 Redis 8 来了——它是开源的
Redis 8 来了——它是开源的

视频

无模式数据库:优缺点
了解更多

性能问题会让用户感到不爽——如果他们还愿意留下来使用你的软件的话。因为如果你的软件太慢,它有多酷就不重要了。幸运的是,内存数据库解决了许多此类问题。
每个人都期望实时信息和个性化的在线体验,尤其是你的客户和最终用户。用户丧失信心的首要原因是什么?网站太慢。或者数据加载时间过长。或者任何其他促使用户点击离开(通常是去竞争对手的网站)的恼人因素。
如果组织提供的性能未能达到最佳水平,他们就会失去客户忠诚度。根据客户体验供应商 Emplifi 对 2000 名消费者的全球调查报告,仅经历两到三次糟糕的客户体验后,86% 的消费者就会放弃他们曾经忠诚的品牌。
这使得开发者迫切需要让在线应用在规模化时表现出色。这可能是一个重大挑战;当数据需求超出预期时,实时数据可能难以提供。而且调整数据库也并非总是万能的解决方案。
数据库性能下降的方式有很多种。这三个问题是其中最突出的——而且所有这些问题都可以通过内存数据库解决。
很难找到一个应用,其数据库访问速度“还行,凑合”就能被接受。几乎所有应用都需要即时响应客户请求——无论用户认为“即时”是多快。
然而,客户数据库在容量和表大小上稳步增长,传统的数据库管理实践难以跟上。“大数据”过去在计算机科学中代表着异常值,是数据集合中的庞然大物,但昨天的“巨大”数据库到了今天已经变得“稀松平常”了。正如开发者所发现的,庞大的数据集(以容量、速度和/或多样性衡量)需要可伸缩的架构才能进行高效的存储、操作和分析。
随着客户数据库的增长,按单个唯一标识符查询数据库变得更加困难。查询性能低下阻碍了客户服务。这也使得实施旨在为公司所有人以及客户自己提供准确、单一客户视图的客户360°计划变得更加困难。缓慢的数据库查询无法为实时数据操作提供足够的时间来创建富有洞察力的聚合数据视图。
解决方案:将客户查找表及其他与客户相关的数据表迁移到内存数据库。
内存数据库的工作方式与其他数据库类似,但所有数据都存储在DRAM中,而不是传统磁盘上。数据会定期存储到磁盘上,以实现持久性和数据恢复(如果需要)。
内存数据库显著提升了性能,因为无需花费时间写入磁盘或从磁盘读取。内存操作的速度比基于磁盘的驱动器快许多倍,甚至比更新的NVMe或SATA固态硬盘驱动器还要快得多。
简而言之:内存数据查询具有低延迟,这意味着代码可以伸缩。这意味着应用程序可以搜索数千万条客户记录,以查找与单个客户相关的信息,并实时获取结果。
搜索和查询的性能会根据执行的数据操作而发生显著变化。要了解数据操作如何影响 Redis 与其他数据库的查询性能,请参阅这篇性能比较博客文章。
数据库性能不仅仅涉及数据检索来提供客户记录或存储交易。组织利用实时数据库查询来支持业务指标背后的分析,例如项目仪表盘和故障排除警报——任何能促使做出更好选择的数据呈现形式。
对于分析而言,数据的时效性与其质量直接相关。陈旧过时的数据对于实时分析和决策的价值较低。
导致查询性能问题的瓶颈可能出现在数据操作流程的任何地方。数据库搜索和查询操作在计算上是昂贵的。索引和交付搜索结果需要大量资源。
同时进行数据摄取和查询不同的数据结构(如Hash和JSON文档)要求很高。对于基于磁盘的SQL数据库(例如Oracle和SQL Server)来说尤其如此。典型的解决方案是数据库性能调优,但这受限于底层数据库架构和数据库工作负载类型,其效果有限。
解决方案:采用实时搜索引擎来快速提供数据结果用于分析。
实时搜索引擎查询和聚合海量数据集并立即返回结果,为准确的分析生成及时的数据。数据科学家随后可以在仪表盘、图表、图形或其他应用程序中获取和分析这些新鲜数据。
在我上一篇关于模糊匹配的文章中,我更详细地探讨了数据搜索算法及其背后的炫酷数学和科学知识。
实时搜索引擎提供
此图描绘了将来自多个记录源的数据整合到一个实时搜索引擎中,从而为分析和新的商业洞察提供及时的数据
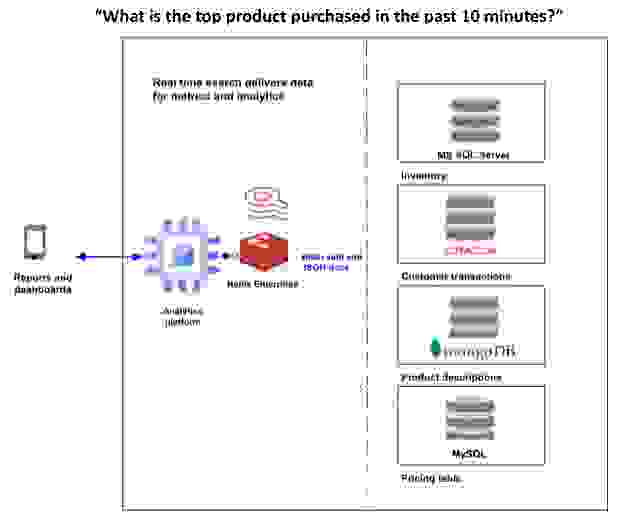
另一个常见的数据库问题是在庞大的主数据表上执行重复查找。主数据表有助于定义数据库中的重要实体,通常代表其基础:产品、合作伙伴、供应商和订单。与任何其他数据管理元素一样,这些表随着公司的发展而增长。
当主数据表达到数百万主键或二级索引值时,数据库重复执行大型主数据表查找会导致性能问题。常见症状是用户搜索明显缓慢或应用程序页面呈现延迟,尤其是在为电商网站搜索庞大产品数据库时。
解决方案:将数据摄取、索引和查询负载分配到数据库分区或分片上,并使用二级索引。
地理分布式数据库拓扑可以将主数据表扩展到数千万主键和二级索引。这实现了强大的搜索自动建议和灵活的基于类别的(分面)搜索功能,为在线客户和业务用户提供即时搜索结果。 在多个数据库分区或分片之间分发读写操作,可以实现主数据表的大规模扩展和高性能搜索结果。
二级索引是非主键索引,用于提供快速数据查找。它们的搜索结果可能包含重复值,例如查找制造商为“Apple”的所有产品。数据库的二级索引允许在任何数据库字段中灵活快速地搜索主数据表。您可以为一个记录创建数千个索引,或者在整个数据库中创建数十万个索引。一旦创建索引,数据库就会提供自动索引管理。
我们在其他地方更深入地介绍了二级索引和有序集合。
Redis Enterprise 为实时数据提供强大的索引、查询和全文搜索引擎,可用于本地部署和云上的托管服务。Redis搜索引擎可用于实时客户聚合、作为Redis中托管数据的二级索引、整合来自其他数据存储的数据用于分析,并作为快速的全文搜索或自动完成引擎。
并且——考虑到以上几点,这不会让您感到惊讶——Redis Enterprise 实时搜索引擎克服了常见的数据库性能问题
我们希望这能激发您的兴趣,以便您了解更多并确定 Redis Enterprise 是否适合您的需求。当然,我们提供了大量信息来帮助您深入了解,例如关于数据摄取的网络研讨会、关于实时搜索的网页以及一段讲解如何创建二级索引的视频。
现在是时候探索实时搜索的强大功能了。与 Redis 专家交流或免费下载 Redis Enterprise。立即开始,利用 Redis Enterprise 的实时搜索能力,为您的客户和业务伙伴提供有价值的新鲜数据。

