 Redis 8 来了——而且它是开源的
Redis 8 来了——而且它是开源的
了解更多


随着现代关键任务应用越来越多地融入机器学习技术,它们面临着一些令人惊讶的复杂挑战。这些挑战主要围绕应对实时模型服务需求以及监控这些新功能对最终用户的影响。
我们很高兴宣布 Redis 的 AI 服务引擎 RedisAI 现已普遍可用。RedisAI 的构建基于两个核心目标:
RedisAI 旨在在数据所在之处运行,从而降低延迟并提高简便性,其用例广泛,从交易评分、欺诈检测到推荐引擎个性化等。有关常见用例和何时应用它的更多信息,请参阅RedisAI 产品页面。
这篇博客旨在帮助开发者和架构师深入了解 RedisAI 的内部原理,并学习它如何解决上述目标。我们将深入探讨其架构,并分享我们针对一个突出的实际 AI 问题——金融交易的实时欺诈检测——建立的基准测试。这些基准测试表明,当总体端到端时间不受推理本身主导时,RedisAI 相较于其他模型服务平台,速度提升高达 81 倍。
大多数人工智能 (AI) 框架都附带用于执行其开发模型的运行时,而服务这些模型的常见做法是围绕它们构建一个简单的服务器。由于 RedisAI 作为 Redis 模块实现,它自动受益于服务器的能力,包括 Redis 的原生数据类型和强大的客户端生态系统,以及其持久性和集群功能,更不用说 Redis 模块提供的灵活性以及经验证的 Redis Enterprise 支持带来的安心。当然,还有 Redis 的 高可用性 (99.999%) 和 无限线性可扩展性。
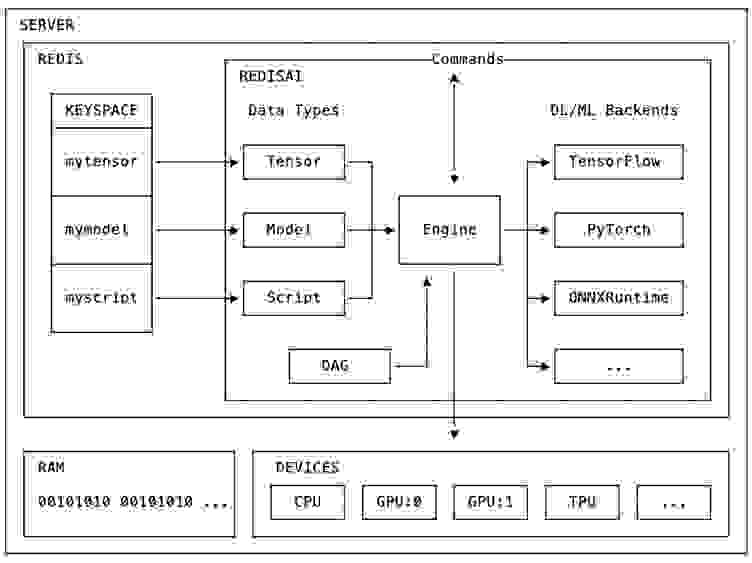
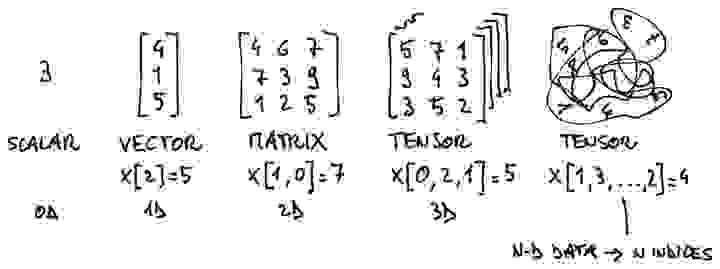
由于 Redis 是一个可扩展的内存数据结构服务器,RedisAI 使用它来存储其机器学习 (ML) 原生数据类型。RedisAI 支持的主要数据类型是张量 (tensor),它是 ML 数据的常见表示形式。
此外,RedisAI 增加了模型和脚本两种数据结构,用于实现模型运行时功能。模型表示由受支持的深度学习 (DL) 或机器学习框架后端构建的计算图,并设置了关于应在哪种设备上运行(CPU 或 GPU)以及特定于后端的参数信息。RedisAI 集成了多个后端,包括 TensorFlow、PyTorch 和 ONNXRuntime。

脚本可以在 CPU 和 GPU 上运行,并允许您通过 TorchScript(一种类似于 Python 的张量操作领域特定语言 (DSL))来操作张量。这使您可以在执行模型之前对输入数据进行预处理,并对结果进行后处理,例如通过模型集成 (ensembling) 来提高性能。
由于张量存储在 Redis 服务器的内存空间中,因此 DL/ML 后端库和脚本可以轻松访问它们,且延迟极低。这种数据局部性使得 RedisAI 在服务模型时能够提供最佳性能。这也使其成为在生产环境中部署 DL/ML 模型并允许任何应用使用它们的完美选择。
重要的是,这种架构不与单个后端绑定,这使得您可以将后端选择(通常由数据科学家做出决定)与使用这些模型提供功能的应用服务解耦。切换模型(即使模型是在不同后端创建的)就像在 Redis 中设置一个新键一样简单。
RedisAI 的其他重要特性包括其 自动批处理 (auto-batching) 支持和 DAG 命令(如 有向无环图 (direct acyclic graph))。通过自动批处理,来自多个客户端的请求可以自动且透明地批处理到单个请求中,以提高服务期间的 CPU/GPU 效率。新的 AI.DAGRUN 命令支持在单个执行过程中规定其他 RedisAI 命令的组合,在此过程中不会将中间键具体化到 Redis 中。
为了对 RedisAI 进行基准测试,我们创建了一个 基准测试套件 (benchmark suite),其中包括基于 Kaggle 数据集并扩展了参考数据的欺诈检测用例。此用例旨在基于匿名的信用卡交易和参考数据来检测欺诈性交易。
我们使用此基准测试来比较四种不同的 AI 服务解决方案
我们希望以公正的方式涵盖所有解决方案,帮助潜在用户针对有或无数据局部性的情况,就最适合其需求的解决方案做出明智的决定。
阅读附录中关于优化的更多信息。
查看附录
在此基础上,我们希望减少参考数据在此次基准测试中的影响,以便它设定 RedisAI 可能达到的下限,具体方法如下:
不同解决方案的基准延迟比较
第一个测试比较了没有参考数据的单客户端性能解决方案。此基准测试中的所有服务解决方案本质上都是围绕其核心库的服务包装器。设置和数据流如下所示

下表显示了在基准测试客户端上测量的端到端推理时间。此测试设定了基准。它表明,与其他服务解决方案相比,RedisAI 在运行模型时不会引入任何开销。在某些情况下,它甚至更优化,这主要是由于所选择的编程语言(RedisAI 用 C/C++ 编写,TensorFlow Serving 用 C++ 编写,TorchServe 用 Java 编写,而常见的 REST API 服务器用 Python 编写)。

参考数据对延迟的影响
既然我们已经设定了基准,接下来看看当模型需要 1KB 参考数据时,延迟会受到什么影响。对于 TensorFlow Serving、TorchServe 和 Gunicorn,参考数据将驻留在不同的主机上。
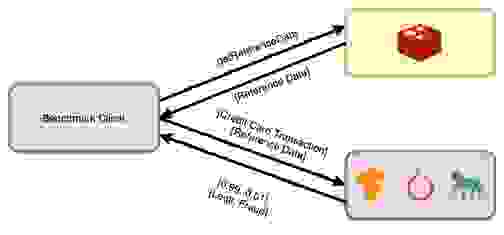
如上所述,对于 RedisAI,参考数据已作为张量驻留在 Redis 中。这就是为什么设置更简单

下表记录了第二次测试的结果,并显示,在单客户端性能涉及参考数据时,RedisAI 将端到端推理延迟降低了高达 8 倍,优于其他模型服务解决方案。同时,q99 数据表明,RedisAI 提供的解决方案比其他任何解决方案都要稳定得多:
这些解决方案如何处理扩展?
分析完单客户端性能后,接下来的问题是这些解决方案如何在高度并发场景下进行扩展?我们设计了第三个测试,将客户端数量从 16 个变化到 160 个,每次增加 16 个客户端。
对于包含 100 万个不同信用卡交易的数据集,普通 HTTP 服务器解决方案的限制约为每秒 2.1 万次完整推理循环,TensorFlow Serving 约为每秒 4 万次完整推理循环,TorchServe 约为每秒 5 万次完整推理循环,而 RedisAI 约为每秒 19.2 万次完整推理循环。
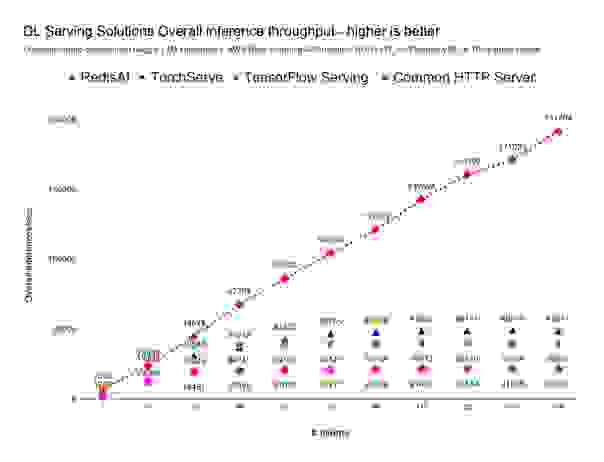
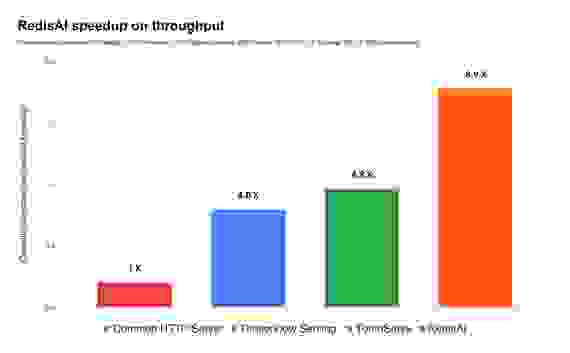
在相同的硬件和基于相同模型进行服务的情况下,RedisAI 处理的推理次数是 TensorFlow Serving 的 4.8 倍,是 TorchServe 的 4 倍,是常见 Web API 的 9 倍,如下所示:
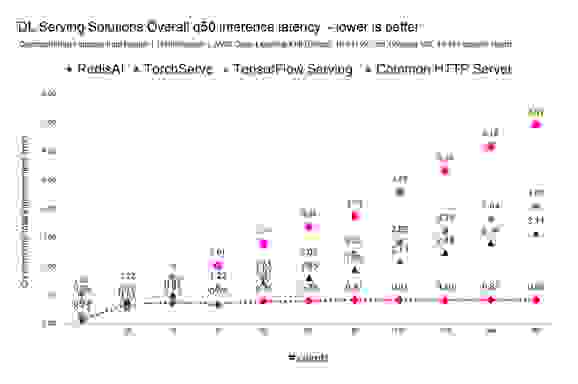
考虑到每种不同模型服务解决方案的最佳结果,请注意,当其他模型服务器在大约每秒 5 万次推理时负载过重,而 RedisAI 在高达每秒 19 万次推理时仍保持稳定且稳定的亚毫秒级延迟,并且无需向集群添加额外的虚拟机,如下表所示
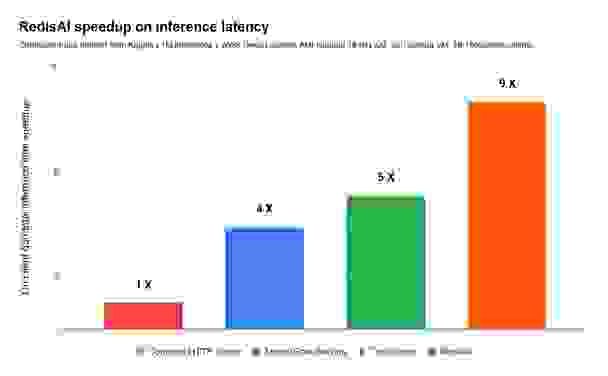
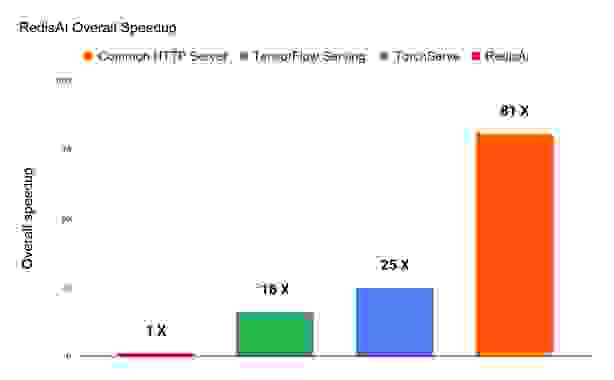
如果将吞吐量和推理延迟的加速因子联系起来,RedisAI 相较于 TorchServe 总体加速 16 倍,相较于 TensorFlow Serving 总体加速 25 倍,相较于普通 HTTP 服务器总体加速 81 倍。这意味着在相同的基础硬件上,RedisAI 在服务总计 100 万次推理时效率可提高 81 倍,如下图所示
基准测试分析
这项初步基准测试表明,数据局部性在基准测试和任何实际 AI 解决方案中都产生了巨大的影响。
请注意,在此基准测试中,参考数据的影响已被大大降低,并且如前所述,仅设定了可能达到的下限。
我们计划增强我们的基准测试,并创建更多符合现代和传统部署的设置,以便您可以轻松了解应用架构的潜在加速效果。
最后,如前图所示,对于高负载/高并发用例,RedisAI 无可匹敌,因为在并发增加时,只有 Redis 是唯一能保持亚毫秒级延迟以及稳定和状态结果的模型服务器。
RedisAI 取得这些令人瞩目的成果,主要是因为它从一开始就是为高性能而构建的。它无缝集成到 Redis 中,利用 Redis 的核心特性进行扩展,同时避免了 Redis 已经解决的常见高负载/高并发工作负载瓶颈。
RedisAI 快速、稳定并支持多种后端——我们也在不断努力增强其功能。(在接下来的博客中,我们计划重点介绍如何利用对 ML-flow 的支持来部署模型,以及如何在生产环境中监控模型。)RedisAI 表明我们可以在 Redis 之上构建一个功能丰富、高性能的模型服务器。我们期待您的反馈,因此请随时通过 GitHub 或新的 RedisAI 社区论坛 与我们联系或发表评论。

