 Redis 8 发布了——而且是开源的
Redis 8 发布了——而且是开源的

视频

您可能不知道的 Redis 的 5 件事
了解更多



Redis Enterprise 的 Active-Active 地理分布和 Google Cloud Spanner 的复制协同工作,为地理分布式应用提供统一的实时数据层。 下面介绍它们如何连接以及该技术提供的优势。
设计和开发地理分布式应用可能很复杂。 跨多个地理位置的应用有多种要求,有时这些要求会相互妨碍。 地理分布式应用需要在远距离上实现高可用性、弹性、合规性和性能。
确保跨多云区域的这些数据库系统中的数据一致性应该是底层数据库技术的一项关键特性。 并且不应该是开发人员需要关心的问题。
在这篇博文中,我们将讨论 Redis Enterprise 的 Active-Active 地理分布 和 Google Cloud Spanner 的复制 的结合,它们共同为地理分布式实时应用提供了一个弹性、全局一致的数据层。
Cloud Spanner 是一项完全托管的数据库服务。 它是 Google Cloud 为大众带来基于 ACID 的一致性、SQL 关系数据库功能以及地理位置之间同步复制的努力的一部分。 Cloud Spanner 支持关键任务应用,并通过提供全局范围内的事务一致性、模式、SQL (带扩展的 ANSI 2011) 以及自动、同步复制来实现五九 SLA 高可用性。
数据层通常由多种数据库技术组成。 它们可能包括用作前端缓存的内存数据库,以提高速度和性能,以及传统的关联数据库或 NoSQL 数据库,以在后端记录系统中持久化数据。
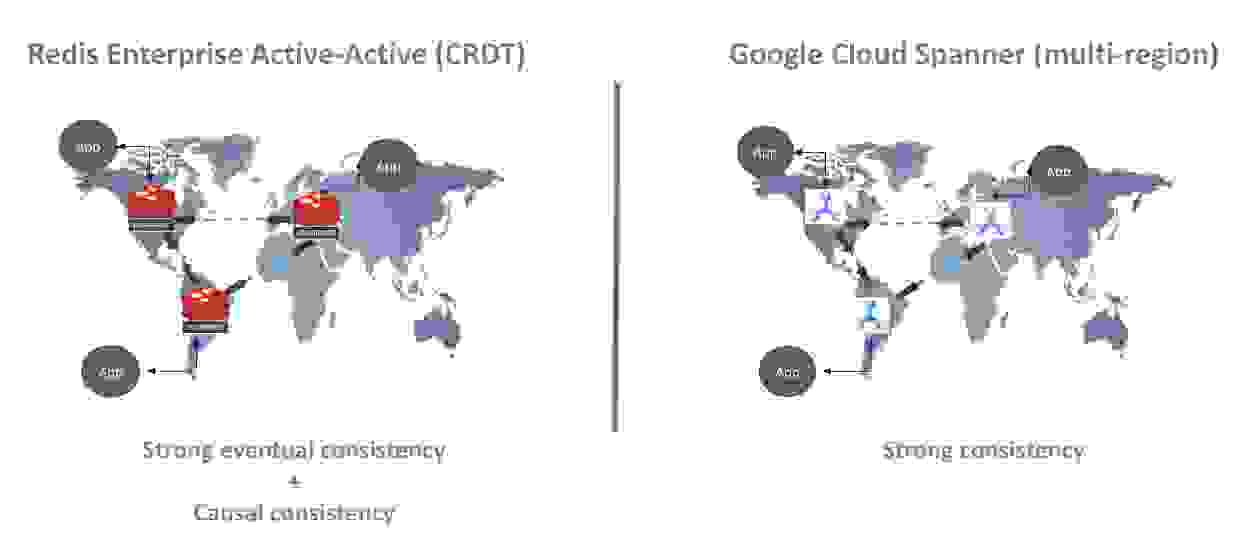
Redis 开源很强大,但在各种企业级功能(如多区域部署)方面有所欠缺,尤其是在将其用作多区域 Cloud Spanner 拓扑的前端缓存时。
如下图所示,部署在两个不同地理区域(us-east1 和 us-west1)中的应用在发生同时缓存读取和写入时可能会表现异常。
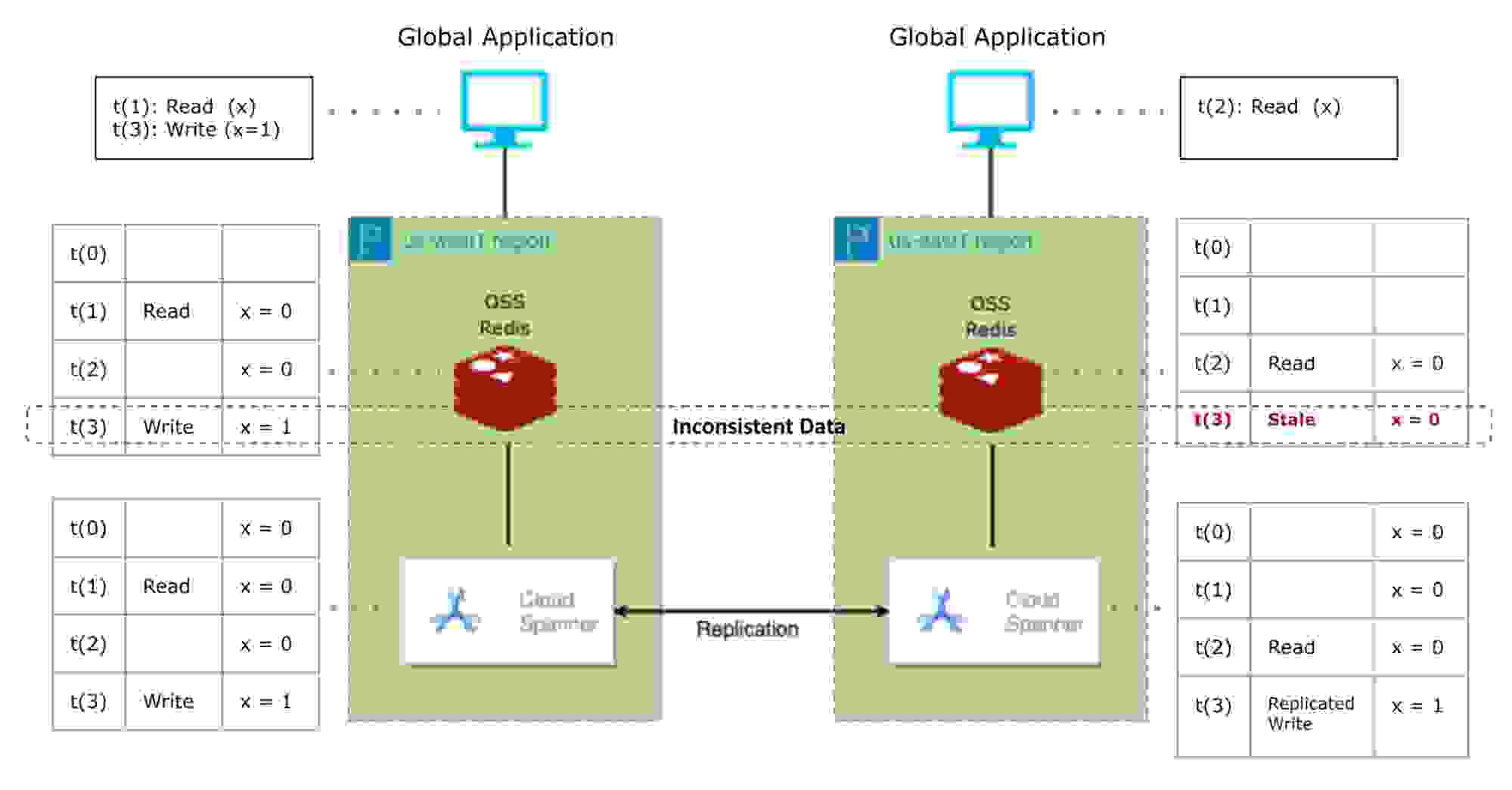
假设此应用架构旨在支持全球分布式实时事件预订和售票系统。 过时的信息可能会导致业务损失和糟糕的客户体验。
这不是一个假设的例子。 不久前,一家票务服务提供商因其系统根据过时的信息采取行动而遭受重大挫折。 因此,由于用于正确动态定价计算的可用门票数量不一致,来自不同地区的音乐会观众收到了人为制造的票价。
这怎么会发生? 这是流程。
假设一场热门音乐会即将举行,比如 Ariana Grande 的演唱会。 美国西部和美国东部数据库都列出了库存中正确的票数。 到目前为止,一切都很好。
但随后出现了缓存不匹配。 西海岸的某人购买了 20 张门票,但东海岸数据库没有收到更新。 西海岸数据库显示有 80 张门票可用,但东海岸仍然显示 100 张。
如果没有人购买门票,这没什么大不了的。 但这是 Ariana Grande 的演唱会,所以你知道门票会被抢购一空。
在我们的 cache-aside 示例中,us-east1 区域中的 Redis OSS 实例中 x 的值具有过时的可供销售门票值(仍然是 100 个座位)。 现在,当东海岸的某人试图购买那些座位时,us-east1 区域中对 x(可供销售的门票)的下一次读取操作会出现问题。 这是因为即使两个区域中的 Cloud Spanner 实例都具有正确的值,x 仍然具有旧的和过时的值。
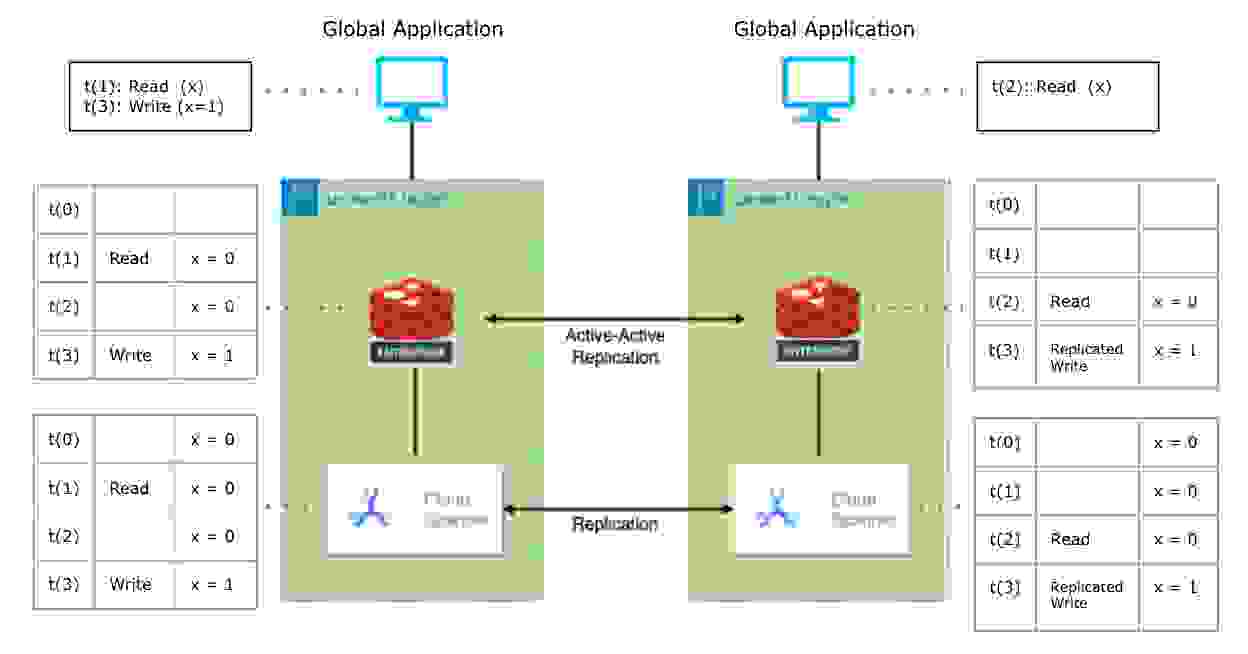
有了我们的解决方案,这种情况就不会发生。 我们俩保持同步。 没有人需要哭泣——或者在演唱会上为那些座位醉酒打架。
由于原生支持主动-主动地理复制,Redis Enterprise 可以解决此问题。 使用此功能,Redis Enterprise 可以用作跨区域分布式缓存,以确保跨区域的数据一致性。 这保证了缓存层和记录系统中的更强一致性。
更好的是:使用 Redis Enterprise 的原生 Active-Active Geo-Duplication 不需要额外开发工作。 每个 Redis Enterprise 集群都支持本地读写操作,延迟低于一毫秒,并且与每个云区域中的底层 Cloud Spanner 实例和谐地工作。 无需您进行任何特殊操作,数据会自动在 Redis Enterprise 集群之间复制。 频繁的数据读取访问被卸载到 Redis Enterprise,以提高应用响应时间并优化整体数据访问成本。
更重要的是,Google Cloud Marketplace 中的 Redis Enterprise 的 Active-Active 功能支持与 Cloud Spanner 在多区域部署中一样的五九 SLA。 最终结果? 更好的性价比,没有维护停机时间。
Active-Active 地理分布是通过在 Redis Enterprise 中使用跨多个集群和无冲突复制数据库 (CRDB) 的全局数据库来实现无冲突复制数据类型 (CRDT) 来实现的。
您可以在不同的行业中使用这种部署拓扑来解决众所周知的问题。 例如:
自 2017 年成立以来,零售、金融服务 和 游戏 行业的客户一直使用 Cloud Spanner 来支持需要强大一致性和无限可扩展性的应用。 诚然,这就是一切。
其中一个例子是零售业,自从 Pizza Hut 在 1994 年建立第一个在线订购网站以来,电子商务一直在重塑自我。 COVID-19 大流行迫使零售商重新思考零售商如何联系和服务客户,例如 快速实施路边交付系统。 尽管在线购买有所增加,但购物者希望获得实时响应。
这些商业努力需要一个软件基础来构建新的零售功能。 新的参与者正在通过支持 微服务架构、API 优先、云原生和无头 (MACH) 原则的无头电子商务平台来民主化电子商务软件堆栈。 并且它必须跨所有地理区域工作,从零售商仓库到支持其库存的供应链。
金融服务业也有 其自身的挑战,例如不断变化的监管要求、网络安全问题和业务模式调整——每一个都会影响技术预算。 银行机构、金融科技和监管机构之间的互动必须完美无缺。
同样,该行业必须响应不断增长的需求。 根据世界银行的数据,疫情 增加了数字支付的使用。 根据该报告,目前全球约有三分之二的成年人进行或接收数字支付,发展中经济体的这一比例从 2014 年的 35% 增长到 2021 年的 57%。
视频游戏行业是健康且不断增长的——但它也必须应对 市场变化,例如 COVID 锁定前后支出习惯的变化。 同样,推出超级热门游戏(例如 Splatoon 3)的公司对底层应用基础设施平台提出了技术挑战。 支持在全球范围内推出一款拥有数百万在线玩家、多人游戏支持和游戏内购买的游戏需要大量的计算能力。
Redis 在这三个行业以及更多行业中得到了广泛应用。 企业功能提供了构建能够满足用户需求的软件所需的数据模型。 无论它是利用原生数据结构(如字符串、集合和哈希)作为存储应用数据的简单缓存,使用哈希存储用户个人资料,使用排序集跟踪在线销售活动期间的前 10 名消费者,使用哈希来外部化微服务架构中的会话,使用集合或哈希来跟踪用户的购买行为,都是如此。 可能性是无穷无尽的,因为手头的业务需求激发了 Redis Enterprise 的力量并推动了它的消费。
例如,RedisJSON 可以与 RediSearch 一起使用,在零售应用程序中对产品目录、购物车和订单详情进行建模。它们还可以对零售银行账户、交易应用程序中的证券投资组合以及零售银行应用程序的被提名人详细信息进行建模。在游戏中,JSON 和搜索模块的相同组合可用于存储玩家的游戏库存、玩家个人资料和玩家匹配数据。
一家著名的 Google Cloud 客户正在使用 Redis Enterprise 存储用户信息和应用程序关键数据,并将 Google Cloud Spanner 作为部署在两个区域中的主存储。通过在多区域拓扑中部署 Spanner 和 Redis Enterprise,他们实现了两个目标:为组织分布式工作负载提供全局数据存储和缓存引擎,以及解决灾难恢复问题,实现超快故障转移时间、降低复杂性以及最佳的恢复点目标 (RPO) 和恢复时间目标 (RTO) 保证。
横向扩展和横向缩减过程也是无缝的。通过添加新节点,即使在黑色星期五等高需求时期,也可以将每秒请求数从 10 万扩展到 100 万。您只需为您使用的容量付费。
我们提供了关于 Redis Enterprise 的 Active-Active 地理分布 和 Google Cloud Spanner 的大量信息。要了解您当前缓存策略的状态,请进行 五分钟评估 以获得实用建议。

