 Redis 8 来了——并且是开源的
Redis 8 来了——并且是开源的

视频

你好,Redis Stack
了解更多

使用 Redis Stack 构建多模型应用程序出乎意料地简单!跟随本教程学习如何在 Python 中构建一个包含强大搜索功能的知识库。
公司每天产生大量数据。组织数据、过滤掉过时的信息并在需要时随时提供这些信息是一项巨大的挑战。这不是一个小问题。
理解数据的含义与存储数据不同。实现该目标包括记录数据的组织方式,以及创建、编辑、审查和发布数据的过程,同时了解编辑者和消费者之间的关系。
知识库系统充当有关产品、服务、部门或主题的信息库。在这样的系统中,文档是动态资产,可以被引用、改进、分类、共享或对未经授权的用户隐藏。典型的例子包括常见问题解答数据库、操作指南和新员工入职材料。知识库应根据公司的需求进行定制,这意味着它需要与现有工具和流程进行交互。
互联网使知识库系统变得流行。文档可以使用超文本进行结构化和连接,这是互联网本身的核心思想。以这种方式组织和链接内容永远改变了生产者和消费者从知识中创造价值的方式。
在本文中,我将演示如何使用 Redis 的数据结构和搜索功能来构建具有基本功能的 Web 知识库平台。该项目非常适合利用 Redis 强大的实时全文搜索和查询功能,因为它满足了此类系统的主要目的:提供多种方法来检索消费者正在寻找的信息并尽快提供。
本教程可帮助您构建一个知识库,该知识库可以存储和服务于典型用例的文档,例如想要了解新产品功能、解决技术问题或作为内部部门的单一可靠信息来源的客户。
该项目的源代码 可在 GitHub 存储库中找到,该存储库已获得 MIT 许可。
我将此项目命名为“Keybase”,这是它的预览

在本教程中,我使用以下组件来开发一个可行的原型
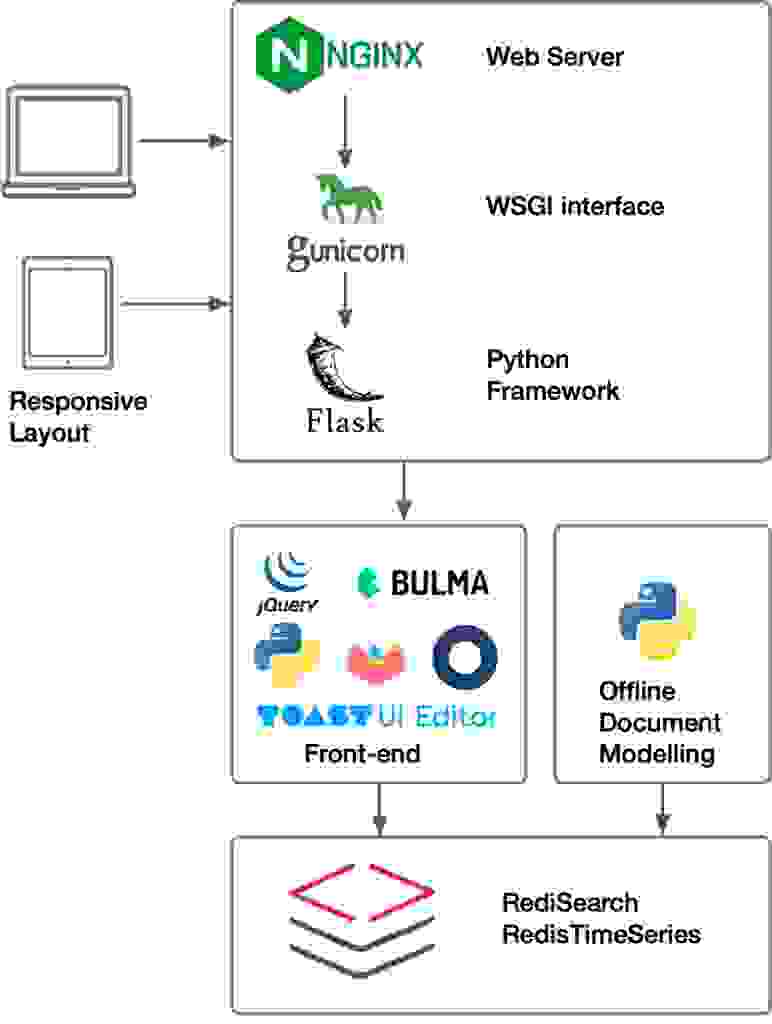
流行的 Nginx Web 服务器与 Gunicorn 一起使用,后者实现了 Web 服务器网关接口并为 Flask 应用程序提供服务。
知识库后端是作为在流行的 Flask 框架上开发的 Python 应用程序实现的。 Flask 在视图之间提供了良好的分离。该应用程序是使用 Jinja 模板引擎和由 Werkzeug WSGI 工具包提供的控制器实现的。用户身份验证基于 Okta,这是一个流行的身份即服务平台。
前端使用 CSS 框架 Bulma 进行样式设置; JQuery 是用于 Ajax 通信和用户界面操作的 Javascript 库,以及 JQueryUI,Notify.js 用于 UI 通知。
另一项服务,作为 cron 作业部署,索引文档以进行文档相似性推荐。为了避免影响用户体验,文档索引与会话方便地分离。
最后,在数据层中,该项目使用 Redis 数据库以及两个 Redis 模块:RediSearch 和 RedisTimeSeries,在本教程中,我分别使用它们进行文档索引和搜索以及分析。
知识库中的文档被建模为哈希。以下是数据的存储方式:
HGETALL keybase:kb:9c6c48c2-eb5d-11ec-893a-42010a000a02
1) "update"
2) "1655154783"
3) "processable"
4) "0"
5) "tags"
6) "troubleshooting"
7) "state"
8) "draft"
9) "owner"
10) "00u5brr84hIXBoDRo5d7"
11) "name"
12) "How to Troubleshoot Performance Issues?"
13) "content_embedding"
14) "\xf5\xcc\x1e=D\x82\xd0\xbc\x81\x90\xfa\xbc5&\xab<\x98\xaa\xb0=;`\xf2\xbc\xc1\x00Z\xbb9\xe4\xee\xbc\xee\x88\xce9\xd8^\x80\xbclX\xe0\xbc\a\xaf\x9a\xbdTR\xd8<\xb6Yv=w6^=\x1ftd\xbd M\x19\xbd&BP=\x04\x92\\\xbd@\xb6P=\xd7\xce\x12\xbc\x11" [...]
15) "creation"
16) "1655154783"
17) "content"
18) "Checklist to investigate performance issues.\n\n1. Check slow log looking for\xc2\xa0 `EVALSHA`, `HGETALL`, `HMGET`, `MGET`, and all types of `SCAN` commands. Lower slow log threshold to capture more slow commands. You can configure the threshold using `CONFIG SET slowlog-log-slower-than <THRESHOLD_MICROSECONDS>`\n2. Avoid the" [...]
哈希数据结构存储
都了解了吗?我们准备好深入了解 Keybase 的功能以及如何实现它们了。
我们对 Redis 数据库强大的实时搜索功能感到非常自豪;本教程让我们展示它。
您可能认为搜索是一种暴力查找,但实际上,当我们使用 RediSearch 索引功能时,没有缓慢的扫描。我们在这里简要介绍的选项是
有关 Redis 中搜索功能的更深入解释,请参见 RediSearch 模块的简介。
RediSearch 使用以下语法创建索引
FT.CREATE document_idx ON HASH
PREFIX 1 "keybase:kb"
SCHEMA name TEXT
content TEXT
creation NUMERIC SORTABLE
update NUMERIC SORTABLE
state TAG
owner TEXT
processable TAG
tags TAG
content_embedding VECTOR HNSW 6 TYPE FLOAT32 DIM 768 DISTANCE_METRIC COSINE
索引 document_idx 的架构使用相应的字段类型启用三种类型的搜索
Web 界面中的搜索输入字段用于执行全文搜索,该搜索会查找知识库文档的名称和内容。
考虑使用 redis-py 客户端库进行实时全文搜索的此示例。它对从客户端收到的 query 字符串执行搜索。请注意,此命令排除了 draft 状态的文档;此类文档必须保持隐藏,并且不包含在输出中
connection.ft("document_idx")
.search(Query(query + " -@state:{draft}")
.return_field("name")
.return_field("creation")
.sort_by("creation", asc=False)
.paging(offset, per_page))
这个简洁的代码示例执行实时全文搜索,并从指定的 offset 开始返回一批 per_page 文档(有助于在 UI 中分页文档)。它满足指定的搜索条件:满足用户在输入字段中提供的查询的所有文档,它删除了 draft 状态的文档,并按 creation 时间戳对文档进行排序。
在 Python 中按标签进行实时查询的一个示例,其中搜索与标签上的过滤器结合在一起,并且还排除了 draft 状态的文档,如下所示,它返回所有标记有“troubleshooting”标签的文档
connection.ft("document_idx")
.search(Query("@tags:{troubleshooting} -@state:{draft}")
.return_field("name")
.return_field("creation")
.sort_by("creation", asc=False)
.paging(offset, per_page))
这段代码是一个纯实时查询,包括使用 troubleshooting keyword 标记的所有文档,但也不包括那些不是公共的且仍被归类为私有草稿的文档。此语法使用多个字段上的索引来过滤、排序和分页结果。
您肯定熟悉这种搜索,尤其是在电子商务网站上。个性化推荐会将用户引导到类似内容,并显示诸如“您可能也有兴趣阅读”或“购买此商品的人也购买了”之类的提示。
此示例应用程序不需要增加产品销量,因为知识库站点没有任何东西可以出售,但我们确实希望为用户提供有意义的推荐。
您可以使用 Redis 实时搜索的 VSS 功能添加推荐。
如果您尚未在项目中使用过这种类型的搜索,请从 Rediscover Redis for Vector Similarity Search 开始。
简短说明:要使用 VSS 功能,您首先创建一个模型,然后存储它,最后查询它。
使用 VSS 进行推荐背后的核心概念是将文档内容转换为其对应的向量嵌入。向量是描述文档的实体,并与其他向量进行比较以返回最佳匹配项。向量嵌入存储在哈希数据结构中(在 content_embedding 值中)。
在这个例子中,我们使用 Python 的 SentenceTransformer 库来计算向量嵌入,使用的模型是 all-distilroberta-v1(来自 Hugging Face 数据科学平台),具体操作如下。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1')
embedding = model.encode(content).astype(np.float32).tobytes()
在这个示例中,文档的内容被向量化并以二进制格式序列化,VSS 接受的就是这种格式。此操作会触发两次:在创建文档时以及任何后续文档更新时。特别是,当更新文档内容时,需要重新计算向量嵌入,否则索引将过时并返回不精确的结果。 要触发离线向量嵌入重新计算(如架构中所述),只需激活 processable 标志,并定期列出那些需要刷新向量嵌入的文档,然后处理它们。例如:
rs = connection.ft("document_idx")
.search(Query('@processable:{1}')
.return_field("content")
.return_field("processable"))
if not len(rs.docs):
print("No vector embedding to be processed!")
sys.exit()
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1')
for doc in rs.docs:
# Recalculate the embedding and store it
使用与之前的标签搜索示例相同的语法,此命令执行搜索以包含那些将标签 processable 设置为 1 的文档。 此搜索返回的文档将重新计算并存储相关的向量。
生成向量嵌入后,您可以像往常一样将其存储在文档哈希数据结构中(在 content_embedding 字段中)。
最后,将 processable 标志设置为零。 在下次文档更改之前,不需要对向量嵌入进行进一步更新。
doc = { "content_embedding" : embedding, "processable":0}
connection.hmset("keybase:kb:{}".format(key), doc)
每次用户查看文档时,侧边栏都会提供推荐列表。 这意味着 Keybase 应用程序必须发现这些推荐是什么。
为了实现这一点,我们从当前显示的文档的哈希值中获取向量嵌入(即用户正在查看的文档)。
current_doc_embedding = connection.hget("keybase:kb:0373bede-d2c1-11ec-b195-42010a000a02", "content_embedding")
hget 返回与字段 content_embedding 相关联的值。
要检索最相似的文档,请将该向量与其余存储的向量进行比较。
q = Query("*=>[KNN 6 @content_embedding $vec]")
.sort_by("__content_embedding_score")
res = connection.ft("document_idx")
.search(q, query_params={"vec": current_doc_embedding})
for doc in res.docs:
# Show the documents in the box
在此示例中,查询配置为执行强大的向量相似性搜索,以通过检索 k 近邻 (KNN) 返回六个最相似的文档。
有关更多 VSS 语法示例,请参见客户端库文档。
每个业务应用程序都需要确定谁可以访问该软件,谁不能访问。 对于我们的知识库身份验证,我们使用流行的身份即服务平台 Okta。 用户在 Redis 数据库中存储为带有前缀“keybase:okta:”的哈希。 我测试了与 Okta Developer Edition 的集成。
这是一个用户配置文件的示例
127.0.0.1:6380> HGETALL keybase:okta:00u5clwmy9dGg6wPC5d7
1) "name"
2) "Test Account"
3) "given_name"
4) "Test"
5) "email"
6) "[email protected]"
7) "group"
8) "viewer"
9) "signup"
10) "1655510121.2172642"
11) "login"
12) "1655510121.217265"
要搜索知识库用户,我们在用户哈希数据结构上创建一个索引
FT.CREATE user_idx ON HASH PREFIX 1 "keybase:okta"
SCHEMA
name TEXT
group TEXT
该组正式确定了基于角色的访问控制 (RBAC) 的实现。 我为此示例应用程序创建了三种用户类型,但可以添加其他角色。 当前的角色是
最后,也可以通过将文档 ID 存储在集合中来收藏文档。 同样,哈希是最佳选择,因为它具有灵活性; 您可以存储文档 ID,还可以存储关于书签的个人评论。
这是一个经过身份验证的用户的集合示例
127.0.0.1:6380> HGETALL keybase:bookmark:00u5brr84hIXBoDRo5d7
1) "efb73056-d2c0-11ec-b195-42010a000a02"
2) "May solve several customer cases"
3) "0373bede-d2c1-11ec-b195-42010a000a02"
4) "TLDR"
5) "2f678872-d2c1-11ec-b195-42010a000a02"
6) ""
许多业务场景需要组织监控知识库的活动。 例如,您可能希望按主题领域评估文档的受欢迎程度,最大限度地减少重复问题或挖掘新功能创意。
RedisTimeSeries 功能是分析功能的自然选择,因为它经过优化可以存储和聚合大量数据。
跟踪对知识库的总体访问量的代码(作为示例)是
connection.ts().add("keybase:visits", "*", 1, duplicate_policy='first')
此代码计算过去一个月的访问量,按天聚合。 它被格式化为 JSON,随时可以提供给 Chart.js 可视化库
bucket = 24*60*60*1000
duration = 2592000000
ts = round(time.time() * 1000)
ts0 = ts - duration
# 86400000 ms in a day
# 3600000 ms in an hour
visits_ts = connection.ts()
.range("keybase:visits", from_time=ts0, to_time=ts, aggregation_type='sum', bucket_size_msec=bucket)
visits_labels = [datetime.utcfromtimestamp(int(x[0]/1000)).strftime('%b %d') for x in visits_ts]
visits = [x[1] for x in visits_ts]
visits_graph = {}
visits_graph['labels'] = visits_labels
visits_graph['value'] = visits
visits_json = json.dumps(visits_graph)
然后,要在 Jinja 模板中呈现图表,请使用此 Javascript
var data_js = {{ visits_json|tojson }};
const ctx = $('#visits');
const myChart = new Chart(ctx, {
type: 'bar',
data: {
labels: JSON.parse(data_js).labels,
datasets: [{
label: '# of Visits',
data: JSON.parse(data_js).value,
fill: false,
backgroundColor: 'rgba(203, 70, 56, 0.2)',
borderColor: 'rgb(203, 70, 56)',
borderWidth: 1
}]
},
options: {
responsive: true,
maintainAspectRatio: true,
scales: {
y: {
beginAtZero: true
}
}
}
});
图表在 HTML 画布元素中呈现。
<canvas id="visits"></canvas>
此方法允许您监控其他指标,例如每个文档的视图或用户活动。 您可以使用 Redis 时间序列聚合功能来计算平均值、方差、标准差和各种统计数据。
为了完善示例应用程序,我们需要确保可以管理知识库。
管理员可以使用 RBAC 策略授予或撤销用户的角色。 访问控制使用 Python 装饰器和自定义 User 类来实现。(有关详细信息,请参阅存储库。)
例如,执行备份的受保护方法的签名可能是
@admin.route('/backup', methods=['GET'])
@login_required
@requires_access_level(Role.ADMIN)
def backup():
# Take the backup
您可以使用异步 BGSAVE 命令以原生方式生成 Redis 数据库备份。 除了原生备份方法外,知识库还实现了逻辑数据导入和导出例程。 通过使用非阻塞 SCAN 命令以 20 个元素的批次迭代 Redis 键空间来实现导出数据。
while True:
cursor, keys = conn.scan(cursor, match='keybase*', count=20, _type="HASH")
for key in keys:
hash = conn.hgetall(key)
# Do something with the data
# ...
if (cursor==0): # Exit condition when the iteration is over
break
此项目是一个概念验证,旨在展示 Redis 用作主要数据库时的功能。 GitHub 存储库中的源代码根据 MIT 许可共享,仅用于演示目的,不得用于生产环境。 但是,可以查阅、克隆和/或派生存储库,并且可以重复使用所有示例,以更好地理解本文中讨论的搜索和索引功能。 我鼓励你这样做。
我开发 Keybase 是为了演示 Redis 如何轻松地替代关系数据库来处理这些类型的 Web 应用程序。 令人惊讶的是,对数据进行建模是多么有益。 哈希数据结构简洁紧凑! 我也很高兴得知 Redis 用于相似性搜索和时间序列的独特功能为标准问题提供了完整的开箱即用解决方案,否则将需要多个专用数据库。 使用 Redis Stack 构建多模型应用程序非常简单!
您可以添加许多其他功能来补充此项目,例如通过多用户草稿、修订和反馈收集来改进创作体验。 该项目还可以与 Slack、Jira、ZenDesk 或任何组织团队合作的平台集成。 可以设计其他功能,例如扫描文档的敏感词、检测断开的链接以及用户审核功能,以将该软件从实用程序级别提升到企业级别。
我邀请您克隆或派生 Keybase 存储库并进行设置。 您可以在本地 Redis Stack 安装(或免费的 Redis Cloud 数据库)以及 Python 环境的上下文中在笔记本电脑上运行它。 希望您玩得开心!

