 Redis 8 来了——而且它是开源的
Redis 8 来了——而且它是开源的

视频

RediSearch 2.0 入门
了解更多

RediSearch 是 Redis 的一个实时二级索引模块,具有全文搜索能力,是 Redis 最成熟且功能丰富的模块之一。它也日益受到欢迎——在过去几个月里,RediSearch Docker 的下载量猛增了 500%!这种飙升的人气促使客户提出了各种有趣的用例,从实时库存管理到临时搜索。
为了延续这一势头,我们现在推出 RediSearch 2.0 的公开预览版,旨在提升开发者体验,并成为 Redisearch 最具扩展性的版本。RediSearch 2.0 支持 Redis 的 Active-Active 地理分布技术,可以在不停机的情况下进行扩展,并包含Redis on Flash 支持(目前为私有预览版)。为了在不影响性能的前提下实现这些目标,我们为 RediSearch 2.0 创建了一个全新的架构——并且成功了:RediSearch 2.0 比 RediSearch 1.6 快 2.4 倍。
在 Redis 数据库中拥有丰富的查询和聚合引擎,能够实现远超缓存的多种新用例。RediSearch 允许您在需要使用复杂查询访问数据的情况下,将 Redis 作为您的主数据库。更棒的是,它保留了 Redis 世界级的速度、可靠性和可扩展性,并且无需您在代码中增加复杂性即可更新和索引数据。
对于 RediSearch 2.0,我们重新设计了索引与数据同步的方式。现在 RediSearch 不再需要通过索引来写入数据(使用 FT.ADD 命令),而是跟随写入哈希(hashes)中的数据并同步进行索引。这一重新架构带来了 API 的几项变化,我们在之前的一篇文章《RediSearch 2.0 达成其第一个里程碑》中对此进行了讨论。
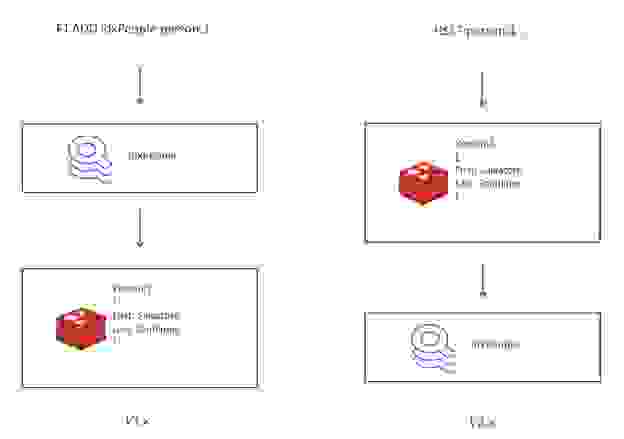
这一新架构带来了两大主要益处。首先,现在在现有数据之上创建二级索引比以往任何时候都更容易。您只需将 RediSearch 添加到现有的 Redis 数据库,创建一个索引,然后就可以开始查询,而无需迁移数据或使用新的命令来添加数据到索引。这极大地降低了新 RediSearch 用户的学习曲线,并允许您在现有 Redis 数据库上创建索引——甚至无需重启数据库。
除了实现新的数据索引方式之外,我们还将索引移出了键空间(keyspace)。这使得 Redis Enterprise 的 Active-Active 技术得以实现,该技术基于无冲突复制数据类型 (CRDTs)。 无冲突地合并两个倒排索引是困难的,但 Redis 已经有一个经过验证的哈希(Hashes)CRDTs 实现。因此,这一新架构的第二个重要益处是使 RediSearch 2.0 更具扩展性。由于 RediSearch 现在跟随哈希(Hashes),并且索引已被移出键空间,您现在可以在 Active-Active 地理分布式数据库中运行 RediSearch。
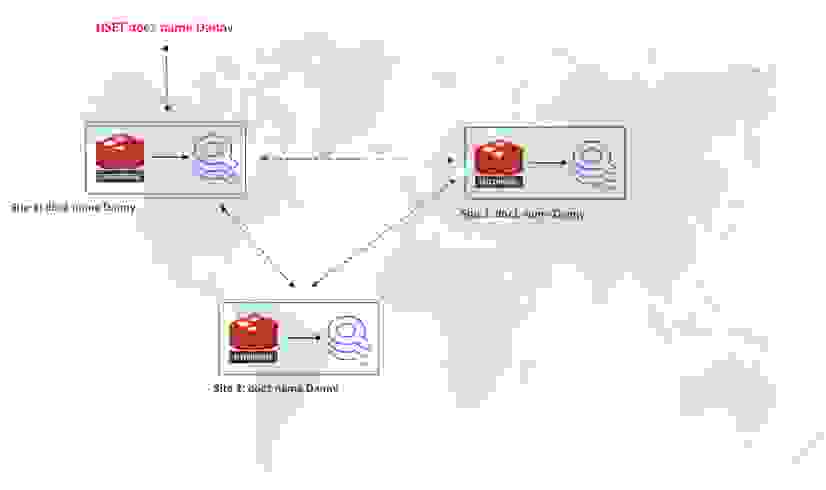
文档将以强最终一致的方式复制到复制集中的所有数据库。在每个副本中,RediSearch 将简单地跟随哈希(Hashes)上的所有更新,这意味着所有索引也都是强最终一致的。
我们不想将提高扩展能力的范围仅限于 Redis Enterprise 用户,因此我们添加了使用开源 Redis 集群 API 在多个分片上扩展单个索引的支持。以前,单个 RediSearch 索引及其文档必须驻留在单个分片上。这意味着开源 Redis 的数据集大小和吞吐量受限于单个 Redis 进程的处理能力。Redis Enterprise 提供了在集群数据库中分发文档并在查询时聚合结果的能力。这种扇出(fan-out)和聚合由一个名为“协调器”(coordinator)的组件处理,该组件现在也在 Redis Source Available License 下公开可用,因此它可以与开源 Redis 集群以及 Redis Enterprise 配合使用。最终成果是迄今为止最具扩展性的 RediSearch 版本。
为了评估 RediSearch 2.0 的写入性能,我们在我们的全文搜索基准测试 (FTSB) 套件中增加了公开可用的 NYC 出租车数据集。该数据集因其丰富的数据类型集(文本、标签、地理位置和数值)和大量文档而在整个行业中使用。
该基准测试侧重于写入性能,使用纽约市黄色出租车的行程记录数据。特别是对于本次基准测试,我们使用了 2015 年 1 月的数据集,该数据集加载了超过 1200 万个文档,平均每个文档大小为 500 字节。有关完整的基准测试规范,请参阅 GitHub 上的 FTSB。
所有基准测试变体均在 Amazon Web Services 实例上运行,这些实例是通过我们的基准测试基础设施配置的。测试在具有 15 个分片的 3 节点集群上执行,使用了 RediSearch Enterprise 1.6 和 2.0 版本。基准测试客户端和包含启用 RediSearch 的数据库的 3 个节点均在独立的 c5.9xlarge 实例上运行。
考虑到 RediSearch 2.0 具备跟随 Redis 中哈希(Hashes)变化并自动索引它们的能力,我们添加了 FT.ADD 和 HSET 命令的变体。为了简化升级,我们在 RediSearch 2.0 中将现在已废弃的 FT.ADD 命令重新映射到 HSET 命令。下面的两个图表显示了 RediSearch 1.6 和 RediSearch 2.0 的总体写入速率和延迟,同时保持亚毫秒级延迟。
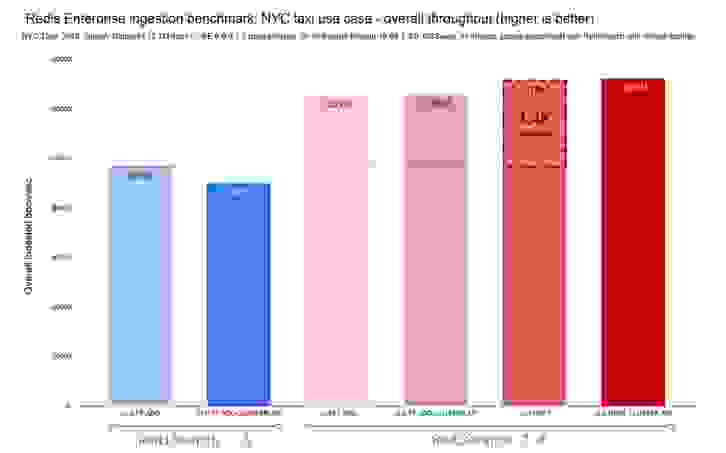
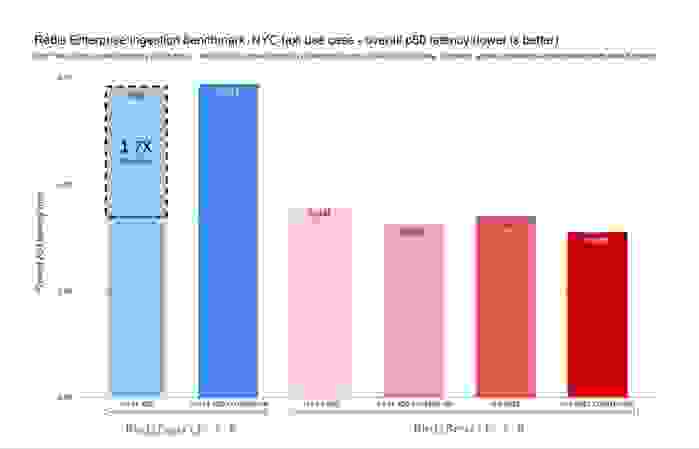
RediSearch 一直很快,但随着这次架构变革,我们将索引速度从每秒 9.6 万个文档提升到每秒 13.2 万个文档,总体 p50 写入延迟为 0.4 毫秒,极大地提升了写入扩展能力。
您不仅将受益于吞吐量的提升,每次写入也会变得更快。除了由于架构变化带来的整体写入改进之外,您现在还可以依靠 OSS Redis Cluster API 的能力来线性扩展您的搜索数据库的写入。
结合吞吐量和延迟的改进,RediSearch 2.0 的速度比 RediSearch 1.6 提高了多达 2.4 倍。
总而言之,RediSearch 2.0 是我们发布过的面向所有 Redis 用户最快、最具扩展性的版本。此外,RediSearch 2.0 的新架构以无缝的方式改进了为 Redis 中现有数据创建索引的开发者体验,并且无需将您的 Redis 数据迁移到另一个启用 RediSearch 的数据库。这一新架构允许 RediSearch 跟随并自动索引其他数据结构,例如 Streams 或 Strings。在即将发布的版本中,它将允许您使用更多数据结构,例如 RedisJSON 中的嵌套数据结构。
我们计划继续添加更多功能,以进一步增强开发者体验。接下来,请期待一个新的命令,它允许您对搜索查询进行性能分析,以便更好地了解查询执行过程中性能瓶颈出现在哪里。
准备好开始了吗?请查阅 Tug Grall 关于《RediSearch 2.0 入门》的博客!然后按照 GitHub 上的这份教程中的步骤操作,或者在 Redis Enterprise Cloud Essentials 中创建一个免费数据库。(请注意,RediSearch 2.0 的公开预览版目前在两个 Redis Enterprise Cloud Essentials 区域可用:孟买和俄勒冈。)

