTimeSeries、其远程写入适配器、Prometheus 和 Grafana 的 docker-compose 设置。它还附带了一组数据生成器和预构建的 Grafana 仪表盘。
使用 Redis 进行时序建模的方法
数据建模方法
Redis Streams 允许您在给定时间戳的消息中添加多个字段值对。对于每个设备,我们收集了 10 个指标,这些指标在单个流消息中被建模为 10 个单独的字段。
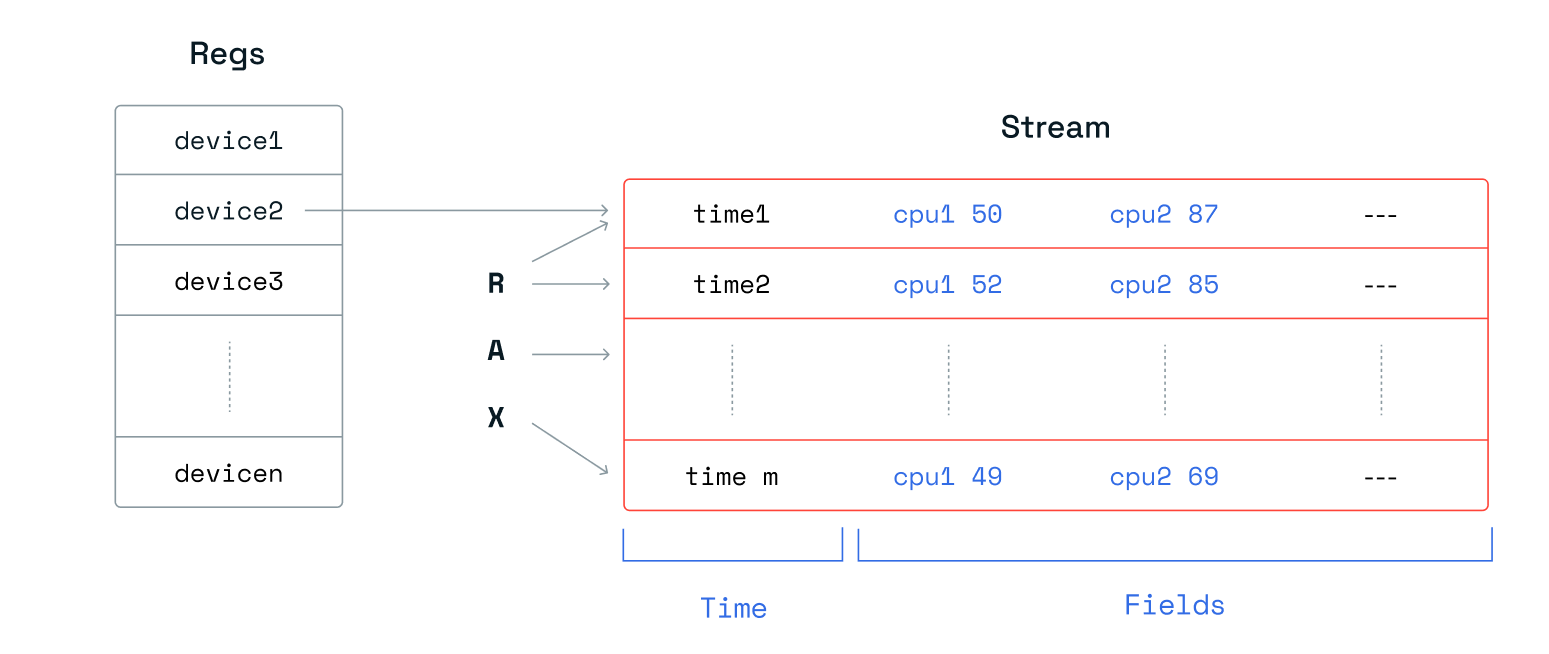
对于有序集合,我们以两种不同的方式对数据进行建模。对于“每个设备的有序集合”,我们将指标连接起来,并通过冒号分隔开,例如“<timestamp>:<metric1>:<metric2>: … :<metric10>”。
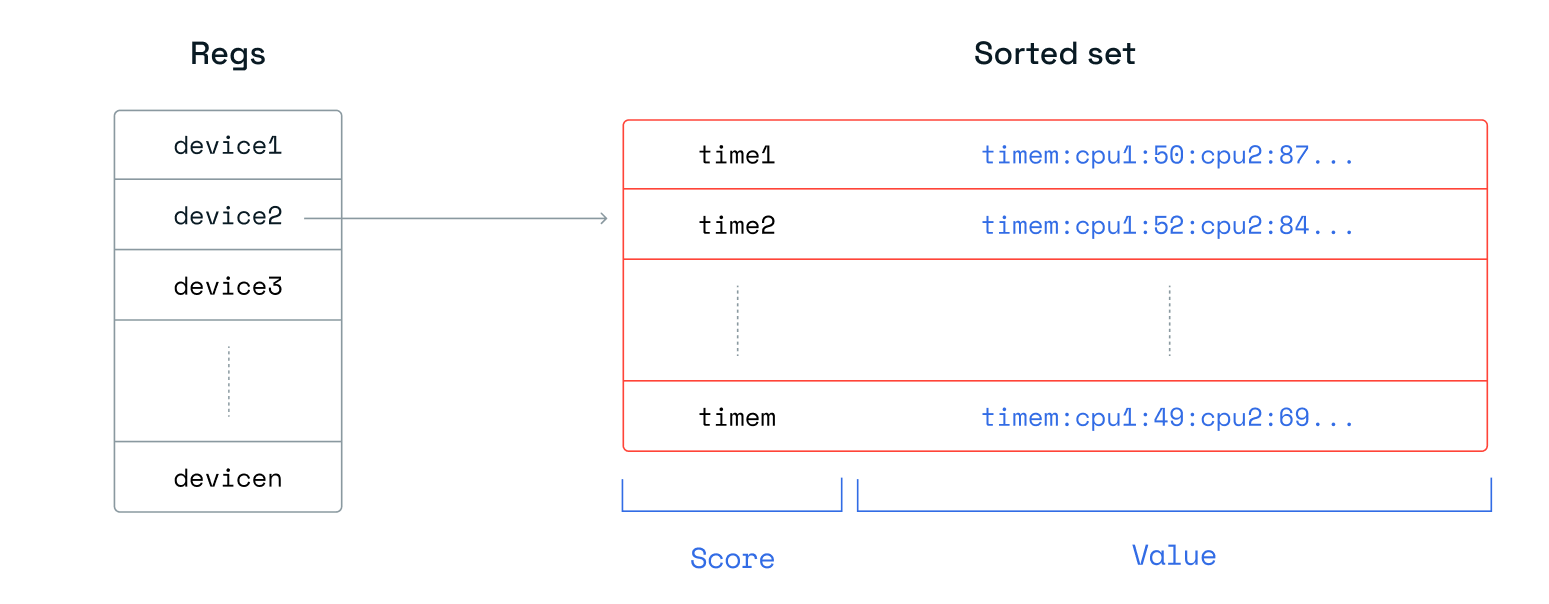
当然,这消耗的内存较少,但在读取时需要更多的 CPU 周期才能获得正确的指标。这也意味着更改每个设备的指标数量并不简单,因此我们也对第二种有序集合方法进行了基准测试。在“每个指标的有序集合”中,我们将每个指标保存在其自己的有序集合中,每个设备有 10 个有序集合。我们以“<timestamp>:<metric>”格式记录值。
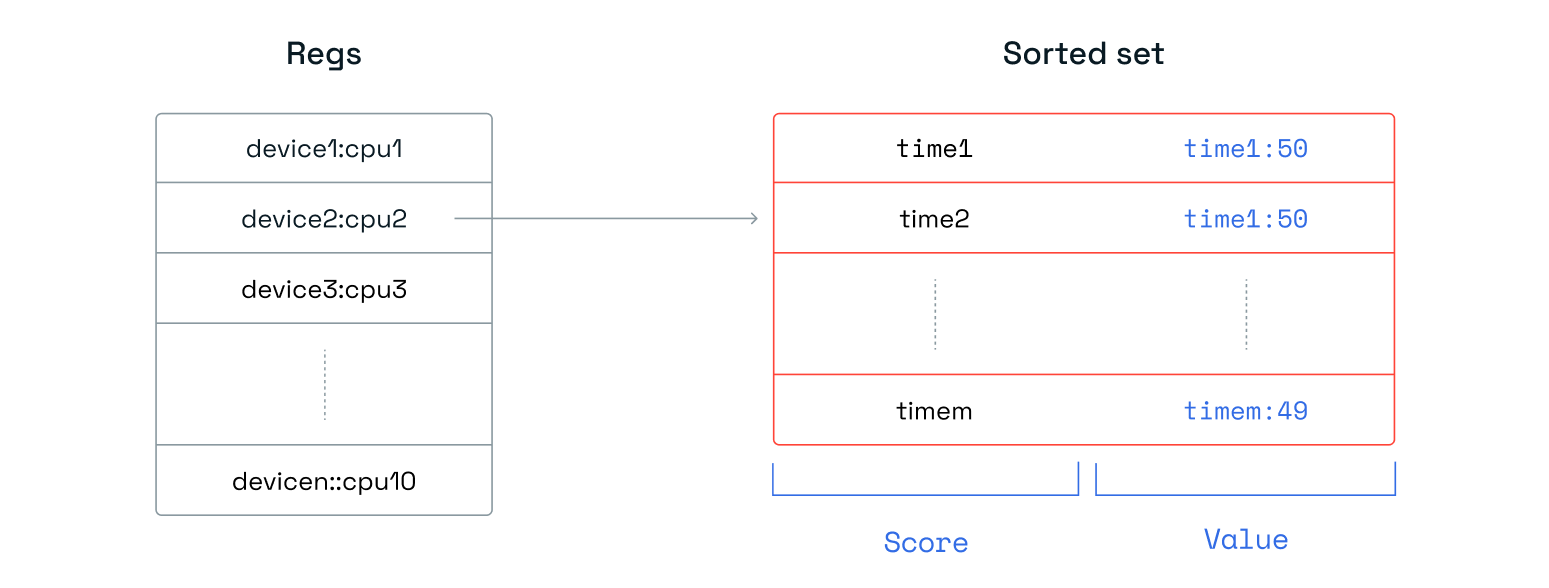
另一种替代方法是创建一个具有唯一键的哈希来规范化数据,以跟踪给定设备在给定时间戳的所有测量值。该键随后将成为有序集合中的值。然而,访问许多哈希来读取时序会带来巨大的读取时间成本,因此我们放弃了这种方法。
每个时序仅包含一个指标。我们选择这种设计是为了遵循 Redis 的原则:少量大键不如大量小键。
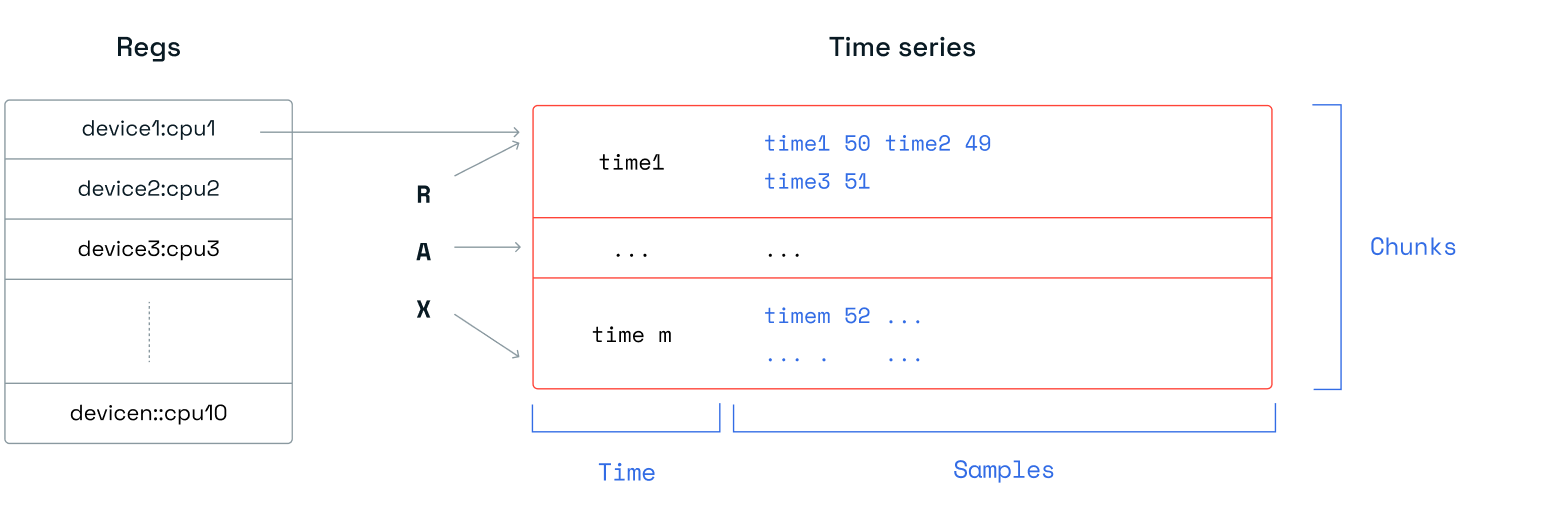
我们的基准测试没有利用时序开箱即用的二级索引功能。Redis 在每个分片中保留一个部分二级索引,由于索引继承其索引键的相同哈希槽,因此它始终托管在同一分片上。这种方法会使原生数据结构的设置更加复杂,因此为了简单起见,我们决定不在基准测试中包含它。此外,虽然 Redis Enterprise 可以使用代理将 TS.MGET 和 TS.MRANGE 等命令请求分发到所有分片并聚合结果,但我们在基准测试中也没有利用这一优势。
数据注入
对于基准测试的数据注入部分,我们通过测量每秒可以注入多少设备的数据来比较这四种方法。我们的客户端有 8 个工作线程,每个线程有 50 个连接,每个请求有 50 个命令的管道。
每种方法的注入详情
| Redis Streams | 时序 | 有序集合 每个设备 |
有序集合 每个指标 |
|
|---|---|---|---|---|
| 命令 | XADD | TS.MADD | ZADD | ZADD |
| 管道 | 50 | 50 | 50 | 50 |
| 每个请求的指标数 | 5000 | 5000 | 5000 | 500 |
| # 键 | 4000 | 40000 | 4000 | 40000 |
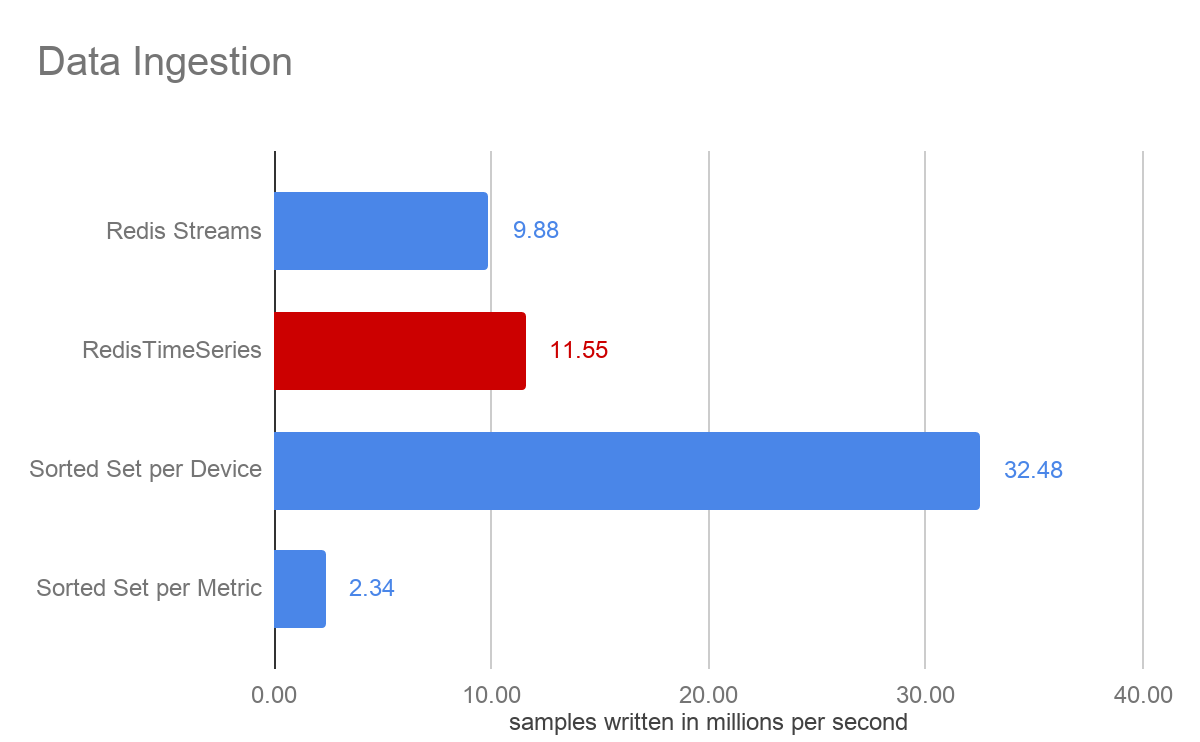
我们所有的注入操作都在亚毫秒级延迟下执行。尽管两者都使用了相同的 Rax 数据结构,但时序方法的吞吐量略高于 Redis Streams。
每种方法都会产生不同的结果,这表明针对特定用例进行原型设计很有价值。正如我们在查询性能中看到的那样,每个设备的有序集合提高了写入吞吐量,但牺牲了查询性能。这是注入、查询性能和灵活性之间的权衡(记住前面关于数据建模的说法)。
读取性能
我们在此基准测试中使用的读取查询查询单个时序,并通过保留每个时间桶中观察到的最大 CPU 百分比,将其聚合到一个小时的时间桶中。我们在查询中考虑的时间范围恰好是一个小时,因此返回单个最大值。对于时序,这是开箱即用的功能。
127.0.0.1:12543> TS.RANGE cpu_usage_user{1340993056} 1451606390000 1451609990000 AGGREGATION max 3600000
对于 Redis Streams 和有序集合方法,我们创建了以下 LUA 脚本。客户端再次拥有 8 个线程和每个线程 50 个连接。由于我们执行了相同的查询,因此只命中了一个分片,并且在所有四种情况下,该分片都达到了 100% 的 CPU 利用率。
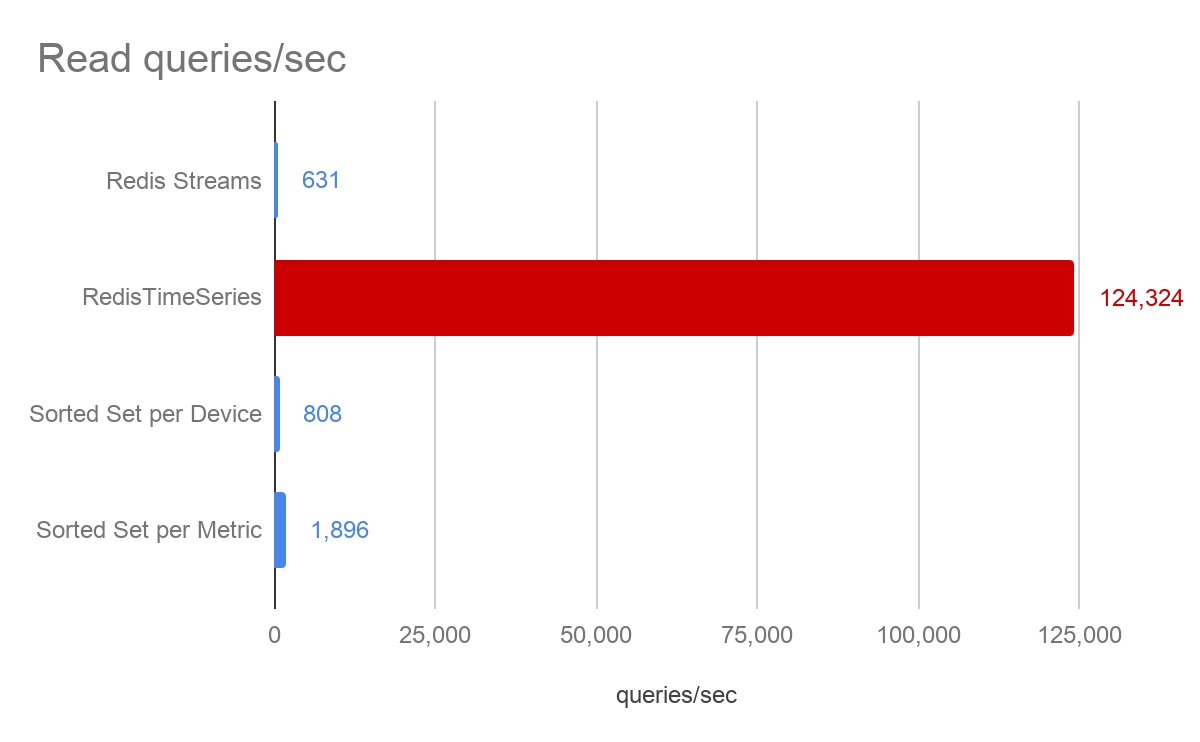
这就是您可以看到针对给定用例拥有专用数据结构并附带工具箱的真正强大之处。使用时序超越了所有其他方法,并且是唯一能够实现亚毫秒级响应时间的方法。
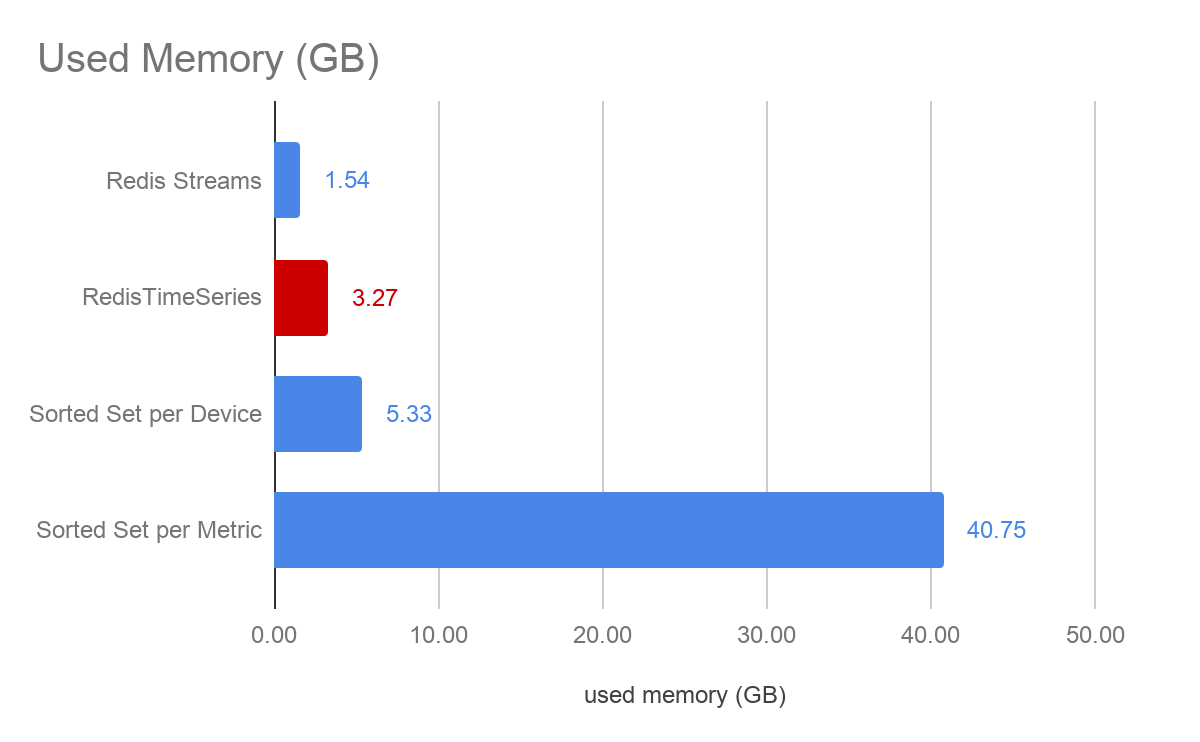
内存利用率
对于 Redis Streams 和有序集合方法,样本存储为字符串,而时序存储为双精度浮点数。在这个特定的数据集中,我们选择了介于 0-100 之间的舍入整数值的 CPU 测量,因此作为字符串消耗两个字节的内存。使用时序,每个指标具有 64 位精度。
与两种有序集合方法相比,时序可以显著减少内存消耗。考虑到时序数据的无界性,这通常是一个关键的评估标准 - 需要保留在内存中的总数据集大小。Redis Streams 会进一步降低内存消耗,但在需要更高精度的更多数字时,其内存消耗会等于或高于时序。